 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGFN: Lightweight Light Field Image Super-Resolution using Local Convolution Modulation and Global Attention Feature Extraction
Sep 26, 2024



Capturing different intensity and directions of light rays at the same scene Light field (LF) can encode the 3D scene cues into a 4D LF image which has a wide range of applications (i.e. post-capture refocusing and depth sensing). LF image super-resolution (SR) aims to improve the image resolution limited by the performance of LF camera sensor. Although existing methods have achieved promising results the practical application of these models is limited because they are not lightweight enough. In this paper we propose a lightweight model named LGFN which integrates the local and global features of different views and the features of different channels for LF image SR. Specifically owing to neighboring regions of the same pixel position in different sub-aperture images exhibit similar structural relationships we design a lightweight CNN-based feature extraction module (namely DGCE) to extract local features better through feature modulation. Meanwhile as the position beyond the boundaries in the LF image presents a large disparity we propose an efficient spatial attention module (namely ESAM) which uses decomposable large-kernel convolution to obtain an enlarged receptive field and an efficient channel attention module (namely ECAM). Compared with the existing LF image SR models with large parameter our model has a parameter of 0.45M and a FLOPs of 19.33G which has achieved a competitive effect. Extensive experiments with ablation studies demonstrate the effectiveness of our proposed method which ranked the second place in the Track 2 Fidelity & Efficiency of NTIRE2024 Light Field Super Resolution Challenge and the seventh place in the Track 1 Fidelity.
* 10 pages, 5 figures
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024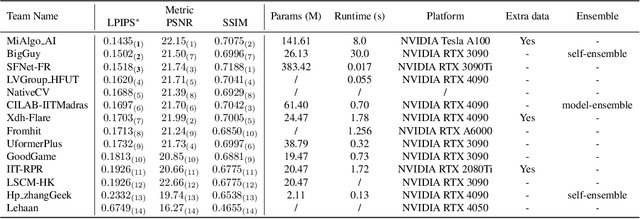
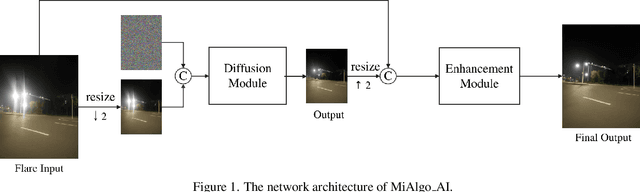
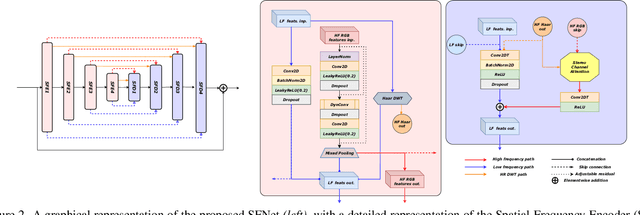
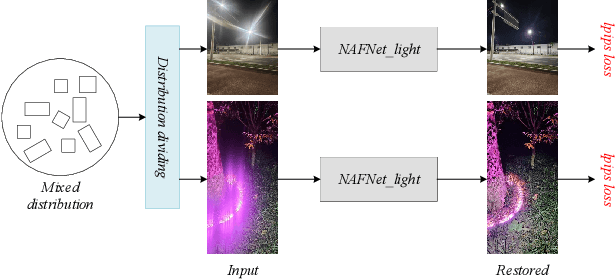
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Cross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.