 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
A Brain-Inspired Perception-Decision Driving Model Based on Neural Pathway Anatomical Alignment
Feb 22, 2025



In the realm of autonomous driving, conventional approaches for vehicle perception and decision-making primarily rely on sensor input and rule-based algorithms. However, these methodologies often suffer from lack of interpretability and robustness, particularly in intricate traffic scenarios. To tackle this challenge, we propose a novel brain-inspired driving (BID) framework. Diverging from traditional methods, our approach harnesses brain-inspired perception technology to achieve more efficient and robust environmental perception. Additionally, it employs brain-inspired decision-making techniques to facilitate intelligent decision-making. The experimental results show that the performance has been significantly improved across various autonomous driving tasks and achieved the end-to-end autopilot successfully. This contribution not only advances interpretability and robustness but also offers fancy insights and methodologies for further advancing autonomous driving technology.
BAN: Neuroanatomical Aligning in Auditory Recognition between Artificial Neural Network and Human Cortex
Feb 21, 2025

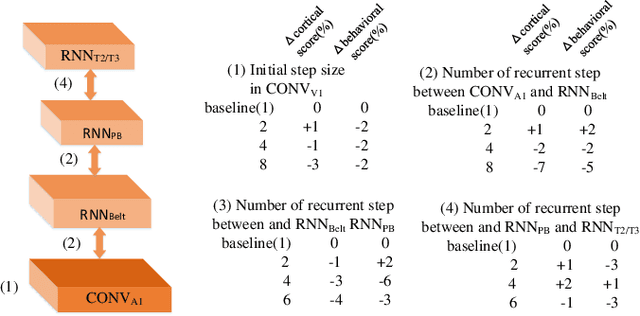

Drawing inspiration from neurosciences, artificial neural networks (ANNs) have evolved from shallow architectures to highly complex, deep structures, yielding exceptional performance in auditory recognition tasks. However, traditional ANNs often struggle to align with brain regions due to their excessive depth and lack of biologically realistic features, like recurrent connection. To address this, a brain-like auditory network (BAN) is introduced, which incorporates four neuroanatomically mapped areas and recurrent connection, guided by a novel metric called the brain-like auditory score (BAS). BAS serves as a benchmark for evaluating the similarity between BAN and human auditory recognition pathway. We further propose that specific areas in the cerebral cortex, mainly the middle and medial superior temporal (T2/T3) areas, correspond to the designed network structure, drawing parallels with the brain's auditory perception pathway. Our findings suggest that the neuroanatomical similarity in the cortex and auditory classification abilities of the ANN are well-aligned. In addition to delivering excellent performance on a music genre classification task, the BAN demonstrates a high BAS score. In conclusion, this study presents BAN as a recurrent, brain-inspired ANN, representing the first model that mirrors the cortical pathway of auditory recognition.
Efficient Vision Language Model Fine-tuning for Text-based Person Anomaly Search
Feb 05, 2025



This paper presents the HFUT-LMC team's solution to the WWW 2025 challenge on Text-based Person Anomaly Search (TPAS). The primary objective of this challenge is to accurately identify pedestrians exhibiting either normal or abnormal behavior within a large library of pedestrian images. Unlike traditional video analysis tasks, TPAS significantly emphasizes understanding and interpreting the subtle relationships between text descriptions and visual data. The complexity of this task lies in the model's need to not only match individuals to text descriptions in massive image datasets but also accurately differentiate between search results when faced with similar descriptions. To overcome these challenges, we introduce the Similarity Coverage Analysis (SCA) strategy to address the recognition difficulty caused by similar text descriptions. This strategy effectively enhances the model's capacity to manage subtle differences, thus improving both the accuracy and reliability of the search. Our proposed solution demonstrated excellent performance in this challenge.
Grimm: A Plug-and-Play Perturbation Rectifier for Graph Neural Networks Defending against Poisoning Attacks
Dec 11, 2024

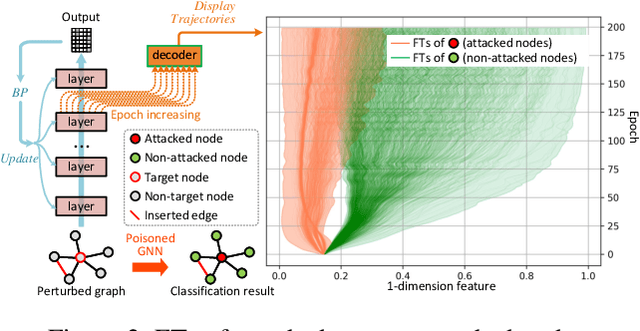

End-to-end training with global optimization have popularized graph neural networks (GNNs) for node classification, yet inadvertently introduced vulnerabilities to adversarial edge-perturbing attacks. Adversaries can exploit the inherent opened interfaces of GNNs' input and output, perturbing critical edges and thus manipulating the classification results. Current defenses, due to their persistent utilization of global-optimization-based end-to-end training schemes, inherently encapsulate the vulnerabilities of GNNs. This is specifically evidenced in their inability to defend against targeted secondary attacks. In this paper, we propose the Graph Agent Network (GAgN) to address the aforementioned vulnerabilities of GNNs. GAgN is a graph-structured agent network in which each node is designed as an 1-hop-view agent. Through the decentralized interactions between agents, they can learn to infer global perceptions to perform tasks including inferring embeddings, degrees and neighbor relationships for given nodes. This empowers nodes to filtering adversarial edges while carrying out classification tasks. Furthermore, agents' limited view prevents malicious messages from propagating globally in GAgN, thereby resisting global-optimization-based secondary attacks. We prove that single-hidden-layer multilayer perceptrons (MLPs) are theoretically sufficient to achieve these functionalities. Experimental results show that GAgN effectively implements all its intended capabilities and, compared to state-of-the-art defenses, achieves optimal classification accuracy on the perturbed datasets.
A Classic-Quantum Hybrid Network Framework: CQH-Net
Dec 03, 2024



Deep Learning has shown remarkable capabilities in pattern recognition, feature extraction, and classification decision-making. With the rise of quantum computing, the potential of quantum neural networks (QNNs) in Artificial Intelligence is emerging. However, the intrinsic mechanisms and decision transparency of QNNs remain unclear. In this paper, we propose a classic-quantum hybrid network framework (CQH-Net), which uses traditional machine learning methods for feature extraction and quantizes neural networks for classification tasks. We apply CQH-Net to image classification on public datasets. Experimentally, CQH-Net achieves an average convergence rate improvement of 72.8% compared to classical convolutional networks (CNNs) with identical parameters. On the Fashion MNIST dataset, it reaches a final accuracy of 99.02%, representing a significant increase of 5.07% over CNNs. Furthermore, we explore visual explanations for CQH-Net's decision-making process. Results show that the model effectively captures key data features during training and establishes associations between these features and their corresponding categories. This study demonstrates that quantization enhances the models ability to tackle complex classification problems while providing transparency in its decision-making process further supporting quantum advantages in machine learning.
HeteroSample: Meta-path Guided Sampling for Heterogeneous Graph Representation Learning
Nov 11, 2024
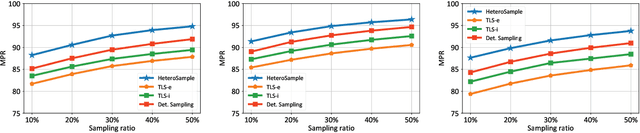
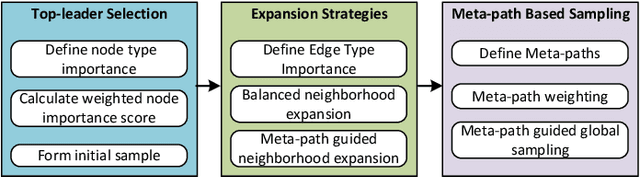
The rapid expansion of Internet of Things (IoT) has resulted in vast, heterogeneous graphs that capture complex interactions among devices, sensors, and systems. Efficient analysis of these graphs is critical for deriving insights in IoT scenarios such as smart cities, industrial IoT, and intelligent transportation systems. However, the scale and diversity of IoT-generated data present significant challenges, and existing methods often struggle with preserving the structural integrity and semantic richness of these complex graphs. Many current approaches fail to maintain the balance between computational efficiency and the quality of the insights generated, leading to potential loss of critical information necessary for accurate decision-making in IoT applications. We introduce HeteroSample, a novel sampling method designed to address these challenges by preserving the structural integrity, node and edge type distributions, and semantic patterns of IoT-related graphs. HeteroSample works by incorporating the novel top-leader selection, balanced neighborhood expansion, and meta-path guided sampling strategies. The key idea is to leverage the inherent heterogeneous structure and semantic relationships encoded by meta-paths to guide the sampling process. This approach ensures that the resulting subgraphs are representative of the original data while significantly reducing computational overhead. Extensive experiments demonstrate that HeteroSample outperforms state-of-the-art methods, achieving up to 15% higher F1 scores in tasks such as link prediction and node classification, while reducing runtime by 20%.These advantages make HeteroSample a transformative tool for scalable and accurate IoT applications, enabling more effective and efficient analysis of complex IoT systems, ultimately driving advancements in smart cities, industrial IoT, and beyond.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024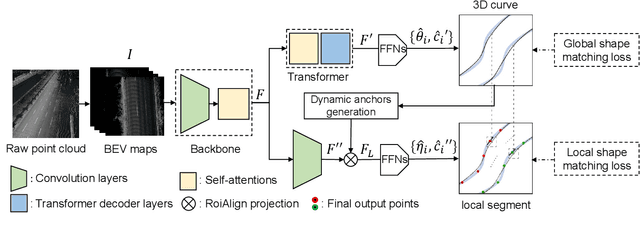
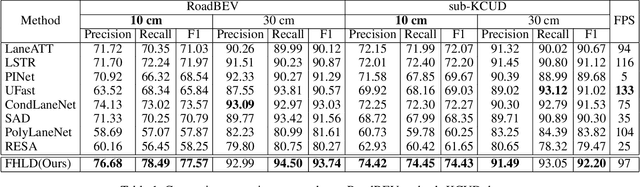
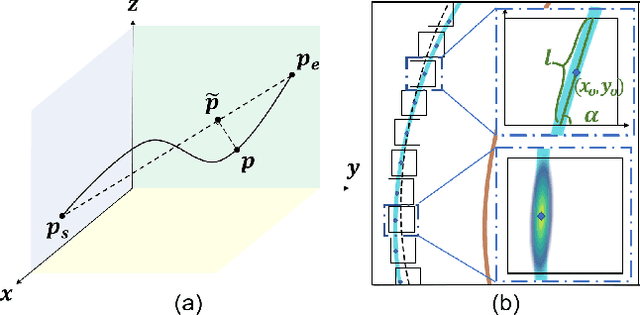
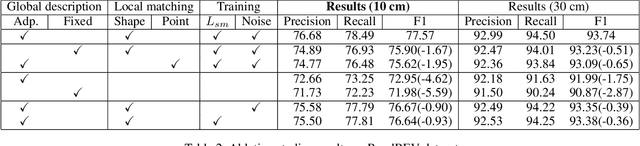
As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.