 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Principle Kurtosis Analysis
May 20, 2024Independent component analysis (ICA) is a fundamental problem in the field of signal processing, and numerous algorithms have been developed to address this issue. The core principle of these algorithms is to find a transformation matrix that maximizes the non-Gaussianity of the separated signals. Most algorithms typically assume that the source signals are mutually independent (orthogonal to each other), thereby imposing an orthogonal constraint on the transformation matrix. However, this assumption is not always valid in practical scenarios, where the orthogonal constraint can lead to inaccurate results. Recently, tensor-based algorithms have attracted much attention due to their ability to reduce computational complexity and enhance separation performance. In these algorithms, ICA is reformulated as an eigenpair problem of a statistical tensor. Importantly, the eigenpairs of a tensor are not inherently orthogonal, making tensor-based algorithms more suitable for nonorthogonal cases. Despite this advantage, finding exact solutions to the tensor's eigenpair problem remains a challenging task. In this paper, we introduce a non-zero volume constraint and a Riemannian gradient-based algorithm to solve the tensor's eigenpair problem. The proposed algorithm can find exact solutions under nonorthogonal conditions, making it more effective for separating nonorthogonal sources. Additionally, existing tensor-based algorithms typically rely on third-order statistics and are limited to real-valued data. To overcome this limitation, we extend tensor-based algorithms to the complex domain by constructing a fourth-order statistical tensor. Experiments conducted on both synthetic and real-world datasets demonstrate the effectiveness of the proposed algorithm.
Federated Unsupervised Domain Adaptation for Face Recognition
Apr 09, 2022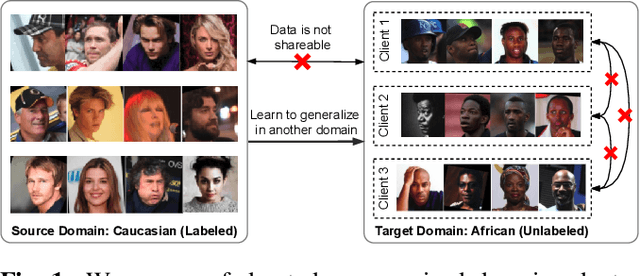

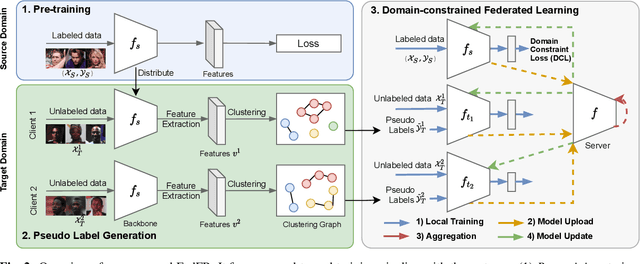
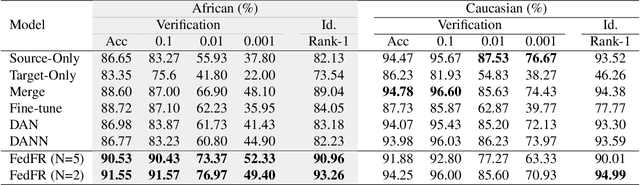
Given labeled data in a source domain, unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, whose data distributions are different. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing of sensitive face images between domains. To address this problem, we propose federated unsupervised domain adaptation for face recognition, FedFR. FedFR jointly optimizes clustering-based domain adaptation and federated learning to elevate performance on the target domain. Specifically, for unlabeled data in the target domain, we enhance a clustering algorithm with distance constrain to improve the quality of predicted pseudo labels. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training in federated learning. Extensive experiments on a newly constructed benchmark demonstrate that FedFR outperforms the baseline and classic methods on the target domain by 3% to 14% on different evaluation metrics.
Towards Unsupervised Domain Adaptation for Deep Face Recognition under Privacy Constraints via Federated Learning
May 17, 2021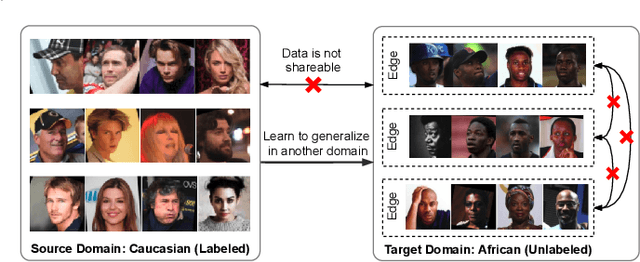

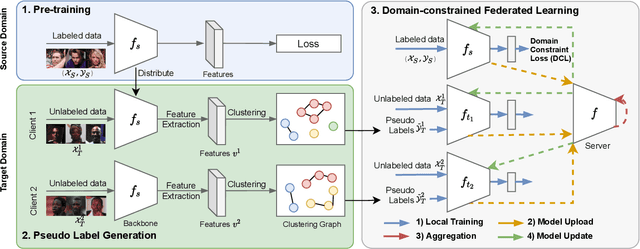
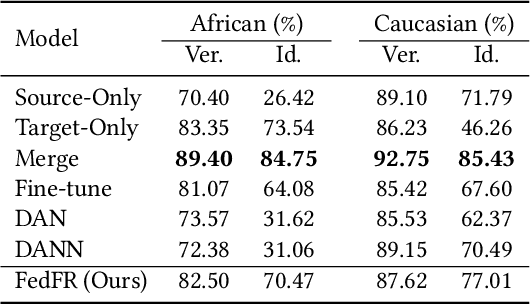
Unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, given labeled data in a source domain, whose data distributions differ from the target domain. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing sensitive face images between two domains. To address this problem, we propose a novel unsupervised federated face recognition approach (FedFR). FedFR improves the performance in the target domain by iteratively aggregating knowledge from the source domain through federated learning. It protects data privacy by transferring models instead of raw data between domains. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training. DCL suppresses the data volume dominance of the source domain. We also enhance a hierarchical clustering algorithm to predict pseudo labels for the unlabeled target domain accurately. To this end, FedFR forms an end-to-end training pipeline: (1) pre-train in the source domain; (2) predict pseudo labels by clustering in the target domain; (3) conduct domain-constrained federated learning across two domains. Extensive experiments and analysis on two newly constructed benchmarks demonstrate the effectiveness of FedFR. It outperforms the baseline and classic methods in the target domain by over 4% on the more realistic benchmark. We believe that FedFR will shed light on applying federated learning to more computer vision tasks under privacy constraints.
Performance Optimization for Federated Person Re-identification via Benchmark Analysis
Aug 26, 2020
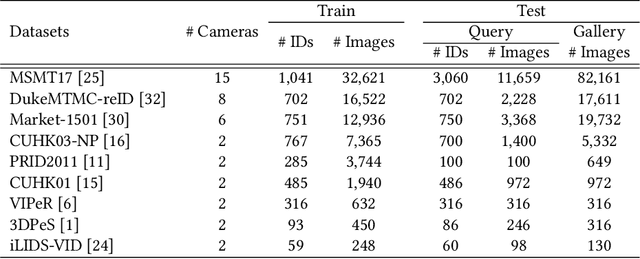
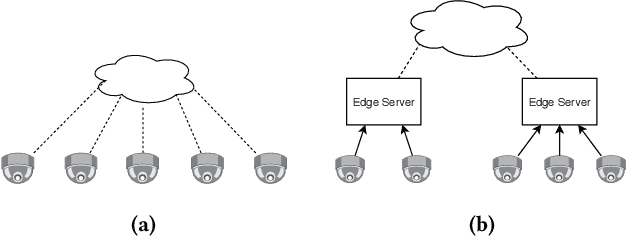
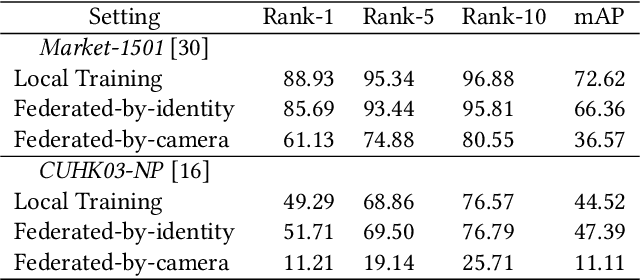
Federated learning is a privacy-preserving machine learning technique that learns a shared model across decentralized clients. It can alleviate privacy concerns of personal re-identification, an important computer vision task. In this work, we implement federated learning to person re-identification (FedReID) and optimize its performance affected by statistical heterogeneity in the real-world scenario. We first construct a new benchmark to investigate the performance of FedReID. This benchmark consists of (1) nine datasets with different volumes sourced from different domains to simulate the heterogeneous situation in reality, (2) two federated scenarios, and (3) an enhanced federated algorithm for FedReID. The benchmark analysis shows that the client-edge-cloud architecture, represented by the federated-by-dataset scenario, has better performance than client-server architecture in FedReID. It also reveals the bottlenecks of FedReID under the real-world scenario, including poor performance of large datasets caused by unbalanced weights in model aggregation and challenges in convergence. Then we propose two optimization methods: (1) To address the unbalanced weight problem, we propose a new method to dynamically change the weights according to the scale of model changes in clients in each training round; (2) To facilitate convergence, we adopt knowledge distillation to refine the server model with knowledge generated from client models on a public dataset. Experiment results demonstrate that our strategies can achieve much better convergence with superior performance on all datasets. We believe that our work will inspire the community to further explore the implementation of federated learning on more computer vision tasks in real-world scenarios.
MagnifierNet: Towards Semantic Regularization and Fusion for Person Re-identification
Feb 26, 2020
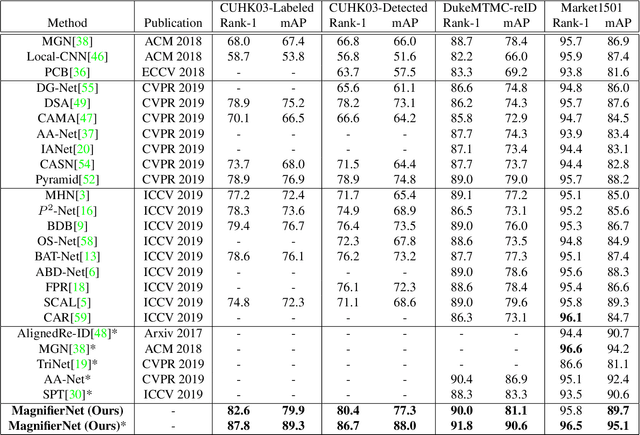
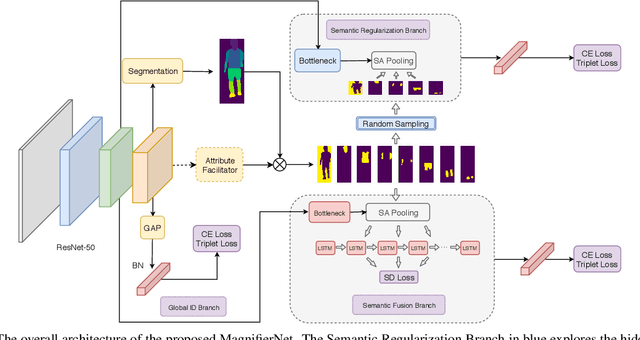
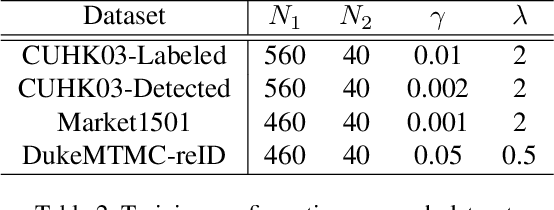
Although person re-identification (ReID) has achieved significant improvement recently by enforcing part alignment, it is still a challenging task when it comes to distinguishing visually similar identities or identifying occluded person. In these scenarios, magnifying details in each part features and selectively fusing them together may provide a feasible solution. In this paper, we propose MagnifierNet, a novel network which accurately mines details for each semantic region and selectively fuse all semantic feature representations. Apart from conventional global branch, our proposed network is composed of a Semantic Regularization Branch (SRB) as learning regularizer and a Semantic Fusion Branch (SFB) towards selectively semantic fusion. The SRB learns with limited number of semantic regions randomly sampled in each batch, which forces the network to learn detailed representation for each semantic region, and the SFB selectively fuses semantic region information in a sequential manner, focusing on beneficial information while neglecting irrelevant features or noises. In addition, we introduce a novel loss function "Semantic Diversity Loss" (SD Loss) to facilitate feature diversity and improves regularization among all semantic regions. State-of-the-art performance has been achieved on multiple datasets by large margins. Notably, we improve SOTA on CUHK03-Labeled Dataset by 12.6% in mAP and 8.9% in Rank-1. We also outperform existing works on CUHK03-Detected Dataset by 13.2% in mAP and 7.8% in Rank-1 respectively, which demonstrates the effectiveness of our method.
EcoNAS: Finding Proxies for Economical Neural Architecture Search
Jan 05, 2020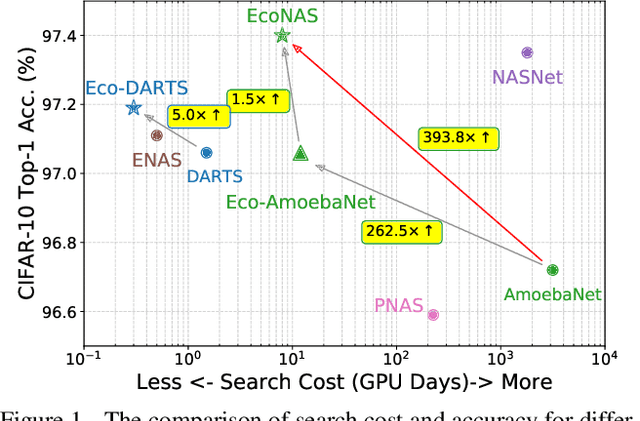
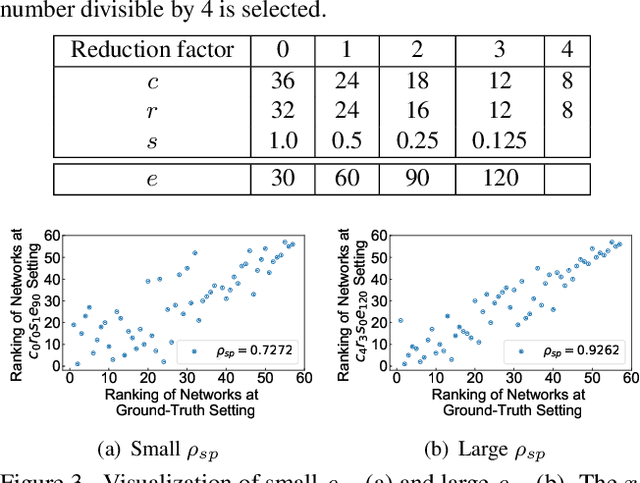
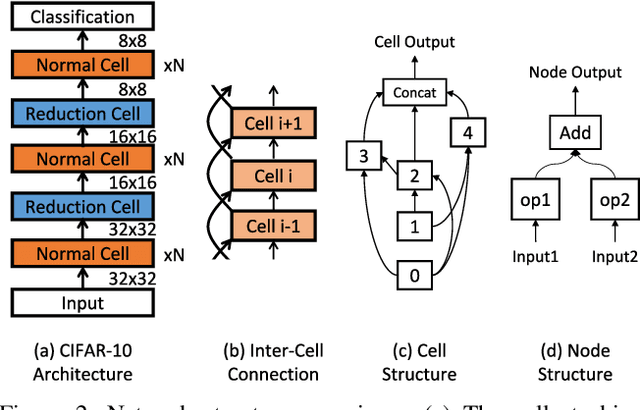
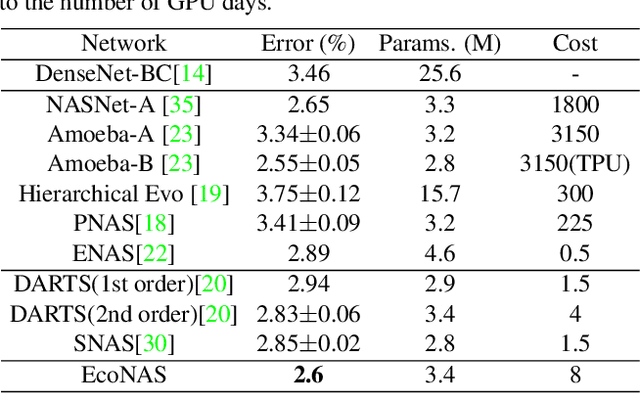
Neural Architecture Search (NAS) achieves significant progress in many computer vision tasks. While many methods have been proposed to improve the efficiency of NAS, the search progress is still laborious because training and evaluating plausible architectures over large search space is time-consuming. Assessing network candidates under a proxy (i.e., computationally reduced setting) thus becomes inevitable. In this paper, we observe that most existing proxies exhibit different behaviors in maintaining the rank consistency among network candidates. In particular, some proxies can be more reliable -- the rank of candidates does not differ much comparing their reduced setting performance and final performance. In this paper, we systematically investigate some widely adopted reduction factors and report our observations. Inspired by these observations, we present a reliable proxy and further formulate a hierarchical proxy strategy. The strategy spends more computations on candidate networks that are potentially more accurate, while discards unpromising ones in early stage with a fast proxy. This leads to an economical evolutionary-based NAS (EcoNAS), which achieves an impressive 400x search time reduction in comparison to the evolutionary-based state of the art (8 vs. 3150 GPU days). Some new proxies led by our observations can also be applied to accelerate other NAS methods while still able to discover good candidate networks with performance matching those found by previous proxy strategies.