 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023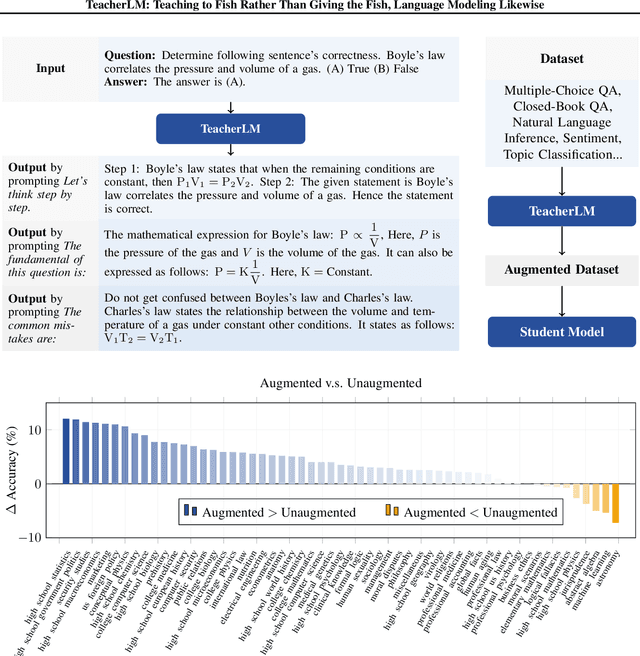

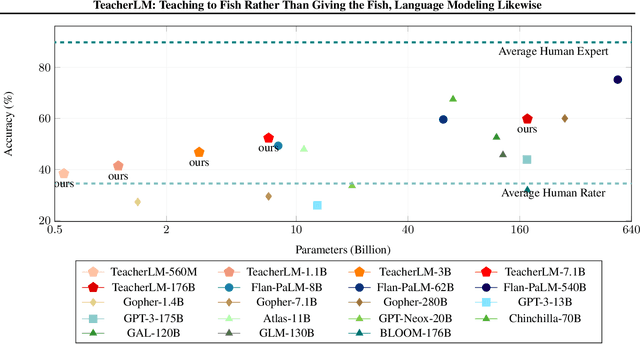

Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification
Aug 15, 2023



Recent progress in large language models (LLMs) like GPT-4 and PaLM-2 has brought significant advancements in addressing math reasoning problems. In particular, OpenAI's latest version of GPT-4, known as GPT-4 Code Interpreter, shows remarkable performance on challenging math datasets. In this paper, we explore the effect of code on enhancing LLMs' reasoning capability by introducing different constraints on the \textit{Code Usage Frequency} of GPT-4 Code Interpreter. We found that its success can be largely attributed to its powerful skills in generating and executing code, evaluating the output of code execution, and rectifying its solution when receiving unreasonable outputs. Based on this insight, we propose a novel and effective prompting method, explicit \uline{c}ode-based \uline{s}elf-\uline{v}erification~(CSV), to further boost the mathematical reasoning potential of GPT-4 Code Interpreter. This method employs a zero-shot prompt on GPT-4 Code Interpreter to encourage it to use code to self-verify its answers. In instances where the verification state registers as ``False'', the model shall automatically amend its solution, analogous to our approach of rectifying errors during a mathematics examination. Furthermore, we recognize that the states of the verification result indicate the confidence of a solution, which can improve the effectiveness of majority voting. With GPT-4 Code Interpreter and CSV, we achieve an impressive zero-shot accuracy on MATH dataset \textbf{(53.9\% $\to$ 84.3\%)}.
Learning Locality and Isotropy in Dialogue Modeling
May 29, 2022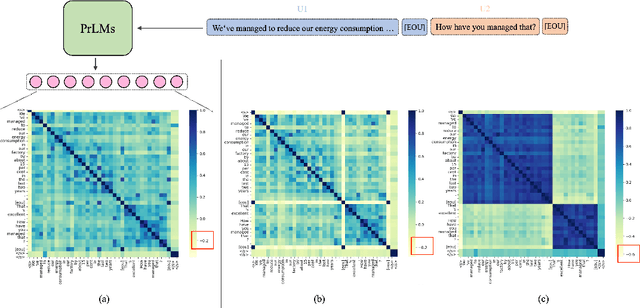
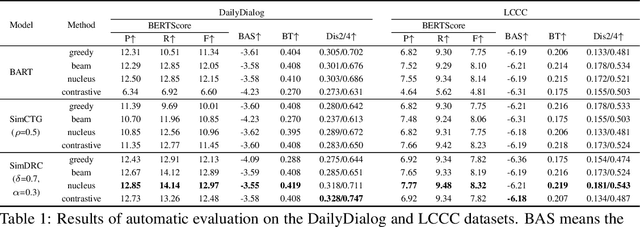
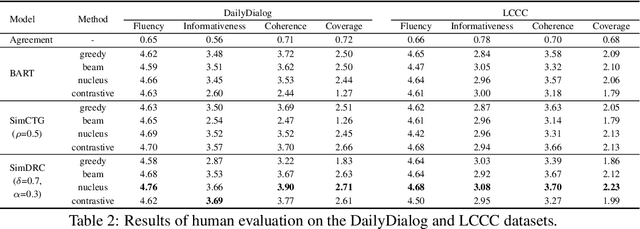
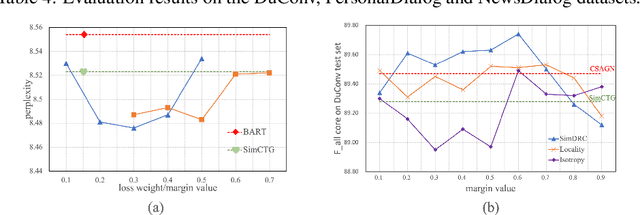
Existing dialogue modeling methods have achieved promising performance on various dialogue tasks with the aid of Transformer and the large-scale pre-trained language models. However, some recent studies revealed that the context representations produced by these methods suffer the problem of anisotropy. In this paper, we find that the generated representations are also not conversational, losing the conversation structure information during the context modeling stage. To this end, we identify two properties in dialogue modeling, i.e., locality and isotropy, and present a simple method for dialogue representation calibration, namely SimDRC, to build isotropic and conversational feature spaces. Experimental results show that our approach significantly outperforms the current state-of-the-art models on three dialogue tasks across the automatic and human evaluation metrics. More in-depth analyses further confirm the effectiveness of our proposed approach.
Learning in School: Multi-teacher Knowledge Inversion for Data-Free Quantization
Nov 19, 2020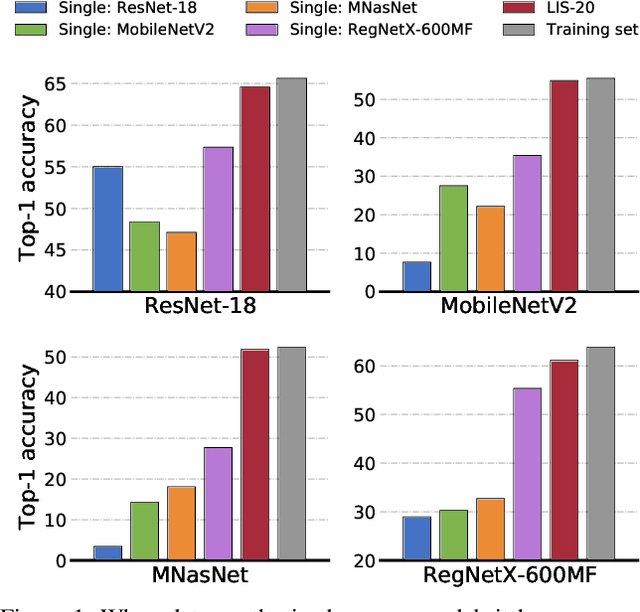
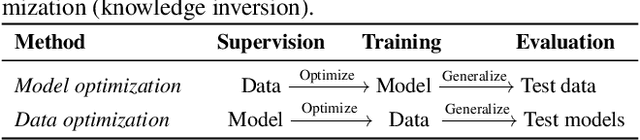
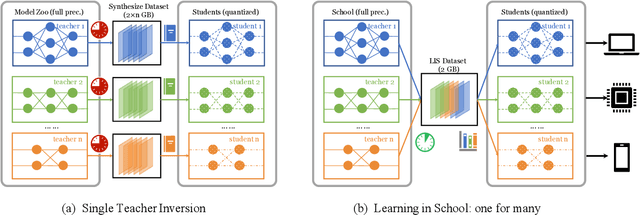
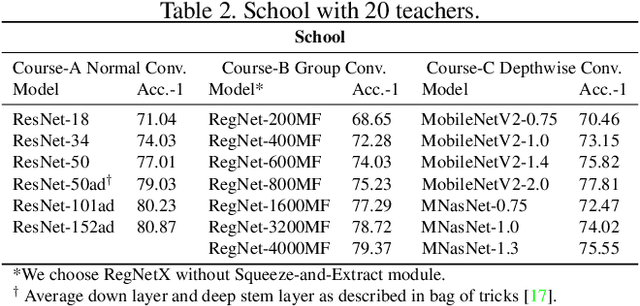
User data confidentiality protection is becoming a rising challenge in the present deep learning research. In that case, data-free quantization has emerged as a promising method to conduct model compression without the need for user data. With no access to data, model quantization naturally becomes less resilient and faces a higher risk of performance degradation. Prior works propose to distill fake images by matching the activation distribution given a specific pre-trained model. However, this fake data cannot be applied to other models easily and is optimized by an invariant objective, resulting in the lack of generalizability and diversity whereas these properties can be found in the natural image dataset. To address these problems, we propose Learning in School~(LIS) algorithm, capable to generate the images suitable for all models by inverting the knowledge in multiple teachers. We further introduce a decentralized training strategy by sampling teachers from hierarchical courses to simultaneously maintain the diversity of generated images. LIS data is highly diverse, not model-specific and only requires one-time synthesis to generalize multiple models and applications. Extensive experiments prove that LIS images resemble natural images with high quality and high fidelity. On data-free quantization, our LIS method significantly surpasses the existing model-specific methods. In particular, LIS data is effective in both post-training quantization and quantization-aware training on the ImageNet dataset and achieves up to 33\% top-1 accuracy uplift compared with existing methods.