 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds
Jul 10, 2022
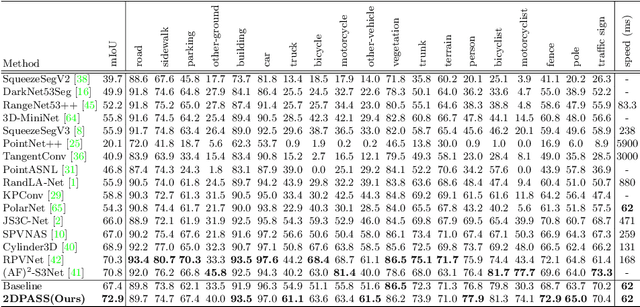
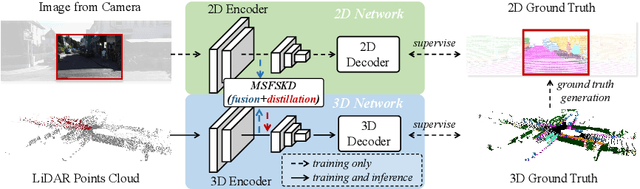
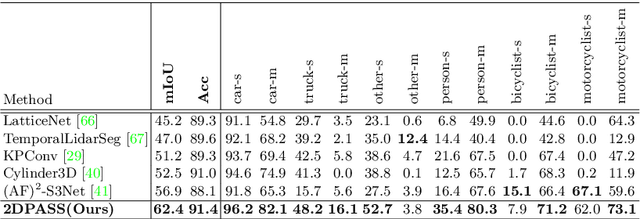
As camera and LiDAR sensors capture complementary information used in autonomous driving, great efforts have been made to develop semantic segmentation algorithms through multi-modality data fusion. However, fusion-based approaches require paired data, i.e., LiDAR point clouds and camera images with strict point-to-pixel mappings, as the inputs in both training and inference, which seriously hinders their application in practical scenarios. Thus, in this work, we propose the 2D Priors Assisted Semantic Segmentation (2DPASS), a general training scheme, to boost the representation learning on point clouds, by fully taking advantage of 2D images with rich appearance. In practice, by leveraging an auxiliary modal fusion and multi-scale fusion-to-single knowledge distillation (MSFSKD), 2DPASS acquires richer semantic and structural information from the multi-modal data, which are then online distilled to the pure 3D network. As a result, equipped with 2DPASS, our baseline shows significant improvement with only point cloud inputs. Specifically, it achieves the state-of-the-arts on two large-scale benchmarks (i.e. SemanticKITTI and NuScenes), including top-1 results in both single and multiple scan(s) competitions of SemanticKITTI.