 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in School: Multi-teacher Knowledge Inversion for Data-Free Quantization
Paper and Code
Nov 19, 2020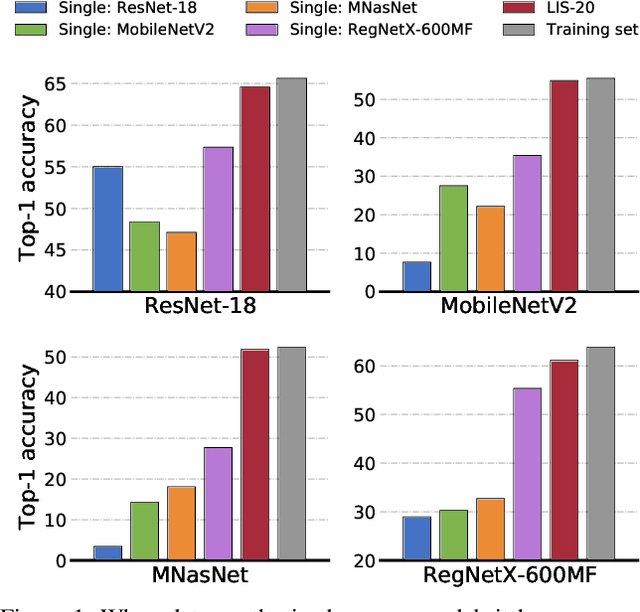
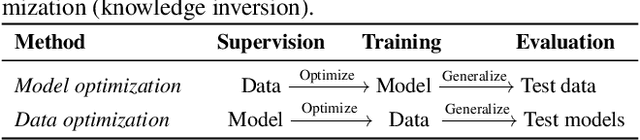
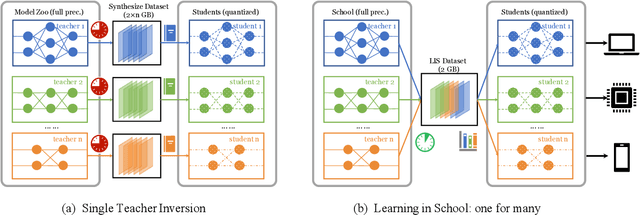
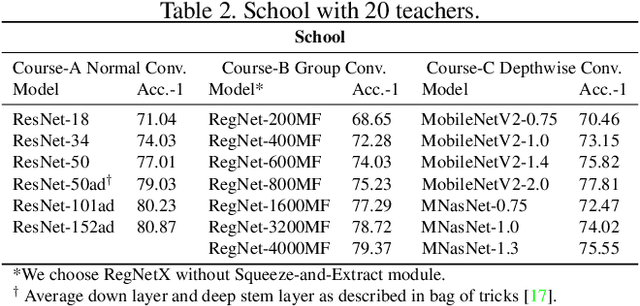
User data confidentiality protection is becoming a rising challenge in the present deep learning research. In that case, data-free quantization has emerged as a promising method to conduct model compression without the need for user data. With no access to data, model quantization naturally becomes less resilient and faces a higher risk of performance degradation. Prior works propose to distill fake images by matching the activation distribution given a specific pre-trained model. However, this fake data cannot be applied to other models easily and is optimized by an invariant objective, resulting in the lack of generalizability and diversity whereas these properties can be found in the natural image dataset. To address these problems, we propose Learning in School~(LIS) algorithm, capable to generate the images suitable for all models by inverting the knowledge in multiple teachers. We further introduce a decentralized training strategy by sampling teachers from hierarchical courses to simultaneously maintain the diversity of generated images. LIS data is highly diverse, not model-specific and only requires one-time synthesis to generalize multiple models and applications. Extensive experiments prove that LIS images resemble natural images with high quality and high fidelity. On data-free quantization, our LIS method significantly surpasses the existing model-specific methods. In particular, LIS data is effective in both post-training quantization and quantization-aware training on the ImageNet dataset and achieves up to 33\% top-1 accuracy uplift compared with existing methods.