 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Images as Continuous Actions: Numerical Visual Chain-of-Thought
Feb 27, 2026Recent multimodal large language models (MLLMs) increasingly rely on visual chain-of-thought to perform region-grounded reasoning over images. However, existing approaches ground regions via either textified coordinates-causing modality mismatch and semantic fragmentation or fixed-granularity patches that both limit precise region selection and often require non-trivial architectural changes. In this paper, we propose Numerical Visual Chain-of-Thought (NV-CoT), a framework that enables MLLMs to reason over images using continuous numerical coordinates. NV-CoT expands the MLLM action space from discrete vocabulary tokens to a continuous Euclidean space, allowing models to directly generate bounding-box coordinates as actions with only minimal architectural modification. The framework supports both supervised fine-tuning and reinforcement learning. In particular, we replace categorical token policies with a Gaussian (or Laplace) policy over coordinates and introduce stochasticity via reparameterized sampling, making NV-CoT fully compatible with GRPO-style policy optimization. Extensive experiments on three benchmarks against eight representative visual reasoning baselines demonstrate that NV-CoT significantly improves localization precision and final answer accuracy, while also accelerating training convergence, validating the effectiveness of continuous-action visual reasoning in MLLMs. The code is available in https://github.com/kesenzhao/NV-CoT.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.
Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
Apr 20, 2025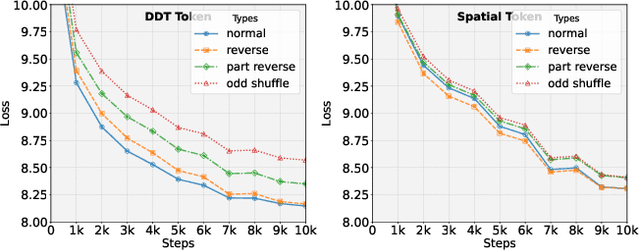
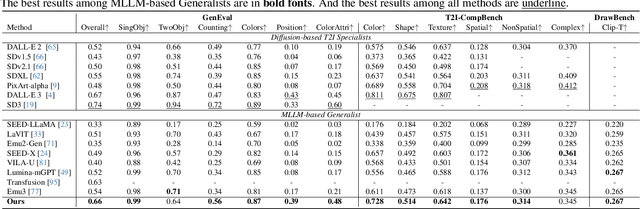
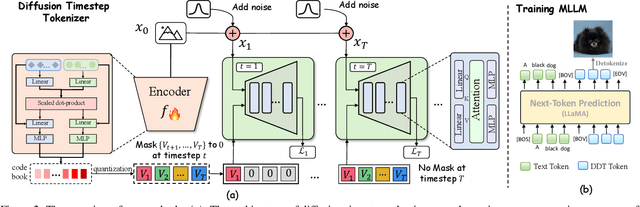
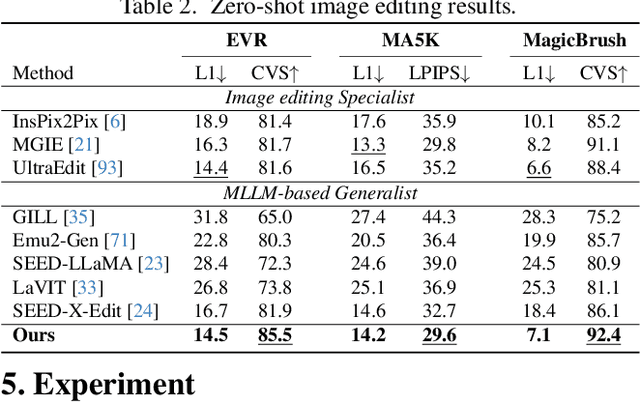
Recent endeavors in Multimodal Large Language Models (MLLMs) aim to unify visual comprehension and generation by combining LLM and diffusion models, the state-of-the-art in each task, respectively. Existing approaches rely on spatial visual tokens, where image patches are encoded and arranged according to a spatial order (e.g., raster scan). However, we show that spatial tokens lack the recursive structure inherent to languages, hence form an impossible language for LLM to master. In this paper, we build a proper visual language by leveraging diffusion timesteps to learn discrete, recursive visual tokens. Our proposed tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to effectively integrate the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework. Extensive experiments show that we achieve superior performance for multimodal comprehension and generation simultaneously compared with other MLLMs. Project Page: https://DDT-LLaMA.github.io/.
Benchmarking Multimodal CoT Reward Model Stepwise by Visual Program
Apr 09, 2025



Recent advancements in reward signal usage for Large Language Models (LLMs) are remarkable. However, significant challenges exist when transitioning reward signal to the multimodal domain, including labor-intensive annotations, over-reliance on one-step rewards, and inadequate evaluation. To address these issues, we propose SVIP, a novel approach to train a step-level multi-dimensional Chain-of-Thought~(CoT) reward model automatically. It generates code for solving visual tasks and transforms the analysis of code blocks into the evaluation of CoT step as training samples. Then, we train SVIP-Reward model using a multi-head attention mechanism called TriAtt-CoT. The advantages of SVIP-Reward are evident throughout the entire process of MLLM. We also introduce a benchmark for CoT reward model training and testing. Experimental results demonstrate that SVIP-Reward improves MLLM performance across training and inference-time scaling, yielding better results on benchmarks while reducing hallucinations and enhancing reasoning ability.
Mastering Collaborative Multi-modal Data Selection: A Focus on Informativeness, Uniqueness, and Representativeness
Dec 09, 2024



Instruction tuning fine-tunes pre-trained Multi-modal Large Language Models (MLLMs) to handle real-world tasks. However, the rapid expansion of visual instruction datasets introduces data redundancy, leading to excessive computational costs. We propose a collaborative framework, DataTailor, which leverages three key principles--informativeness, uniqueness, and representativeness--for effective data selection. We argue that a valuable sample should be informative of the task, non-redundant, and represent the sample distribution (i.e., not an outlier). We further propose practical ways to score against each principle, which automatically adapts to a given dataset without tedious hyperparameter tuning. Comprehensive experiments on various benchmarks demonstrate that DataTailor achieves 100.8% of the performance of full-data fine-tuning with only 15% of the data, significantly reducing computational costs while maintaining superior results. This exemplifies the "Less is More" philosophy in MLLM development.
AnyEdit: Mastering Unified High-Quality Image Editing for Any Idea
Nov 24, 2024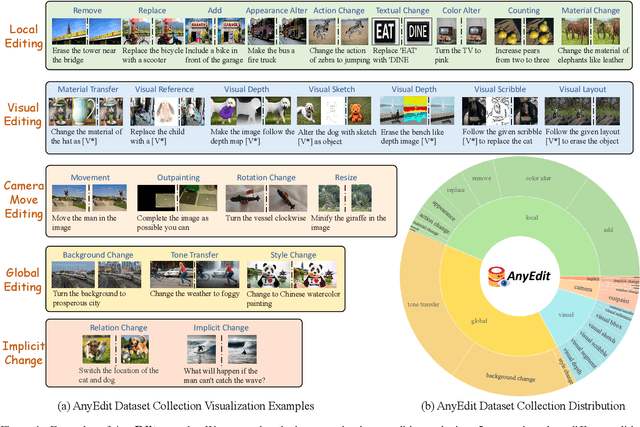



Instruction-based image editing aims to modify specific image elements with natural language instructions. However, current models in this domain often struggle to accurately execute complex user instructions, as they are trained on low-quality data with limited editing types. We present AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains. We ensure the diversity and quality of the AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results. Using the dataset, we further train a novel AnyEdit Stable Diffusion with task-aware routing and learnable task embedding for unified image editing. Comprehensive experiments on three benchmark datasets show that AnyEdit consistently boosts the performance of diffusion-based editing models. This presents prospects for developing instruction-driven image editing models that support human creativity.
Few-shot Learner Parameterization by Diffusion Time-steps
Mar 05, 2024


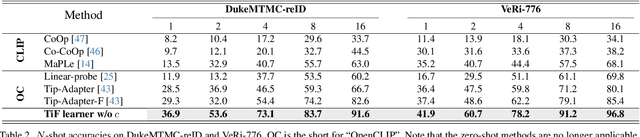
Even when using large multi-modal foundation models, few-shot learning is still challenging -- if there is no proper inductive bias, it is nearly impossible to keep the nuanced class attributes while removing the visually prominent attributes that spuriously correlate with class labels. To this end, we find an inductive bias that the time-steps of a Diffusion Model (DM) can isolate the nuanced class attributes, i.e., as the forward diffusion adds noise to an image at each time-step, nuanced attributes are usually lost at an earlier time-step than the spurious attributes that are visually prominent. Building on this, we propose Time-step Few-shot (TiF) learner. We train class-specific low-rank adapters for a text-conditioned DM to make up for the lost attributes, such that images can be accurately reconstructed from their noisy ones given a prompt. Hence, at a small time-step, the adapter and prompt are essentially a parameterization of only the nuanced class attributes. For a test image, we can use the parameterization to only extract the nuanced class attributes for classification. TiF learner significantly outperforms OpenCLIP and its adapters on a variety of fine-grained and customized few-shot learning tasks. Codes are in https://github.com/yue-zhongqi/tif.
Exploring Diffusion Time-steps for Unsupervised Representation Learning
Jan 21, 2024Representation learning is all about discovering the hidden modular attributes that generate the data faithfully. We explore the potential of Denoising Diffusion Probabilistic Model (DM) in unsupervised learning of the modular attributes. We build a theoretical framework that connects the diffusion time-steps and the hidden attributes, which serves as an effective inductive bias for unsupervised learning. Specifically, the forward diffusion process incrementally adds Gaussian noise to samples at each time-step, which essentially collapses different samples into similar ones by losing attributes, e.g., fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). To disentangle the modular attributes, at each time-step t, we learn a t-specific feature to compensate for the newly lost attribute, and the set of all 1,...,t-specific features, corresponding to the cumulative set of lost attributes, are trained to make up for the reconstruction error of a pre-trained DM at time-step t. On CelebA, FFHQ, and Bedroom datasets, the learned feature significantly improves attribute classification and enables faithful counterfactual generation, e.g., interpolating only one specified attribute between two images, validating the disentanglement quality. Codes are in https://github.com/yue-zhongqi/diti.