Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Prompts Solve NLP Tasks Using Natural Language?
Paper and Code
Mar 02, 2022
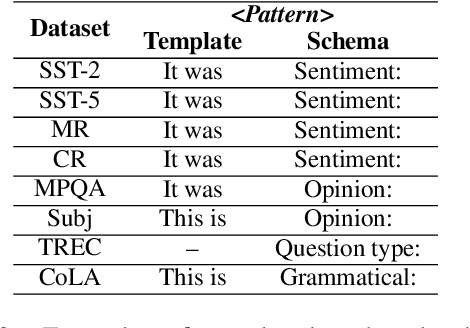

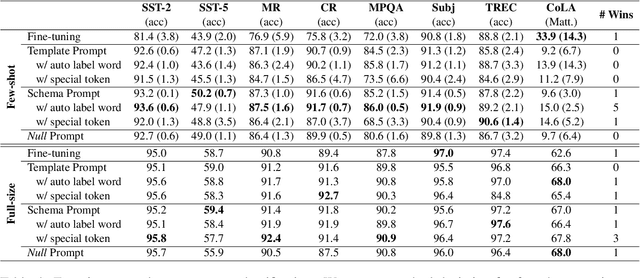
Thanks to the advanced improvement of large pre-trained language models, prompt-based fine-tuning is shown to be effective on a variety of downstream tasks. Though many prompting methods have been investigated, it remains unknown which type of prompts are the most effective among three types of prompts (i.e., human-designed prompts, schema prompts and null prompts). In this work, we empirically compare the three types of prompts under both few-shot and fully-supervised settings. Our experimental results show that schema prompts are the most effective in general. Besides, the performance gaps tend to diminish when the scale of training data grows large.
View paper on