 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
May 09, 2024



Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023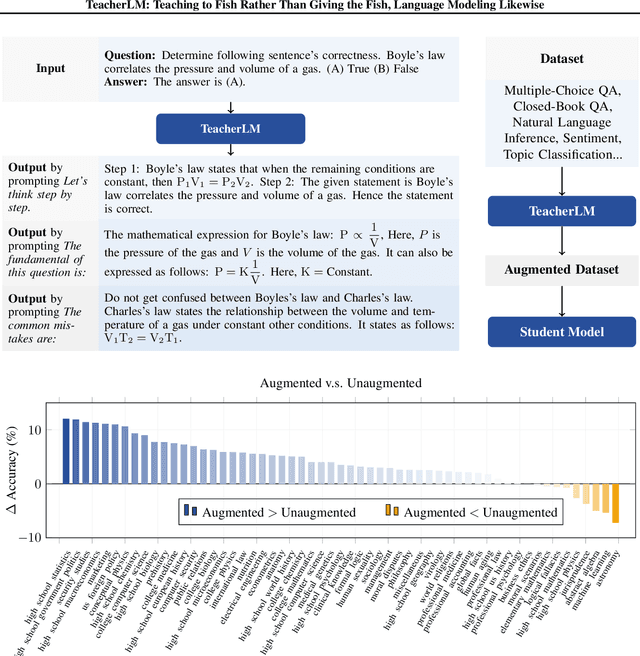

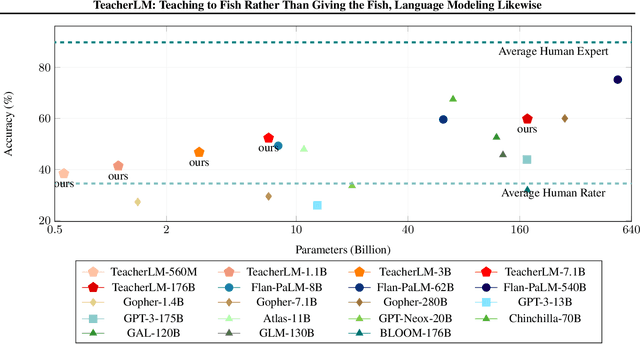

Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
SysNoise: Exploring and Benchmarking Training-Deployment System Inconsistency
Jul 01, 2023Extensive studies have shown that deep learning models are vulnerable to adversarial and natural noises, yet little is known about model robustness on noises caused by different system implementations. In this paper, we for the first time introduce SysNoise, a frequently occurred but often overlooked noise in the deep learning training-deployment cycle. In particular, SysNoise happens when the source training system switches to a disparate target system in deployments, where various tiny system mismatch adds up to a non-negligible difference. We first identify and classify SysNoise into three categories based on the inference stage; we then build a holistic benchmark to quantitatively measure the impact of SysNoise on 20+ models, comprehending image classification, object detection, instance segmentation and natural language processing tasks. Our extensive experiments revealed that SysNoise could bring certain impacts on model robustness across different tasks and common mitigations like data augmentation and adversarial training show limited effects on it. Together, our findings open a new research topic and we hope this work will raise research attention to deep learning deployment systems accounting for model performance. We have open-sourced the benchmark and framework at https://modeltc.github.io/systemnoise_web.
* Proceedings of Machine Learning and Systems. 2023 Mar 18
Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling
Apr 18, 2023



Quantization of transformer language models faces significant challenges due to the existence of detrimental outliers in activations. We observe that these outliers are asymmetric and concentrated in specific channels. To address this issue, we propose the Outlier Suppression+ framework. First, we introduce channel-wise shifting and scaling operations to eliminate asymmetric presentation and scale down problematic channels. We demonstrate that these operations can be seamlessly migrated into subsequent modules while maintaining equivalence. Second, we quantitatively analyze the optimal values for shifting and scaling, taking into account both the asymmetric property and quantization errors of weights in the next layer. Our lightweight framework can incur minimal performance degradation under static and standard post-training quantization settings. Comprehensive results across various tasks and models reveal that our approach achieves near-floating-point performance on both small models, such as BERT, and large language models (LLMs) including OPTs, BLOOM, and BLOOMZ at 8-bit and 6-bit settings. Furthermore, we establish a new state of the art for 4-bit BERT.
Cross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
Sep 27, 2022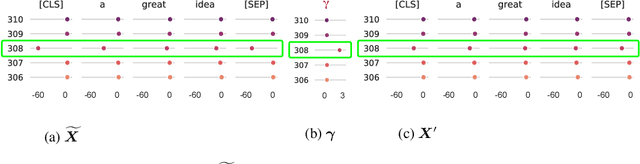

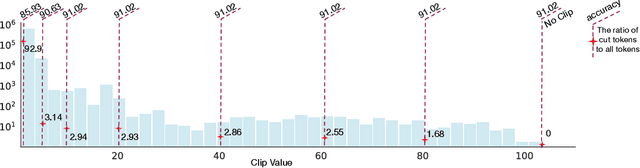

Transformer architecture has become the fundamental element of the widespread natural language processing~(NLP) models. With the trends of large NLP models, the increasing memory and computation costs hinder their efficient deployment on resource-limited devices. Therefore, transformer quantization attracts wide research interest. Recent work recognizes that structured outliers are the critical bottleneck for quantization performance. However, their proposed methods increase the computation overhead and still leave the outliers there. To fundamentally address this problem, this paper delves into the inherent inducement and importance of the outliers. We discover that $\boldsymbol \gamma$ in LayerNorm (LN) acts as a sinful amplifier for the outliers, and the importance of outliers varies greatly where some outliers provided by a few tokens cover a large area but can be clipped sharply without negative impacts. Motivated by these findings, we propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration migrates the outlier amplifier to subsequent modules in an equivalent transformation, contributing to a more quantization-friendly model without any extra burden. The Token-Wise Clipping takes advantage of the large variance of token range and designs a token-wise coarse-to-fine pipeline, obtaining a clipping range with minimal final quantization loss in an efficient way. This framework effectively suppresses the outliers and can be used in a plug-and-play mode. Extensive experiments prove that our framework surpasses the existing works and, for the first time, pushes the 6-bit post-training BERT quantization to the full-precision (FP) level. Our code is available at https://github.com/wimh966/outlier_suppression.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022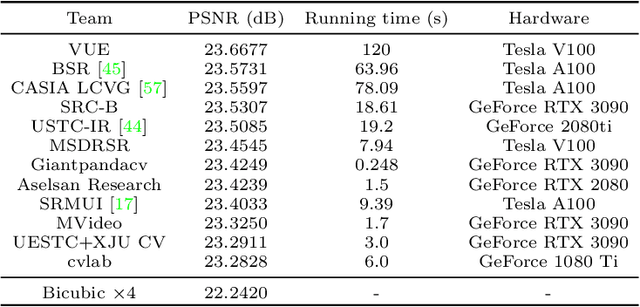

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Self-Calibrated Efficient Transformer for Lightweight Super-Resolution
Apr 19, 2022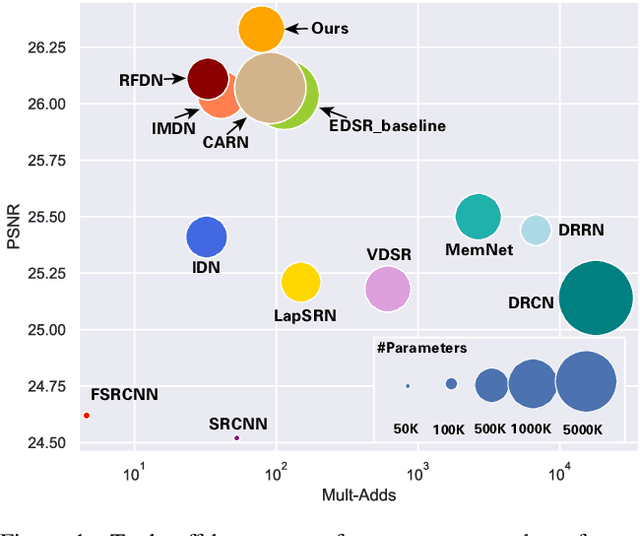
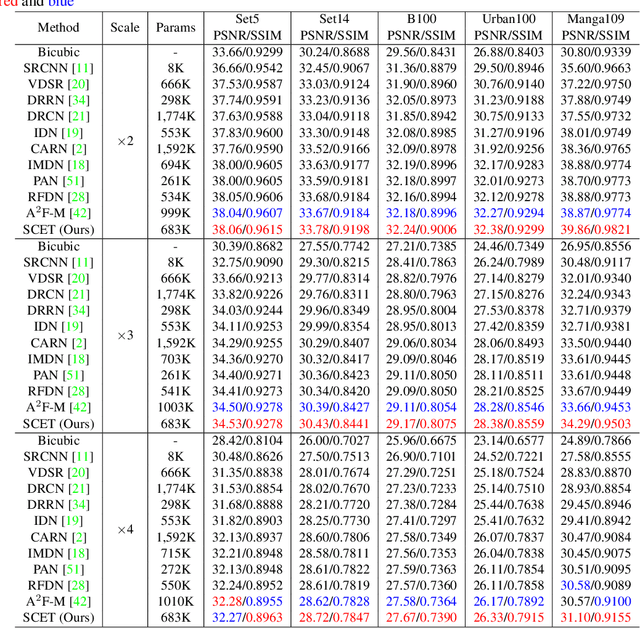
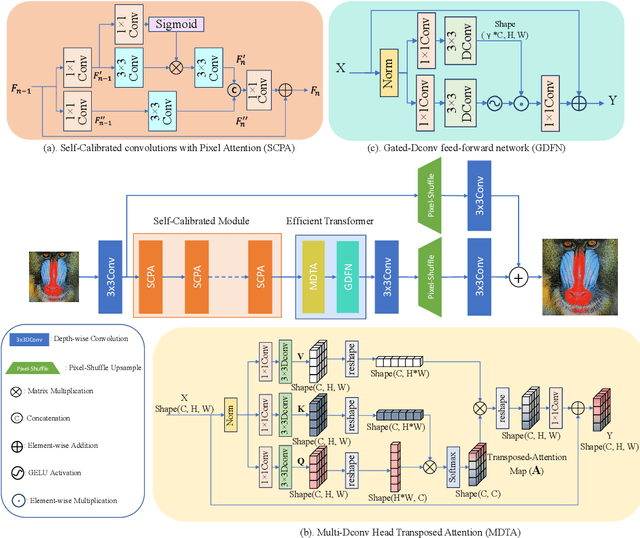
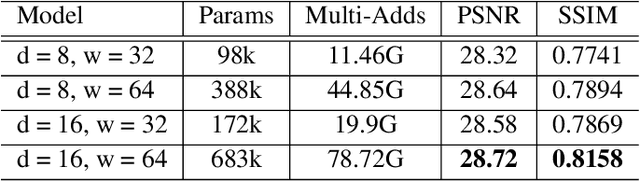
Recently, deep learning has been successfully applied to the single-image super-resolution (SISR) with remarkable performance. However, most existing methods focus on building a more complex network with a large number of layers, which can entail heavy computational costs and memory storage. To address this problem, we present a lightweight Self-Calibrated Efficient Transformer (SCET) network to solve this problem. The architecture of SCET mainly consists of the self-calibrated module and efficient transformer block, where the self-calibrated module adopts the pixel attention mechanism to extract image features effectively. To further exploit the contextual information from features, we employ an efficient transformer to help the network obtain similar features over long distances and thus recover sufficient texture details. We provide comprehensive results on different settings of the overall network. Our proposed method achieves more remarkable performance than baseline methods. The source code and pre-trained models are available at https://github.com/AlexZou14/SCET.
Mutual Learning for Domain Adaptation: Self-distillation Image Dehazing Network with Sample-cycle
Mar 17, 2022

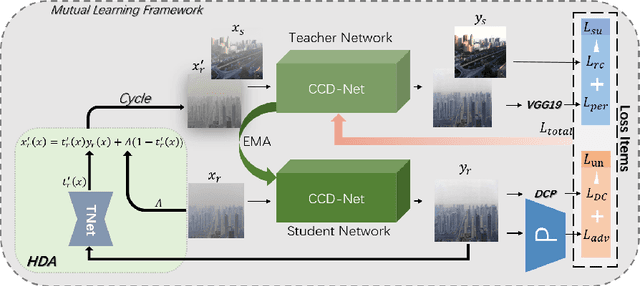

Deep learning-based methods have made significant achievements for image dehazing. However, most of existing dehazing networks are concentrated on training models using simulated hazy images, resulting in generalization performance degradation when applied on real-world hazy images because of domain shift. In this paper, we propose a mutual learning dehazing framework for domain adaption. Specifically, we first devise two siamese networks: a teacher network in the synthetic domain and a student network in the real domain, and then optimize them in a mutual learning manner by leveraging EMA and joint loss. Moreover, we design a sample-cycle strategy based on density augmentation (HDA) module to introduce pseudo real-world image pairs provided by the student network into training for further improving the generalization performance. Extensive experiments on both synthetic and real-world dataset demonstrate that the propose mutual learning framework outperforms state-of-the-art dehazing techniques in terms of subjective and objective evaluation.
Do Prompts Solve NLP Tasks Using Natural Language?
Mar 02, 2022
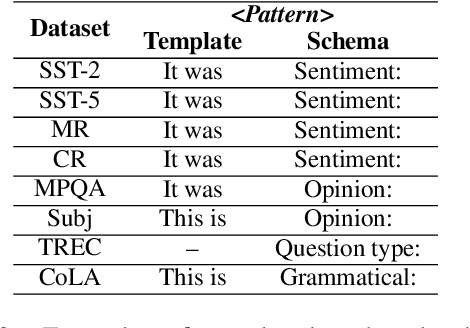

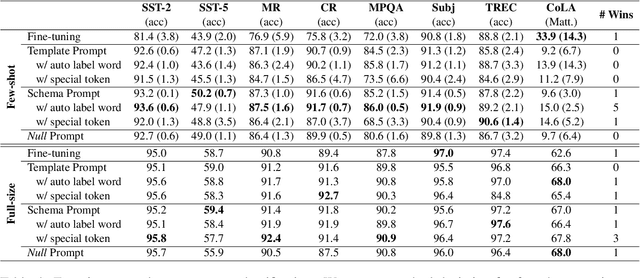
Thanks to the advanced improvement of large pre-trained language models, prompt-based fine-tuning is shown to be effective on a variety of downstream tasks. Though many prompting methods have been investigated, it remains unknown which type of prompts are the most effective among three types of prompts (i.e., human-designed prompts, schema prompts and null prompts). In this work, we empirically compare the three types of prompts under both few-shot and fully-supervised settings. Our experimental results show that schema prompts are the most effective in general. Besides, the performance gaps tend to diminish when the scale of training data grows large.