 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaReTS: A Multi-Task Framework Unifying Classification and Regression for Time Series Forecasting
Nov 12, 2025Recent advances in deep forecasting models have achieved remarkable performance, yet most approaches still struggle to provide both accurate predictions and interpretable insights into temporal dynamics. This paper proposes CaReTS, a novel multi-task learning framework that combines classification and regression tasks for multi-step time series forecasting problems. The framework adopts a dual-stream architecture, where a classification branch learns the stepwise trend into the future, while a regression branch estimates the corresponding deviations from the latest observation of the target variable. The dual-stream design provides more interpretable predictions by disentangling macro-level trends from micro-level deviations in the target variable. To enable effective learning in output prediction, deviation estimation, and trend classification, we design a multi-task loss with uncertainty-aware weighting to adaptively balance the contribution of each task. Furthermore, four variants (CaReTS1--4) are instantiated under this framework to incorporate mainstream temporal modelling encoders, including convolutional neural networks (CNNs), long short-term memory networks (LSTMs), and Transformers. Experiments on real-world datasets demonstrate that CaReTS outperforms state-of-the-art (SOTA) algorithms in forecasting accuracy, while achieving higher trend classification performance.
RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
Jun 16, 2025



Accurate road topology reasoning is critical for autonomous driving, enabling effective navigation and adherence to traffic regulations. Central to this task are lane perception and topology reasoning. However, existing methods typically focus on either lane detection or Lane-to-Lane (L2L) topology reasoning, often \textit{neglecting} Lane-to-Traffic-element (L2T) relationships or \textit{failing} to optimize these tasks jointly. Furthermore, most approaches either overlook relational modeling or apply it in a limited scope, despite the inherent spatial relationships among road elements. We argue that relational modeling is beneficial for both perception and reasoning, as humans naturally leverage contextual relationships for road element recognition and their connectivity inference. To this end, we introduce relational modeling into both perception and reasoning, \textit{jointly} enhancing structural understanding. Specifically, we propose: 1) a relation-aware lane detector, where our geometry-biased self-attention and \curve\ cross-attention refine lane representations by capturing relational dependencies; 2) relation-enhanced topology heads, including a geometry-enhanced L2L head and a cross-view L2T head, boosting reasoning with relational cues; and 3) a contrastive learning strategy with InfoNCE loss to regularize relationship embeddings. Extensive experiments on OpenLane-V2 demonstrate that our approach significantly improves both detection and topology reasoning metrics, achieving +3.1 in DET$_l$, +5.3 in TOP$_{ll}$, +4.9 in TOP$_{lt}$, and an overall +4.4 in OLS, setting a new state-of-the-art. Code will be released.
Topo2Seq: Enhanced Topology Reasoning via Topology Sequence Learning
Feb 13, 2025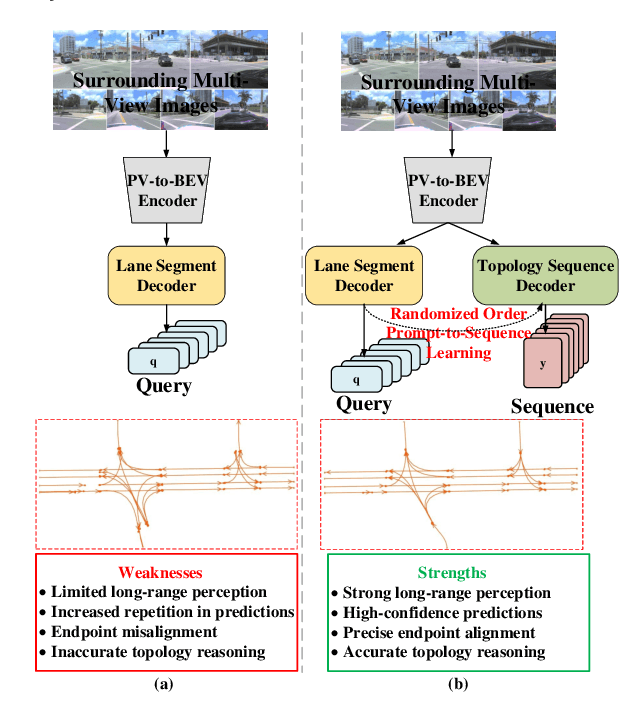
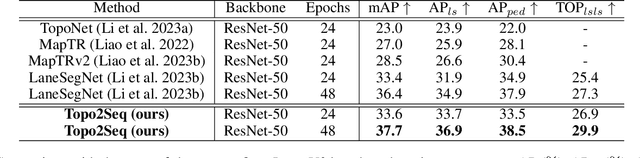
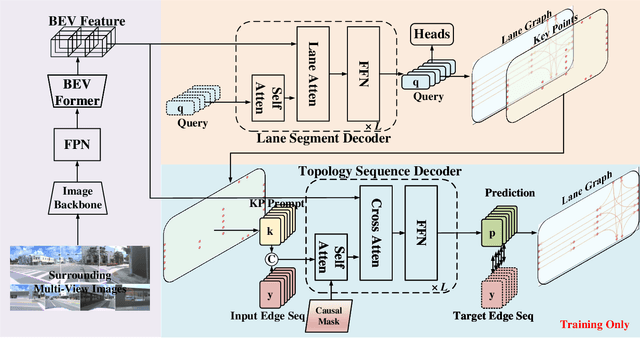
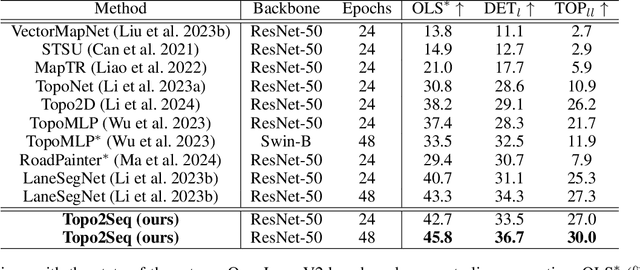
Extracting lane topology from perspective views (PV) is crucial for planning and control in autonomous driving. This approach extracts potential drivable trajectories for self-driving vehicles without relying on high-definition (HD) maps. However, the unordered nature and weak long-range perception of the DETR-like framework can result in misaligned segment endpoints and limited topological prediction capabilities. Inspired by the learning of contextual relationships in language models, the connectivity relations in roads can be characterized as explicit topology sequences. In this paper, we introduce Topo2Seq, a novel approach for enhancing topology reasoning via topology sequences learning. The core concept of Topo2Seq is a randomized order prompt-to-sequence learning between lane segment decoder and topology sequence decoder. The dual-decoder branches simultaneously learn the lane topology sequences extracted from the Directed Acyclic Graph (DAG) and the lane graph containing geometric information. Randomized order prompt-to-sequence learning extracts unordered key points from the lane graph predicted by the lane segment decoder, which are then fed into the prompt design of the topology sequence decoder to reconstruct an ordered and complete lane graph. In this way, the lane segment decoder learns powerful long-range perception and accurate topological reasoning from the topology sequence decoder. Notably, topology sequence decoder is only introduced during training and does not affect the inference efficiency. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of Topo2Seq in topology reasoning.
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024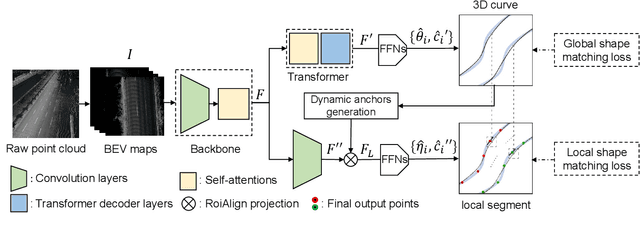
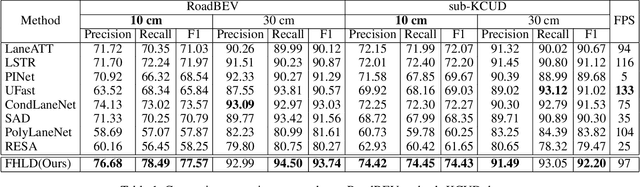
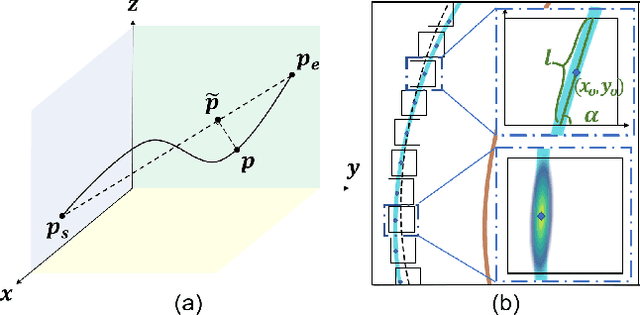
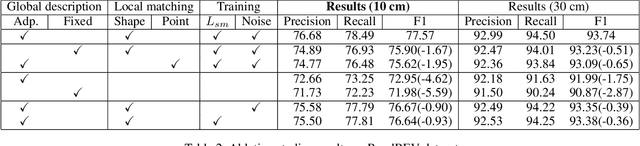
As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


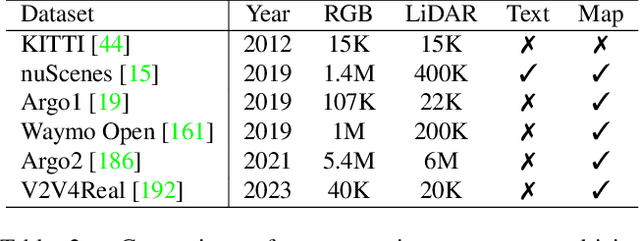
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023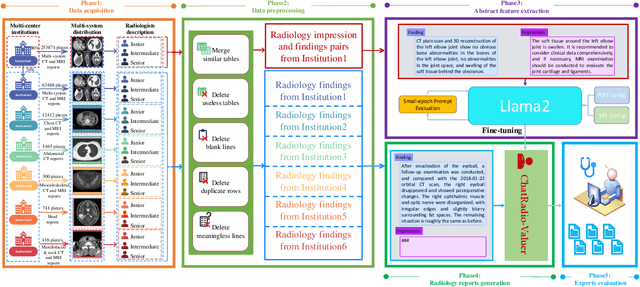
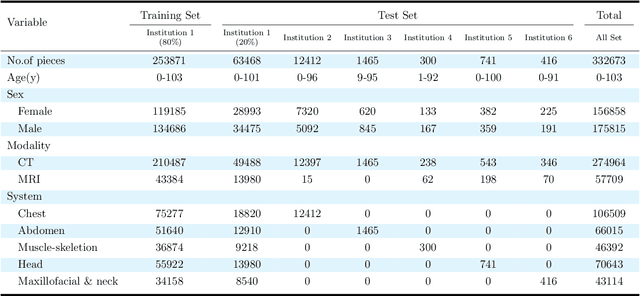
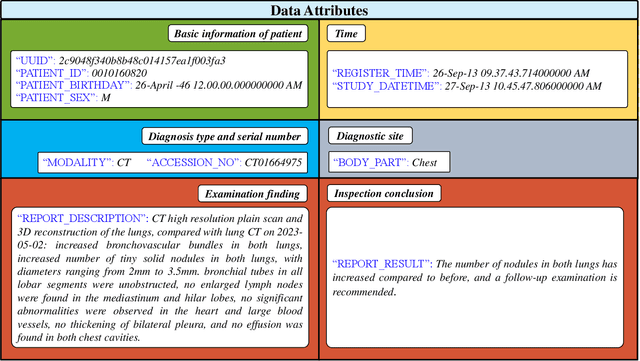
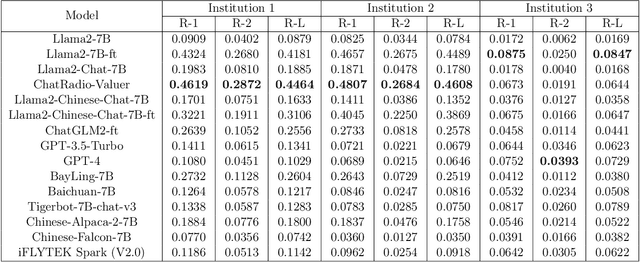
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 20, 2023



3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo, realistic OpenLane and ONCE-3DLanes by large margins (e.g., 11.4 gain in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR .
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.
M^2-3DLaneNet: Multi-Modal 3D Lane Detection
Sep 20, 2022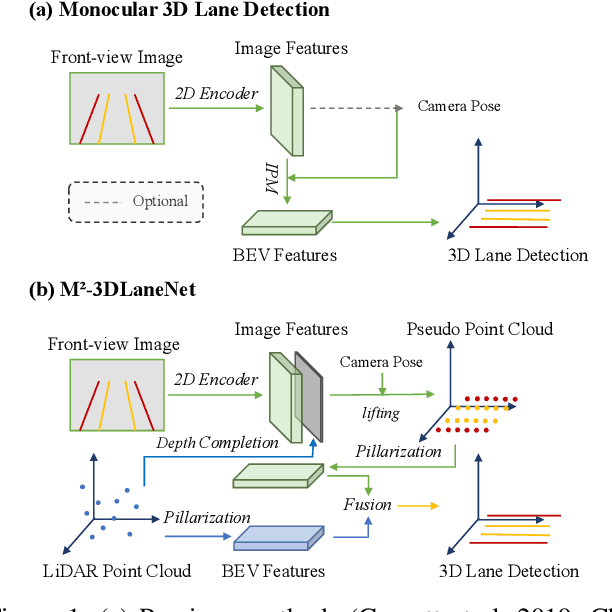
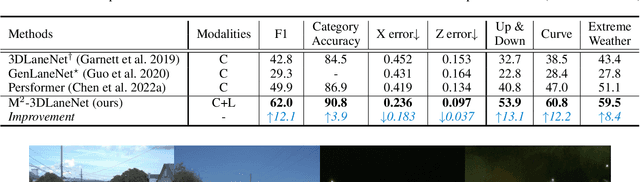
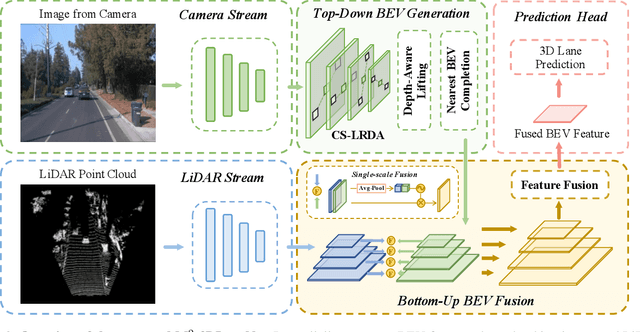
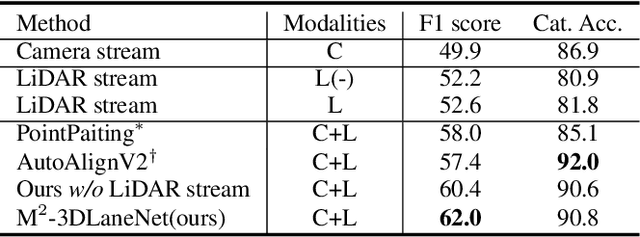
Estimating accurate lane lines in 3D space remains challenging due to their sparse and slim nature. In this work, we propose the M^2-3DLaneNet, a Multi-Modal framework for effective 3D lane detection. Aiming at integrating complementary information from multi-sensors, M^2-3DLaneNet first extracts multi-modal features with modal-specific backbones, then fuses them in a unified Bird's-Eye View (BEV) space. Specifically, our method consists of two core components. 1) To achieve accurate 2D-3D mapping, we propose the top-down BEV generation. Within it, a Line-Restricted Deform-Attention (LRDA) module is utilized to effectively enhance image features in a top-down manner, fully capturing the slenderness features of lanes. After that, it casts the 2D pyramidal features into 3D space using depth-aware lifting and generates BEV features through pillarization. 2) We further propose the bottom-up BEV fusion, which aggregates multi-modal features through multi-scale cascaded attention, integrating complementary information from camera and LiDAR sensors. Sufficient experiments demonstrate the effectiveness of M^2-3DLaneNet, which outperforms previous state-of-the-art methods by a large margin, i.e., 12.1% F1-score improvement on OpenLane dataset.
2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds
Jul 10, 2022
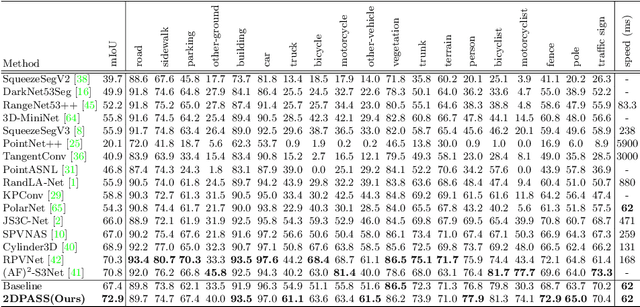
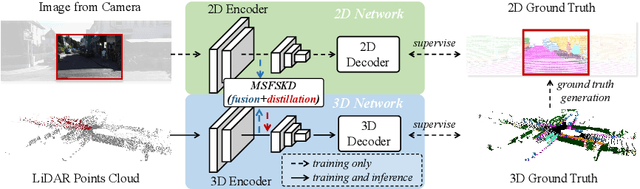
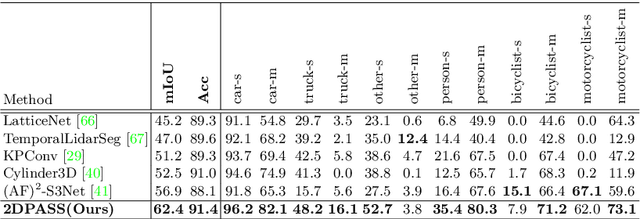
As camera and LiDAR sensors capture complementary information used in autonomous driving, great efforts have been made to develop semantic segmentation algorithms through multi-modality data fusion. However, fusion-based approaches require paired data, i.e., LiDAR point clouds and camera images with strict point-to-pixel mappings, as the inputs in both training and inference, which seriously hinders their application in practical scenarios. Thus, in this work, we propose the 2D Priors Assisted Semantic Segmentation (2DPASS), a general training scheme, to boost the representation learning on point clouds, by fully taking advantage of 2D images with rich appearance. In practice, by leveraging an auxiliary modal fusion and multi-scale fusion-to-single knowledge distillation (MSFSKD), 2DPASS acquires richer semantic and structural information from the multi-modal data, which are then online distilled to the pure 3D network. As a result, equipped with 2DPASS, our baseline shows significant improvement with only point cloud inputs. Specifically, it achieves the state-of-the-arts on two large-scale benchmarks (i.e. SemanticKITTI and NuScenes), including top-1 results in both single and multiple scan(s) competitions of SemanticKITTI.