 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGFN: Lightweight Light Field Image Super-Resolution using Local Convolution Modulation and Global Attention Feature Extraction
Sep 26, 2024



Capturing different intensity and directions of light rays at the same scene Light field (LF) can encode the 3D scene cues into a 4D LF image which has a wide range of applications (i.e. post-capture refocusing and depth sensing). LF image super-resolution (SR) aims to improve the image resolution limited by the performance of LF camera sensor. Although existing methods have achieved promising results the practical application of these models is limited because they are not lightweight enough. In this paper we propose a lightweight model named LGFN which integrates the local and global features of different views and the features of different channels for LF image SR. Specifically owing to neighboring regions of the same pixel position in different sub-aperture images exhibit similar structural relationships we design a lightweight CNN-based feature extraction module (namely DGCE) to extract local features better through feature modulation. Meanwhile as the position beyond the boundaries in the LF image presents a large disparity we propose an efficient spatial attention module (namely ESAM) which uses decomposable large-kernel convolution to obtain an enlarged receptive field and an efficient channel attention module (namely ECAM). Compared with the existing LF image SR models with large parameter our model has a parameter of 0.45M and a FLOPs of 19.33G which has achieved a competitive effect. Extensive experiments with ablation studies demonstrate the effectiveness of our proposed method which ranked the second place in the Track 2 Fidelity & Efficiency of NTIRE2024 Light Field Super Resolution Challenge and the seventh place in the Track 1 Fidelity.
* 10 pages, 5 figures
Hidden Path Selection Network for Semantic Segmentation of Remote Sensing Images
Dec 09, 2021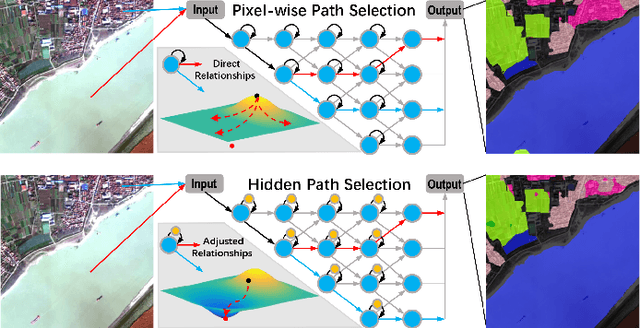
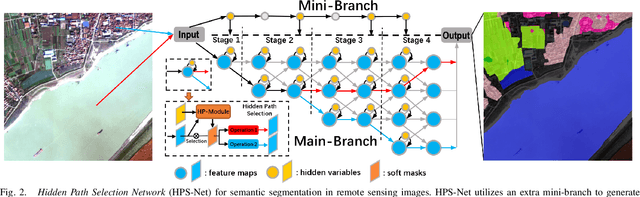
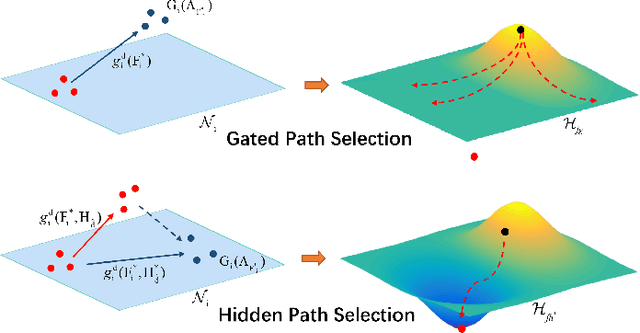
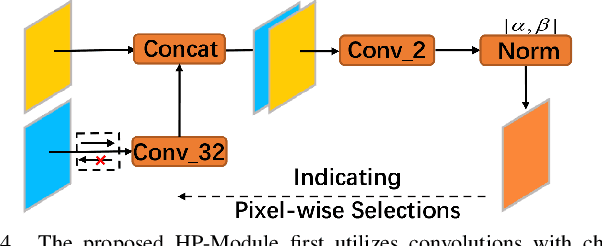
Targeting at depicting land covers with pixel-wise semantic categories, semantic segmentation in remote sensing images needs to portray diverse distributions over vast geographical locations, which is difficult to be achieved by the homogeneous pixel-wise forward paths in the architectures of existing deep models. Although several algorithms have been designed to select pixel-wise adaptive forward paths for natural image analysis, it still lacks theoretical supports on how to obtain optimal selections. In this paper, we provide mathematical analyses in terms of the parameter optimization, which guides us to design a method called Hidden Path Selection Network (HPS-Net). With the help of hidden variables derived from an extra mini-branch, HPS-Net is able to tackle the inherent problem about inaccessible global optimums by adjusting the direct relationships between feature maps and pixel-wise path selections in existing algorithms, which we call hidden path selection. For the better training and evaluation, we further refine and expand the 5-class Gaofen Image Dataset (GID-5) to a new one with 15 land-cover categories, i.e., GID-15. The experimental results on both GID-5 and GID-15 demonstrate that the proposed modules can stably improve the performance of different deep structures, which validates the proposed mathematical analyses.
Asymmetric Siamese Networks for Semantic Change Detection
Oct 12, 2020



Given two multi-temporal aerial images, semantic change detection aims to locate the land-cover variations and identify their categories with pixel-wise boundaries. The problem has demonstrated promising potentials in many earth vision related tasks, such as precise urban planning and natural resource management. Existing state-of-the-art algorithms mainly identify the changed pixels through symmetric modules, which would suffer from categorical ambiguity caused by changes related to totally different land-cover distributions. In this paper, we present an asymmetric siamese network (ASN) to locate and identify semantic changes through feature pairs obtained from modules of widely different structures, which involve different spatial ranges and quantities of parameters to factor in the discrepancy across different land-cover distributions. To better train and evaluate our model, we create a large-scale well-annotated SEmantic Change detectiON Dataset (SECOND), while an adaptive threshold learning (ATL) module and a separated kappa (SeK) coefficient are proposed to alleviate the influences of label imbalance in model training and evaluation. The experimental results demonstrate that the proposed model can stably outperform the state-of-the-art algorithms with different encoder backbones.