 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter
Paper and Code
Jul 18, 2022

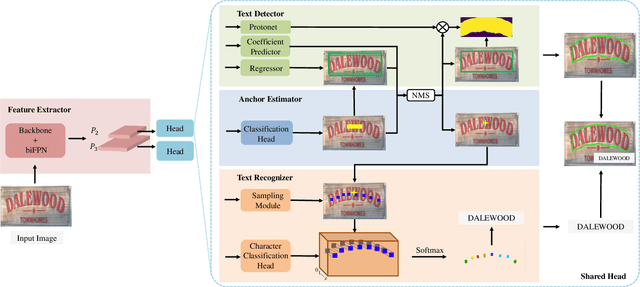

Typical text spotters follow the two-stage spotting strategy: detect the precise boundary for a text instance first and then perform text recognition within the located text region. While such strategy has achieved substantial progress, there are two underlying limitations. 1) The performance of text recognition depends heavily on the precision of text detection, resulting in the potential error propagation from detection to recognition. 2) The RoI cropping which bridges the detection and recognition brings noise from background and leads to information loss when pooling or interpolating from feature maps. In this work we propose the single shot Self-Reliant Scene Text Spotter (SRSTS), which circumvents these limitations by decoupling recognition from detection. Specifically, we conduct text detection and recognition in parallel and bridge them by the shared positive anchor point. Consequently, our method is able to recognize the text instances correctly even though the precise text boundaries are challenging to detect. Additionally, our method reduces the annotation cost for text detection substantially. Extensive experiments on regular-shaped benchmark and arbitrary-shaped benchmark demonstrate that our SRSTS compares favorably to previous state-of-the-art spotters in terms of both accuracy and efficiency.