 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Principle Kurtosis Analysis
May 20, 2024Independent component analysis (ICA) is a fundamental problem in the field of signal processing, and numerous algorithms have been developed to address this issue. The core principle of these algorithms is to find a transformation matrix that maximizes the non-Gaussianity of the separated signals. Most algorithms typically assume that the source signals are mutually independent (orthogonal to each other), thereby imposing an orthogonal constraint on the transformation matrix. However, this assumption is not always valid in practical scenarios, where the orthogonal constraint can lead to inaccurate results. Recently, tensor-based algorithms have attracted much attention due to their ability to reduce computational complexity and enhance separation performance. In these algorithms, ICA is reformulated as an eigenpair problem of a statistical tensor. Importantly, the eigenpairs of a tensor are not inherently orthogonal, making tensor-based algorithms more suitable for nonorthogonal cases. Despite this advantage, finding exact solutions to the tensor's eigenpair problem remains a challenging task. In this paper, we introduce a non-zero volume constraint and a Riemannian gradient-based algorithm to solve the tensor's eigenpair problem. The proposed algorithm can find exact solutions under nonorthogonal conditions, making it more effective for separating nonorthogonal sources. Additionally, existing tensor-based algorithms typically rely on third-order statistics and are limited to real-valued data. To overcome this limitation, we extend tensor-based algorithms to the complex domain by constructing a fourth-order statistical tensor. Experiments conducted on both synthetic and real-world datasets demonstrate the effectiveness of the proposed algorithm.
Self-Supervised Light Field Depth Estimation Using Epipolar Plane Images
Mar 29, 2022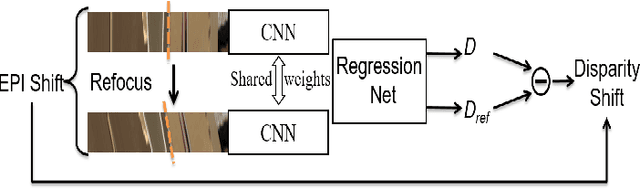
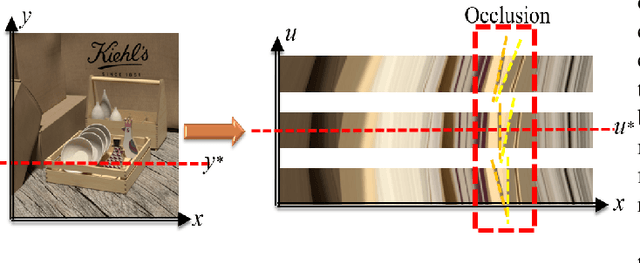
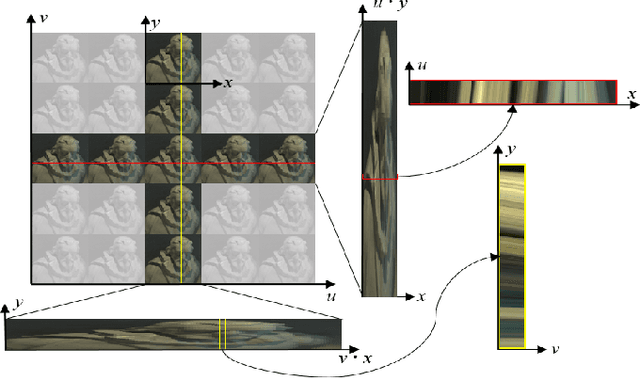
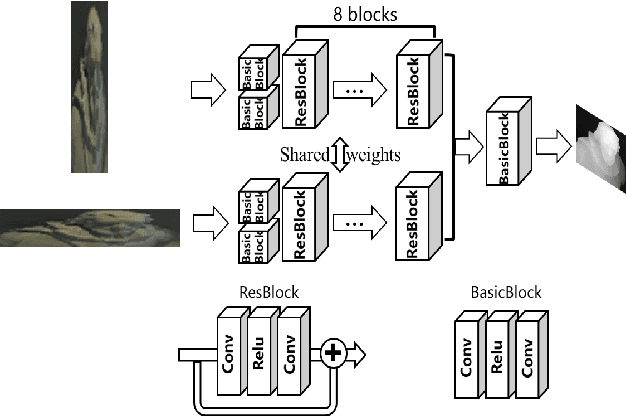
Exploiting light field data makes it possible to obtain dense and accurate depth map. However, synthetic scenes with limited disparity range cannot contain the diversity of real scenes. By training in synthetic data, current learning-based methods do not perform well in real scenes. In this paper, we propose a self-supervised learning framework for light field depth estimation. Different from the existing end-to-end training methods using disparity label per pixel, our approach implements network training by estimating EPI disparity shift after refocusing, which extends the disparity range of epipolar lines. To reduce the sensitivity of EPI to noise, we propose a new input mode called EPI-Stack, which stacks EPIs in the view dimension. This method is less sensitive to noise scenes than traditional input mode and improves the efficiency of estimation. Compared with other state-of-the-art methods, the proposed method can also obtain higher quality results in real-world scenarios, especially in the complex occlusion and depth discontinuity.
Sequence-based Person Attribute Recognition with Joint CTC-Attention Model
Nov 27, 2018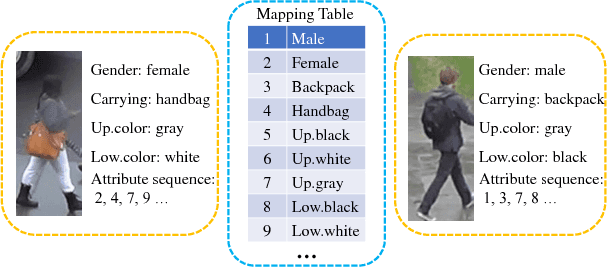
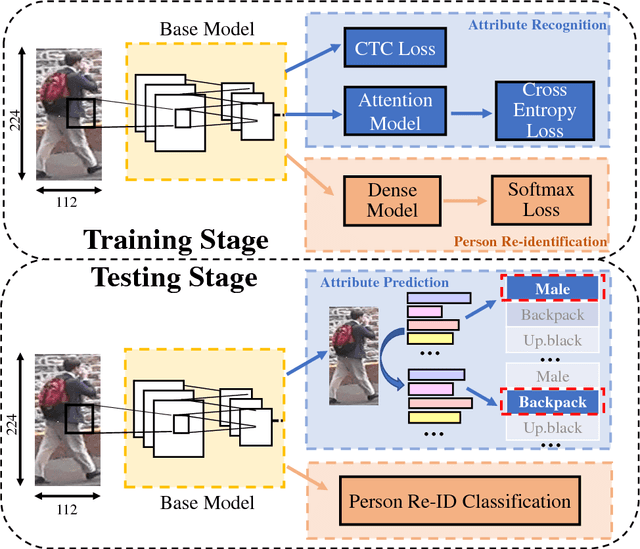
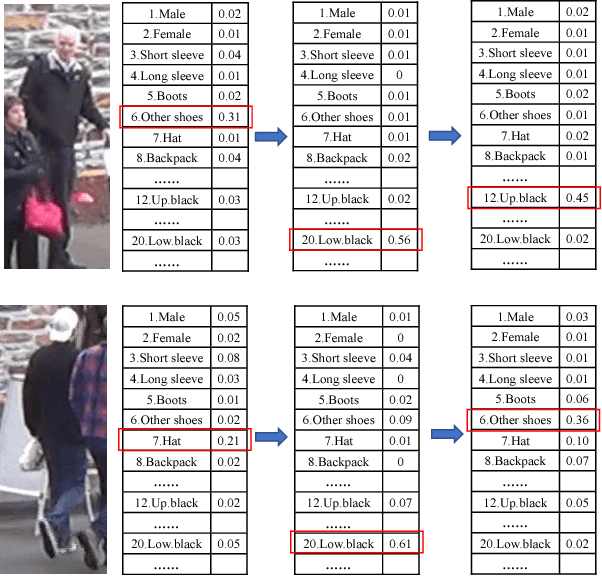
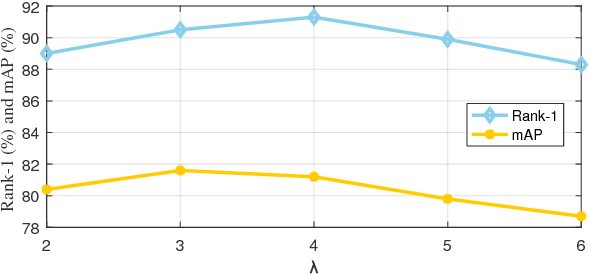
Attribute recognition has become crucial because of its wide applications in many computer vision tasks, such as person re-identification. Like many object recognition problems, variations in viewpoints, illumination, and recognition at far distance, all make this task challenging. In this work, we propose a joint CTC-Attention model (JCM), which maps attribute labels into sequences to learn the semantic relationship among attributes. Besides, this network uses neural network to encode images into sequences, and employs connectionist temporal classification (CTC) loss to train the network with the aim of improving the encoding performance of the network. At the same time, it adopts the attention model to decode the sequences, which can realize aligning the sequences and better learning the semantic information from attributes. Extensive experiments on three public datasets, i.e., Market-1501 attribute dataset, Duke attribute dataset and PETA dataset, demonstrate the effectiveness of the proposed method.
Neural Person Search Machines
Jul 21, 2017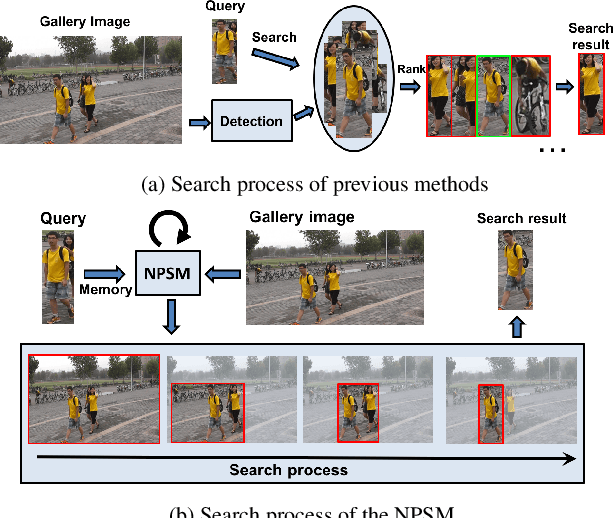
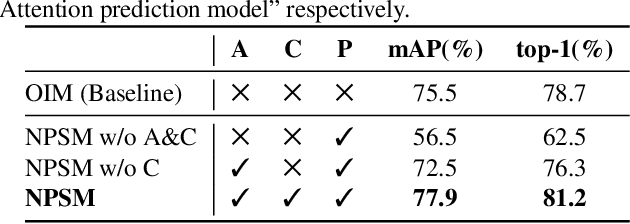
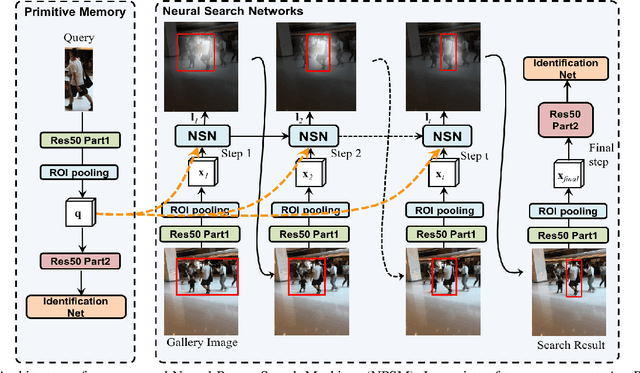
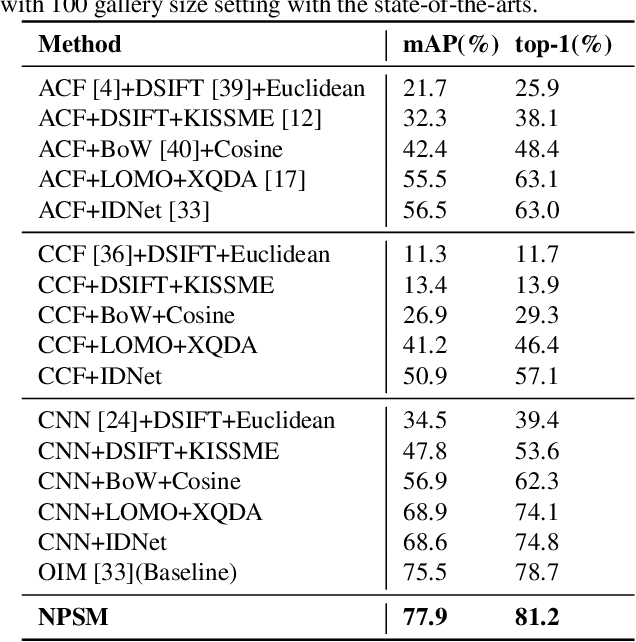
We investigate the problem of person search in the wild in this work. Instead of comparing the query against all candidate regions generated in a query-blind manner, we propose to recursively shrink the search area from the whole image till achieving precise localization of the target person, by fully exploiting information from the query and contextual cues in every recursive search step. We develop the Neural Person Search Machines (NPSM) to implement such recursive localization for person search. Benefiting from its neural search mechanism, NPSM is able to selectively shrink its focus from a loose region to a tighter one containing the target automatically. In this process, NPSM employs an internal primitive memory component to memorize the query representation which modulates the attention and augments its robustness to other distracting regions. Evaluations on two benchmark datasets, CUHK-SYSU Person Search dataset and PRW dataset, have demonstrated that our method can outperform current state-of-the-arts in both mAP and top-1 evaluation protocols.
Video-based Person Re-identification with Accumulative Motion Context
Jun 13, 2017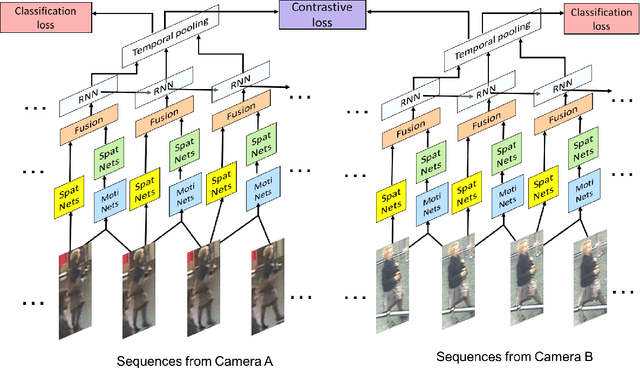
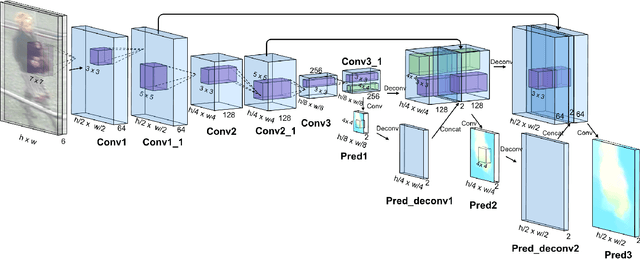
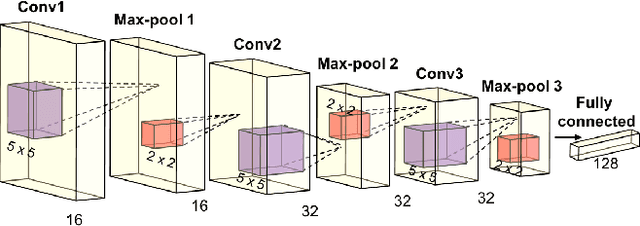
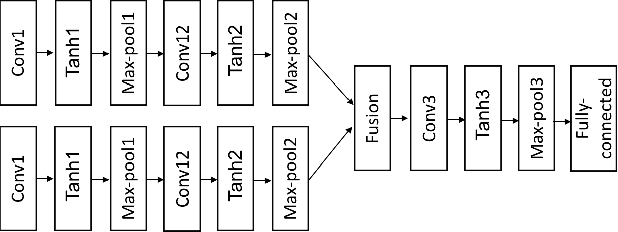
Video based person re-identification plays a central role in realistic security and video surveillance. In this paper we propose a novel Accumulative Motion Context (AMOC) network for addressing this important problem, which effectively exploits the long-range motion context for robustly identifying the same person under challenging conditions. Given a video sequence of the same or different persons, the proposed AMOC network jointly learns appearance representation and motion context from a collection of adjacent frames using a two-stream convolutional architecture. Then AMOC accumulates clues from motion context by recurrent aggregation, allowing effective information flow among adjacent frames and capturing dynamic gist of the persons. The architecture of AMOC is end-to-end trainable and thus motion context can be adapted to complement appearance clues under unfavorable conditions (e.g. occlusions). Extensive experiments are conduced on three public benchmark datasets, i.e., the iLIDS-VID, PRID-2011 and MARS datasets, to investigate the performance of AMOC. The experimental results demonstrate that the proposed AMOC network outperforms state-of-the-arts for video-based re-identification significantly and confirm the advantage of exploiting long-range motion context for video based person re-identification, validating our motivation evidently.
End-to-End Comparative Attention Networks for Person Re-identification
Apr 28, 2017
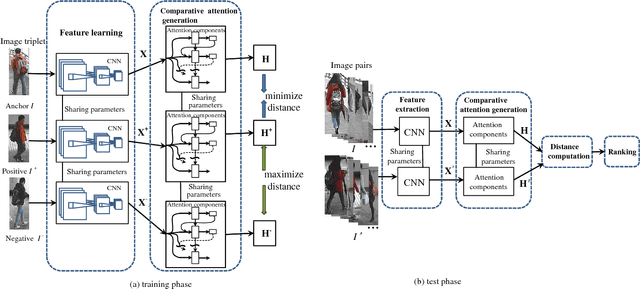
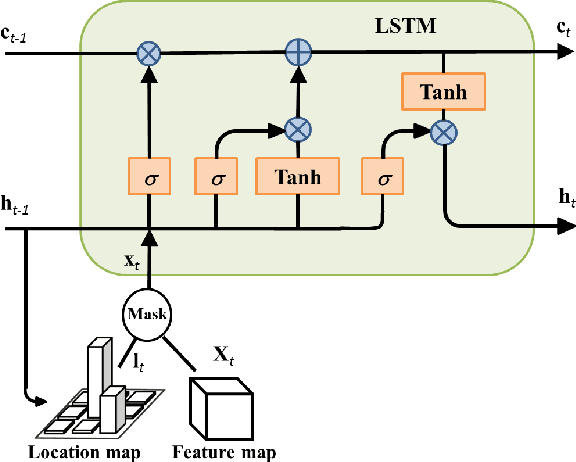
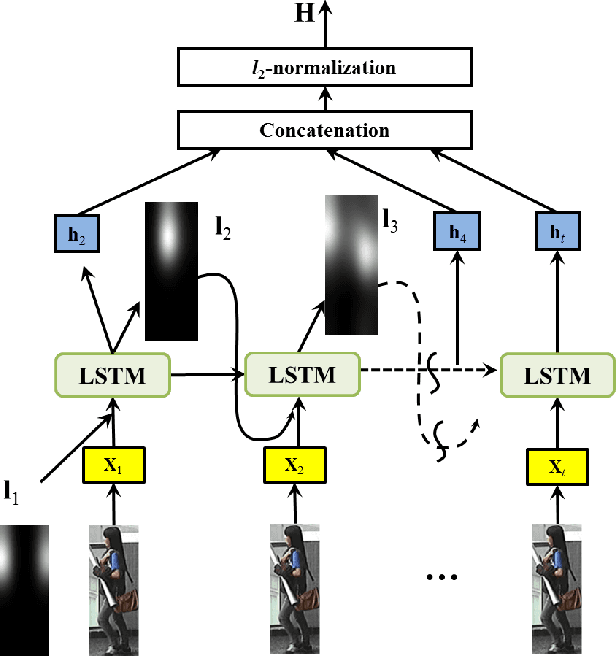
Person re-identification across disjoint camera views has been widely applied in video surveillance yet it is still a challenging problem. One of the major challenges lies in the lack of spatial and temporal cues, which makes it difficult to deal with large variations of lighting conditions, viewing angles, body poses and occlusions. Recently, several deep learning based person re-identification approaches have been proposed and achieved remarkable performance. However, most of those approaches extract discriminative features from the whole frame at one glimpse without differentiating various parts of the persons to identify. It is essentially important to examine multiple highly discriminative local regions of the person images in details through multiple glimpses for dealing with the large appearance variance. In this paper, we propose a new soft attention based model, i.e., the end to-end Comparative Attention Network (CAN), specifically tailored for the task of person re-identification. The end-to-end CAN learns to selectively focus on parts of pairs of person images after taking a few glimpses of them and adaptively comparing their appearance. The CAN model is able to learn which parts of images are relevant for discerning persons and automatically integrates information from different parts to determine whether a pair of images belongs to the same person. In other words, our proposed CAN model simulates the human perception process to verify whether two images are from the same person. Extensive experiments on three benchmark person re-identification datasets, including CUHK01, CHUHK03 and Market-1501, clearly demonstrate that our proposed end-to-end CAN for person re-identification outperforms well established baselines significantly and offer new state-of-the-art performance.