 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MEnvAgent: Scalable Polyglot Environment Construction for Verifiable Software Engineering
Jan 30, 2026The evolution of Large Language Model (LLM) agents for software engineering (SWE) is constrained by the scarcity of verifiable datasets, a bottleneck stemming from the complexity of constructing executable environments across diverse languages. To address this, we introduce MEnvAgent, a Multi-language framework for automated Environment construction that facilitates scalable generation of verifiable task instances. MEnvAgent employs a multi-agent Planning-Execution-Verification architecture to autonomously resolve construction failures and integrates a novel Environment Reuse Mechanism that reduces computational overhead by incrementally patching historical environments. Evaluations on MEnvBench, a new benchmark comprising 1,000 tasks across 10 languages, demonstrate that MEnvAgent outperforms baselines, improving Fail-to-Pass (F2P) rates by 8.6% while reducing time costs by 43%. Additionally, we demonstrate the utility of MEnvAgent by constructing MEnvData-SWE, the largest open-source polyglot dataset of realistic verifiable Docker environments to date, alongside solution trajectories that enable consistent performance gains on SWE tasks across a wide range of models. Our code, benchmark, and dataset are available at https://github.com/ernie-research/MEnvAgent.
Recognition-Synergistic Scene Text Editing
Mar 11, 2025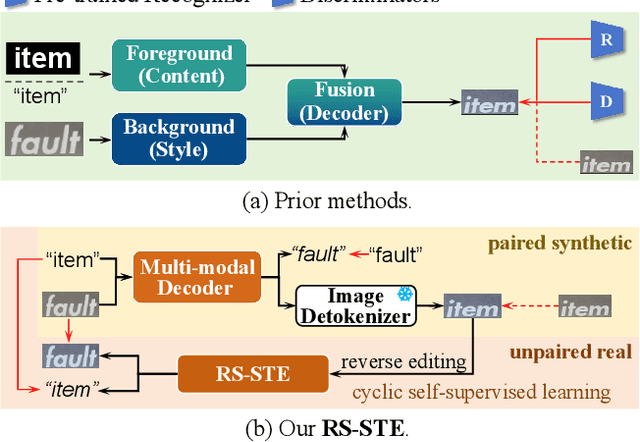
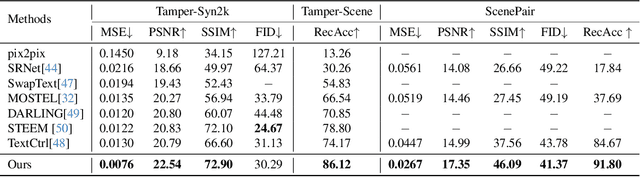
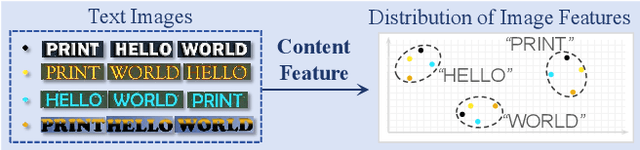
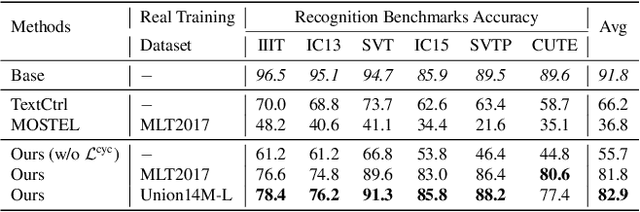
Scene text editing aims to modify text content within scene images while maintaining style consistency. Traditional methods achieve this by explicitly disentangling style and content from the source image and then fusing the style with the target content, while ensuring content consistency using a pre-trained recognition model. Despite notable progress, these methods suffer from complex pipelines, leading to suboptimal performance in complex scenarios. In this work, we introduce Recognition-Synergistic Scene Text Editing (RS-STE), a novel approach that fully exploits the intrinsic synergy of text recognition for editing. Our model seamlessly integrates text recognition with text editing within a unified framework, and leverages the recognition model's ability to implicitly disentangle style and content while ensuring content consistency. Specifically, our approach employs a multi-modal parallel decoder based on transformer architecture, which predicts both text content and stylized images in parallel. Additionally, our cyclic self-supervised fine-tuning strategy enables effective training on unpaired real-world data without ground truth, enhancing style and content consistency through a twice-cyclic generation process. Built on a relatively simple architecture, \mymodel achieves state-of-the-art performance on both synthetic and real-world benchmarks, and further demonstrates the effectiveness of leveraging the generated hard cases to boost the performance of downstream recognition tasks. Code is available at https://github.com/ZhengyaoFang/RS-STE.
Efficient Vision Language Model Fine-tuning for Text-based Person Anomaly Search
Feb 05, 2025



This paper presents the HFUT-LMC team's solution to the WWW 2025 challenge on Text-based Person Anomaly Search (TPAS). The primary objective of this challenge is to accurately identify pedestrians exhibiting either normal or abnormal behavior within a large library of pedestrian images. Unlike traditional video analysis tasks, TPAS significantly emphasizes understanding and interpreting the subtle relationships between text descriptions and visual data. The complexity of this task lies in the model's need to not only match individuals to text descriptions in massive image datasets but also accurately differentiate between search results when faced with similar descriptions. To overcome these challenges, we introduce the Similarity Coverage Analysis (SCA) strategy to address the recognition difficulty caused by similar text descriptions. This strategy effectively enhances the model's capacity to manage subtle differences, thus improving both the accuracy and reliability of the search. Our proposed solution demonstrated excellent performance in this challenge.
Discrete to Continuous: Generating Smooth Transition Poses from Sign Language Observation
Nov 25, 2024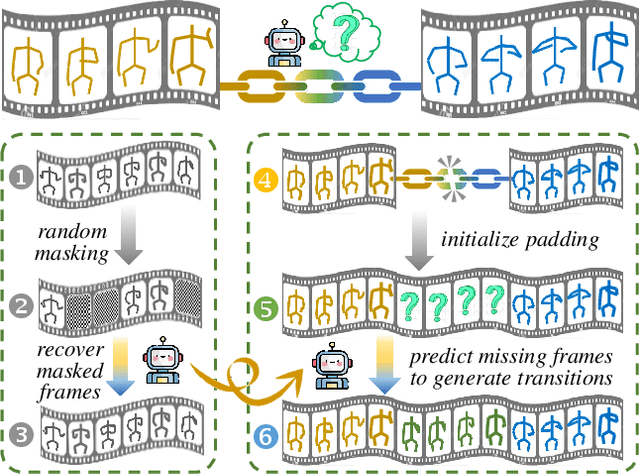
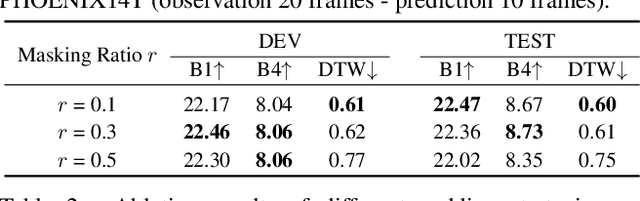
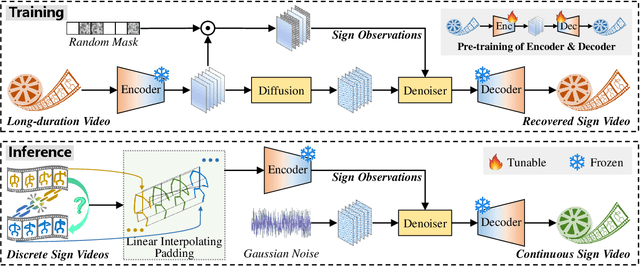
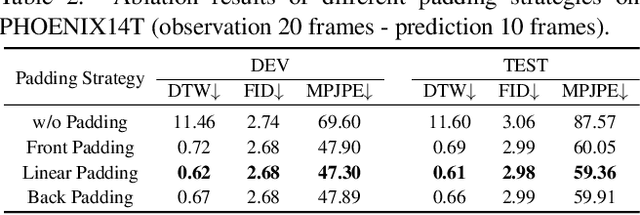
Generating continuous sign language videos from discrete segments is challenging due to the need for smooth transitions that preserve natural flow and meaning. Traditional approaches that simply concatenate isolated signs often result in abrupt transitions, disrupting video coherence. To address this, we propose a novel framework, Sign-D2C, that employs a conditional diffusion model to synthesize contextually smooth transition frames, enabling the seamless construction of continuous sign language sequences. Our approach transforms the unsupervised problem of transition frame generation into a supervised training task by simulating the absence of transition frames through random masking of segments in long-duration sign videos. The model learns to predict these masked frames by denoising Gaussian noise, conditioned on the surrounding sign observations, allowing it to handle complex, unstructured transitions. During inference, we apply a linearly interpolating padding strategy that initializes missing frames through interpolation between boundary frames, providing a stable foundation for iterative refinement by the diffusion model. Extensive experiments on the PHOENIX14T, USTC-CSL100, and USTC-SLR500 datasets demonstrate the effectiveness of our method in producing continuous, natural sign language videos.
WeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting
Jul 28, 2024Transcription-only Supervised Text Spotting aims to learn text spotters relying only on transcriptions but no text boundaries for supervision, thus eliminating expensive boundary annotation. The crux of this task lies in locating each transcription in scene text images without location annotations. In this work, we formulate this challenging problem as a Weakly Supervised Cross-modality Contrastive Learning problem, and design a simple yet effective model dubbed WeCromCL that is able to detect each transcription in a scene image in a weakly supervised manner. Unlike typical methods for cross-modality contrastive learning that focus on modeling the holistic semantic correlation between an entire image and a text description, our WeCromCL conducts atomistic contrastive learning to model the character-wise appearance consistency between a text transcription and its correlated region in a scene image to detect an anchor point for the transcription in a weakly supervised manner. The detected anchor points by WeCromCL are further used as pseudo location labels to guide the learning of text spotting. Extensive experiments on four challenging benchmarks demonstrate the superior performance of our model over other methods. Code will be released.
Decoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter
Jul 18, 2022

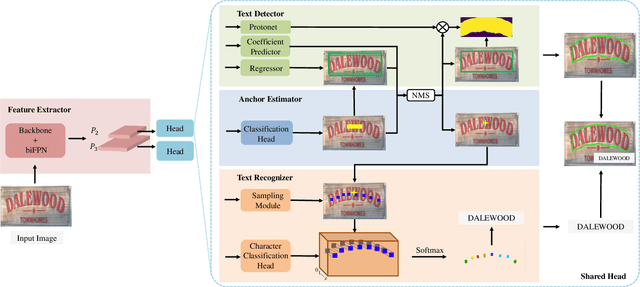

Typical text spotters follow the two-stage spotting strategy: detect the precise boundary for a text instance first and then perform text recognition within the located text region. While such strategy has achieved substantial progress, there are two underlying limitations. 1) The performance of text recognition depends heavily on the precision of text detection, resulting in the potential error propagation from detection to recognition. 2) The RoI cropping which bridges the detection and recognition brings noise from background and leads to information loss when pooling or interpolating from feature maps. In this work we propose the single shot Self-Reliant Scene Text Spotter (SRSTS), which circumvents these limitations by decoupling recognition from detection. Specifically, we conduct text detection and recognition in parallel and bridge them by the shared positive anchor point. Consequently, our method is able to recognize the text instances correctly even though the precise text boundaries are challenging to detect. Additionally, our method reduces the annotation cost for text detection substantially. Extensive experiments on regular-shaped benchmark and arbitrary-shaped benchmark demonstrate that our SRSTS compares favorably to previous state-of-the-art spotters in terms of both accuracy and efficiency.
Sequence-based Person Attribute Recognition with Joint CTC-Attention Model
Nov 27, 2018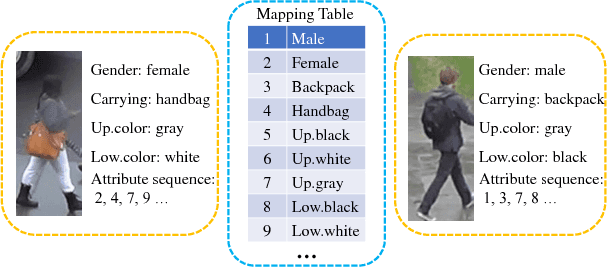
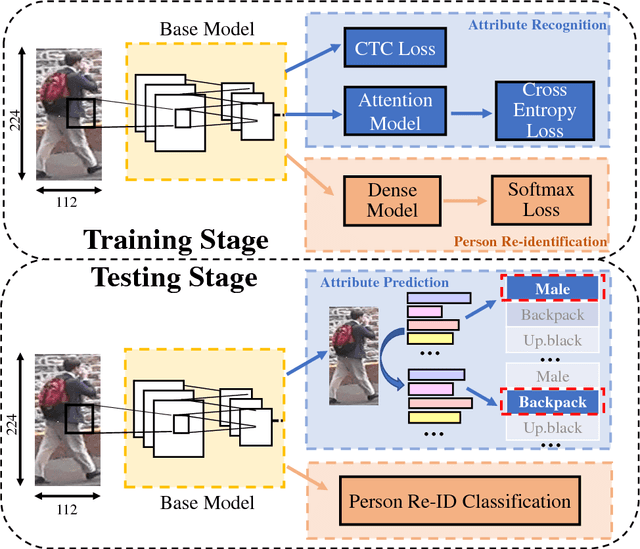
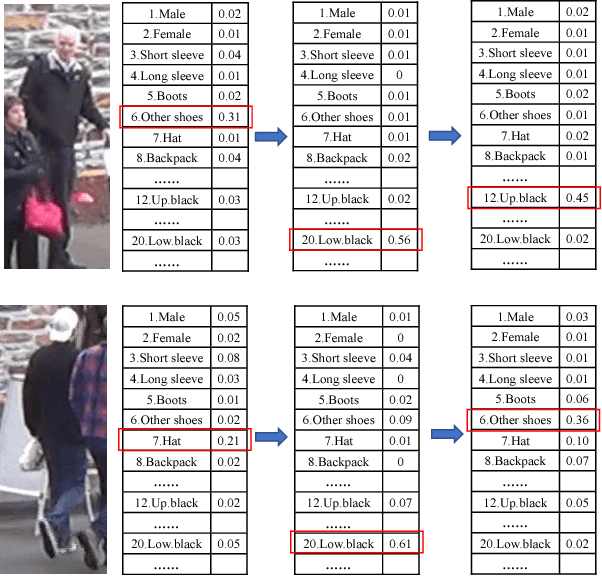
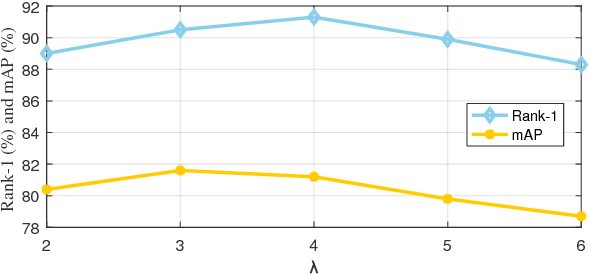
Attribute recognition has become crucial because of its wide applications in many computer vision tasks, such as person re-identification. Like many object recognition problems, variations in viewpoints, illumination, and recognition at far distance, all make this task challenging. In this work, we propose a joint CTC-Attention model (JCM), which maps attribute labels into sequences to learn the semantic relationship among attributes. Besides, this network uses neural network to encode images into sequences, and employs connectionist temporal classification (CTC) loss to train the network with the aim of improving the encoding performance of the network. At the same time, it adopts the attention model to decode the sequences, which can realize aligning the sequences and better learning the semantic information from attributes. Extensive experiments on three public datasets, i.e., Market-1501 attribute dataset, Duke attribute dataset and PETA dataset, demonstrate the effectiveness of the proposed method.