 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-based Person Attribute Recognition with Joint CTC-Attention Model
Paper and Code
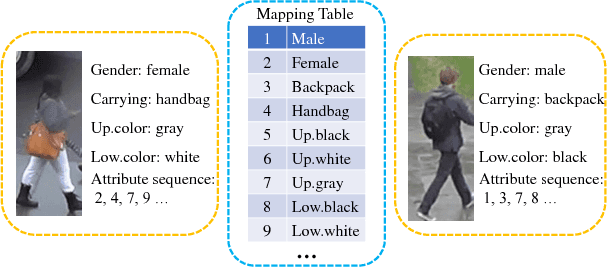
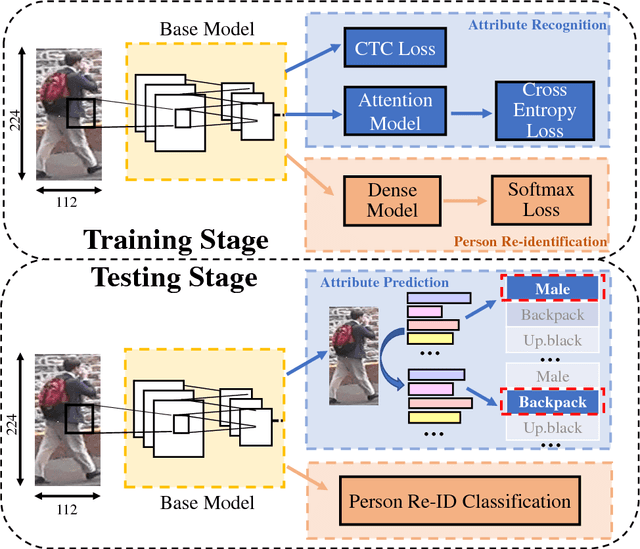
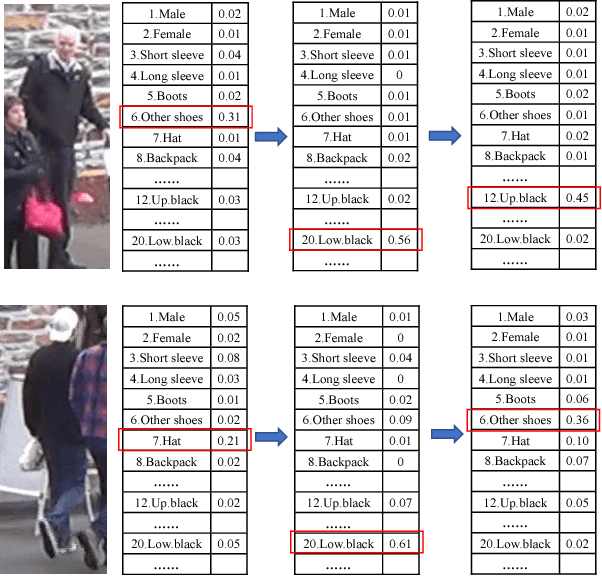
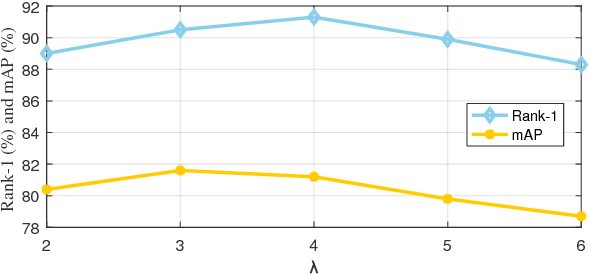
Attribute recognition has become crucial because of its wide applications in many computer vision tasks, such as person re-identification. Like many object recognition problems, variations in viewpoints, illumination, and recognition at far distance, all make this task challenging. In this work, we propose a joint CTC-Attention model (JCM), which maps attribute labels into sequences to learn the semantic relationship among attributes. Besides, this network uses neural network to encode images into sequences, and employs connectionist temporal classification (CTC) loss to train the network with the aim of improving the encoding performance of the network. At the same time, it adopts the attention model to decode the sequences, which can realize aligning the sequences and better learning the semantic information from attributes. Extensive experiments on three public datasets, i.e., Market-1501 attribute dataset, Duke attribute dataset and PETA dataset, demonstrate the effectiveness of the proposed method.