 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Light Field Depth Estimation Using Epipolar Plane Images
Mar 29, 2022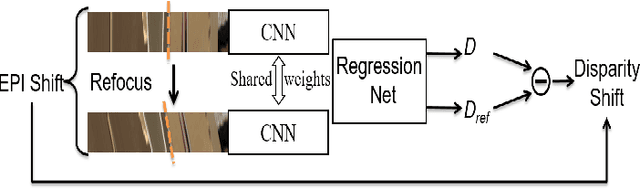
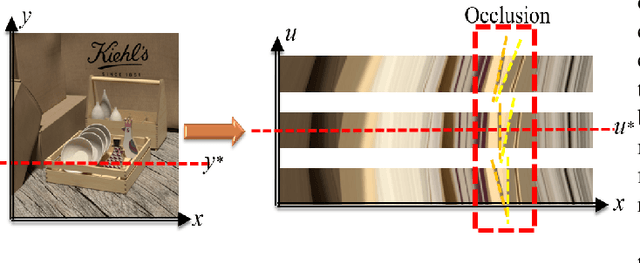
Exploiting light field data makes it possible to obtain dense and accurate depth map. However, synthetic scenes with limited disparity range cannot contain the diversity of real scenes. By training in synthetic data, current learning-based methods do not perform well in real scenes. In this paper, we propose a self-supervised learning framework for light field depth estimation. Different from the existing end-to-end training methods using disparity label per pixel, our approach implements network training by estimating EPI disparity shift after refocusing, which extends the disparity range of epipolar lines. To reduce the sensitivity of EPI to noise, we propose a new input mode called EPI-Stack, which stacks EPIs in the view dimension. This method is less sensitive to noise scenes than traditional input mode and improves the efficiency of estimation. Compared with other state-of-the-art methods, the proposed method can also obtain higher quality results in real-world scenarios, especially in the complex occlusion and depth discontinuity.
EPI-based Oriented Relation Networks for Light Field Depth Estimation
Jul 09, 2020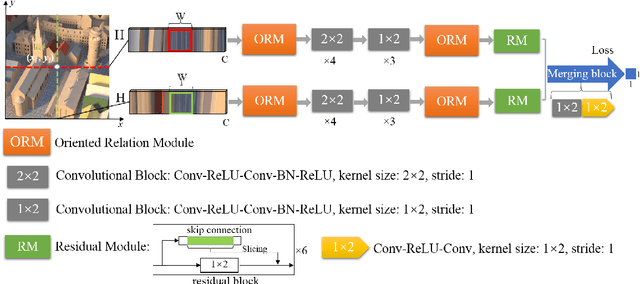
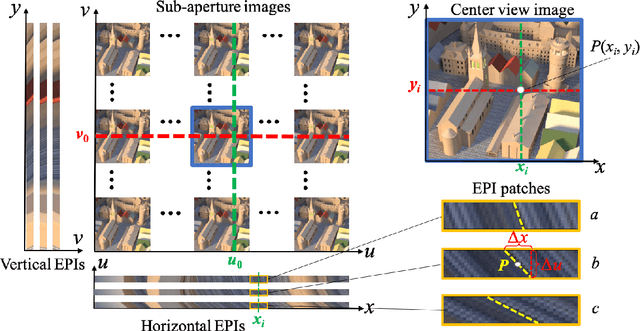

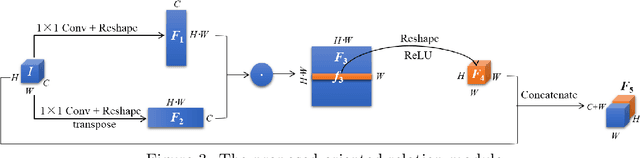
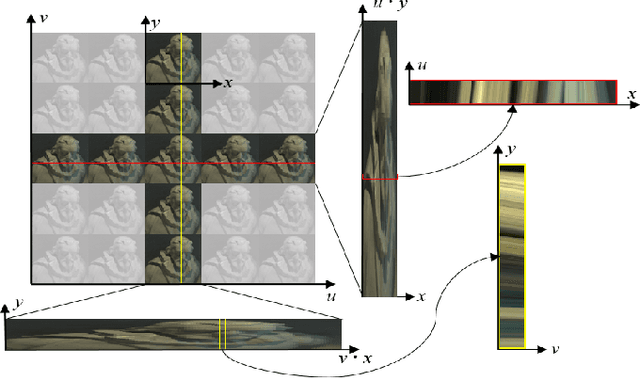
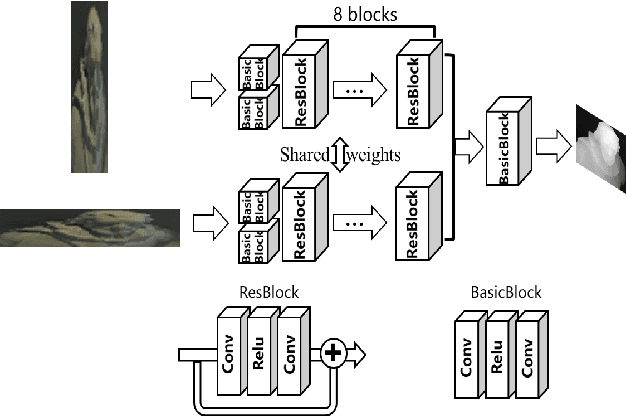
Light fields record not only the spatial information of observed scenes but also the directions of all incoming light rays. The spatial information and angular information implicitly contain the geometrical characteristics such as multi-view geometry or epipolar geometry, which can be exploited to improve the performance of depth estimation. Epipolar Plane Image (EPI), the unique 2D spatial-angular slice of the light field, contains patterns of oriented lines. The slope of these lines is associated with the disparity. Benefit from this property of EPIs, some representative methods estimate depth maps by analyzing the disparity of each line in EPIs. However, these methods often extract the optimal slope of the lines from EPIs while ignoring the relationship between neighboring pixels, which leads to inaccurate depth map predictions. Based on the observation that the similar linear structure between the oriented lines and their neighboring pixels, we propose an end-to-end fully convolutional network (FCN) to estimate the depth value of the intersection point on the horizontal and vertical EPIs. Specifically, we present a new feature extraction module, called Oriented Relation Module (ORM), that constructs the relationship between the line orientations. To facilitate training, we also propose a refocusing-based data augmentation method to obtain different slopes from EPIs of the same scene point. Extensive experiments verify the efficacy of learning relations and show that our approach is competitive to other state-of-the-art methods.