 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Regression Loss for DETRs
Oct 30, 2024



In this paper, we introduce a novel unbiased regression loss for DETR-based detectors. The conventional $L_{1}$ regression loss tends to bias towards larger boxes, as they disproportionately contribute more towards the overall loss compared to smaller boxes. Consequently, the detection performance for small objects suffers. To alleviate this bias, the proposed new unbiased loss, termed Sized $L_{1}$ loss, normalizes the size of all boxes based on their individual width and height. Our experiments demonstrate consistent improvements in both fully-supervised and semi-supervised settings using the MS-COCO benchmark dataset.
Invariant Feature Regularization for Fair Face Recognition
Oct 23, 2023



Fair face recognition is all about learning invariant feature that generalizes to unseen faces in any demographic group. Unfortunately, face datasets inevitably capture the imbalanced demographic attributes that are ubiquitous in real-world observations, and the model learns biased feature that generalizes poorly in the minority group. We point out that the bias arises due to the confounding demographic attributes, which mislead the model to capture the spurious demographic-specific feature. The confounding effect can only be removed by causal intervention, which requires the confounder annotations. However, such annotations can be prohibitively expensive due to the diversity of the demographic attributes. To tackle this, we propose to generate diverse data partitions iteratively in an unsupervised fashion. Each data partition acts as a self-annotated confounder, enabling our Invariant Feature Regularization (INV-REG) to deconfound. INV-REG is orthogonal to existing methods, and combining INV-REG with two strong baselines (Arcface and CIFP) leads to new state-of-the-art that improves face recognition on a variety of demographic groups. Code is available at https://github.com/PanasonicConnect/InvReg.
Equivariance and Invariance Inductive Bias for Learning from Insufficient Data
Jul 25, 2022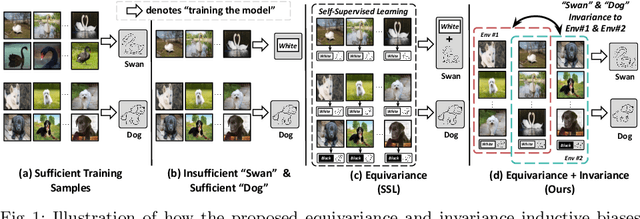
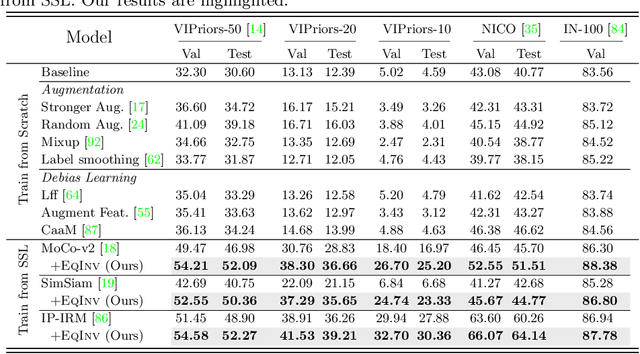


We are interested in learning robust models from insufficient data, without the need for any externally pre-trained checkpoints. First, compared to sufficient data, we show why insufficient data renders the model more easily biased to the limited training environments that are usually different from testing. For example, if all the training swan samples are "white", the model may wrongly use the "white" environment to represent the intrinsic class swan. Then, we justify that equivariance inductive bias can retain the class feature while invariance inductive bias can remove the environmental feature, leaving the class feature that generalizes to any environmental changes in testing. To impose them on learning, for equivariance, we demonstrate that any off-the-shelf contrastive-based self-supervised feature learning method can be deployed; for invariance, we propose a class-wise invariant risk minimization (IRM) that efficiently tackles the challenge of missing environmental annotation in conventional IRM. State-of-the-art experimental results on real-world benchmarks (VIPriors, ImageNet100 and NICO) validate the great potential of equivariance and invariance in data-efficient learning. The code is available at https://github.com/Wangt-CN/EqInv
Neural Person Search Machines
Jul 21, 2017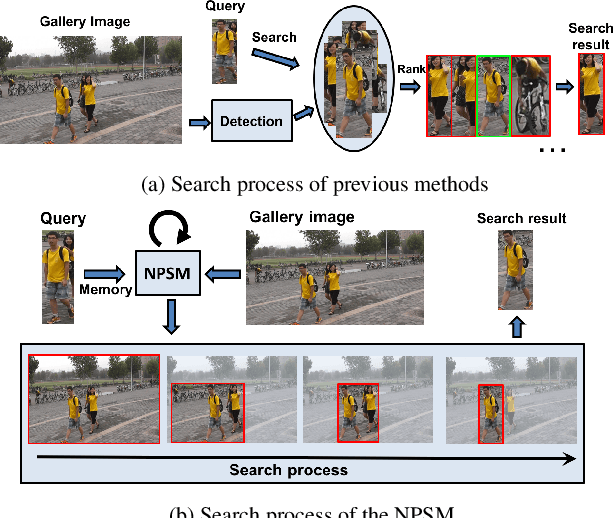
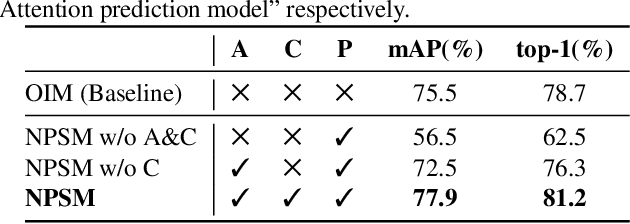
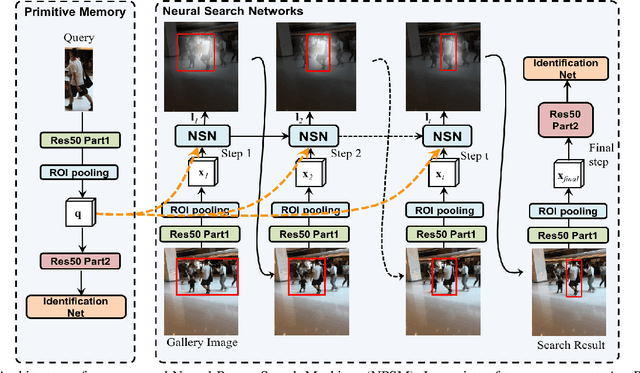
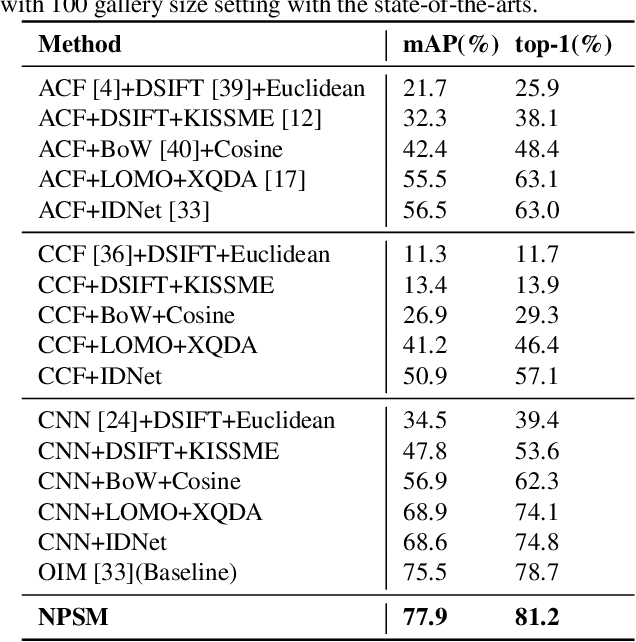
We investigate the problem of person search in the wild in this work. Instead of comparing the query against all candidate regions generated in a query-blind manner, we propose to recursively shrink the search area from the whole image till achieving precise localization of the target person, by fully exploiting information from the query and contextual cues in every recursive search step. We develop the Neural Person Search Machines (NPSM) to implement such recursive localization for person search. Benefiting from its neural search mechanism, NPSM is able to selectively shrink its focus from a loose region to a tighter one containing the target automatically. In this process, NPSM employs an internal primitive memory component to memorize the query representation which modulates the attention and augments its robustness to other distracting regions. Evaluations on two benchmark datasets, CUHK-SYSU Person Search dataset and PRW dataset, have demonstrated that our method can outperform current state-of-the-arts in both mAP and top-1 evaluation protocols.
Video-based Person Re-identification with Accumulative Motion Context
Jun 13, 2017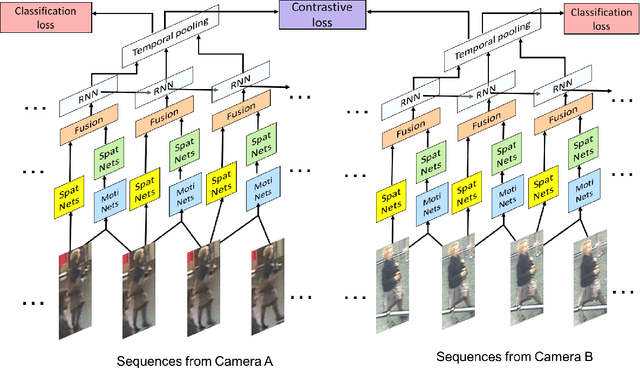
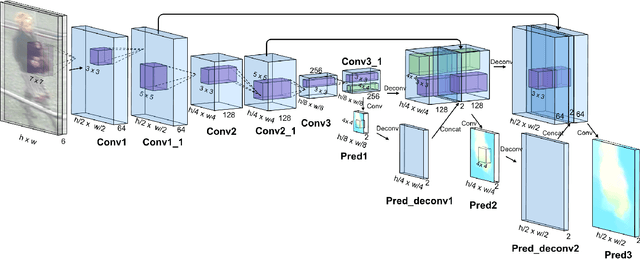
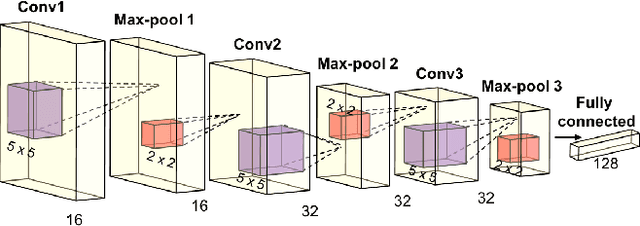
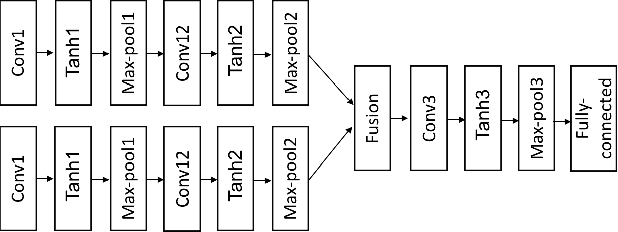
Video based person re-identification plays a central role in realistic security and video surveillance. In this paper we propose a novel Accumulative Motion Context (AMOC) network for addressing this important problem, which effectively exploits the long-range motion context for robustly identifying the same person under challenging conditions. Given a video sequence of the same or different persons, the proposed AMOC network jointly learns appearance representation and motion context from a collection of adjacent frames using a two-stream convolutional architecture. Then AMOC accumulates clues from motion context by recurrent aggregation, allowing effective information flow among adjacent frames and capturing dynamic gist of the persons. The architecture of AMOC is end-to-end trainable and thus motion context can be adapted to complement appearance clues under unfavorable conditions (e.g. occlusions). Extensive experiments are conduced on three public benchmark datasets, i.e., the iLIDS-VID, PRID-2011 and MARS datasets, to investigate the performance of AMOC. The experimental results demonstrate that the proposed AMOC network outperforms state-of-the-arts for video-based re-identification significantly and confirm the advantage of exploiting long-range motion context for video based person re-identification, validating our motivation evidently.