 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLWM: Dual Latent World Models enable Holistic Gaussian-centric Pre-training in Autonomous Driving
Apr 01, 2026Vision-based autonomous driving has gained much attention due to its low costs and excellent performance. Compared with dense BEV (Bird's Eye View) or sparse query models, Gaussian-centric method is a comprehensive yet sparse representation by describing scene with 3D semantic Gaussians. In this paper, we introduce DLWM, a novel paradigm with Dual Latent World Models specifically designed to enable holistic gaussian-centric pre-training in autonomous driving using two stages. In the first stage, DLWM predicts 3D Gaussians from queries by self-supervised reconstructing multi-view semantic and depth images. Equipped with fine-grained contextual features, in the second stage, two latent world models are trained separately for temporal feature learning, including Gaussian-flow-guided latent prediction for downstream occupancy perception and forecasting tasks, and ego-planning-guided latent prediction for motion planning. Extensive experiments in SurroundOcc and nuScenes benchmarks demonstrate that DLWM shows significant performance gains across Gaussian-centric 3D occupancy perception, 4D occupancy forecasting and motion planning tasks.
DualCoT-VLA: Visual-Linguistic Chain of Thought via Parallel Reasoning for Vision-Language-Action Models
Mar 23, 2026Vision-Language-Action (VLA) models map visual observations and language instructions directly to robotic actions. While effective for simple tasks, standard VLA models often struggle with complex, multi-step tasks requiring logical planning, as well as precise manipulations demanding fine-grained spatial perception. Recent efforts have incorporated Chain-of-Thought (CoT) reasoning to endow VLA models with a ``thinking before acting'' capability. However, current CoT-based VLA models face two critical limitations: 1) an inability to simultaneously capture low-level visual details and high-level logical planning due to their reliance on isolated, single-modal CoT; 2) high inference latency with compounding errors caused by step-by-step autoregressive decoding. To address these limitations, we propose DualCoT-VLA, a visual-linguistic CoT method for VLA models with a parallel reasoning mechanism. To achieve comprehensive multi-modal reasoning, our method integrates a visual CoT for low-level spatial understanding and a linguistic CoT for high-level task planning. Furthermore, to overcome the latency bottleneck, we introduce a parallel CoT mechanism that incorporates two sets of learnable query tokens, shifting autoregressive reasoning to single-step forward reasoning. Extensive experiments demonstrate that our DualCoT-VLA achieves state-of-the-art performance on the LIBERO and RoboCasa GR1 benchmarks, as well as in real-world platforms.
VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Nov 22, 2024



This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024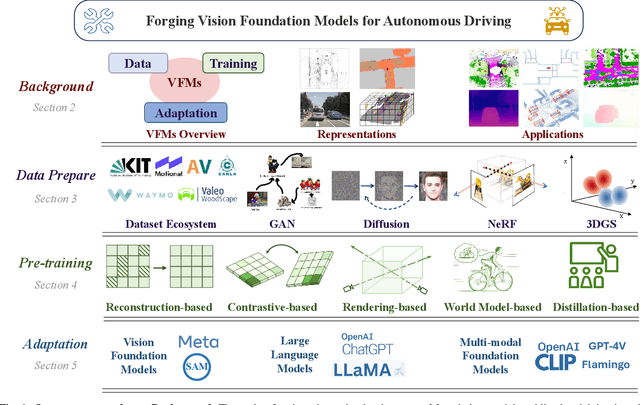
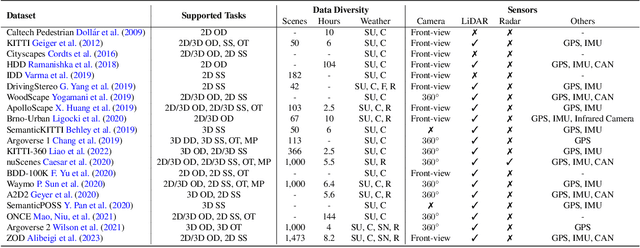
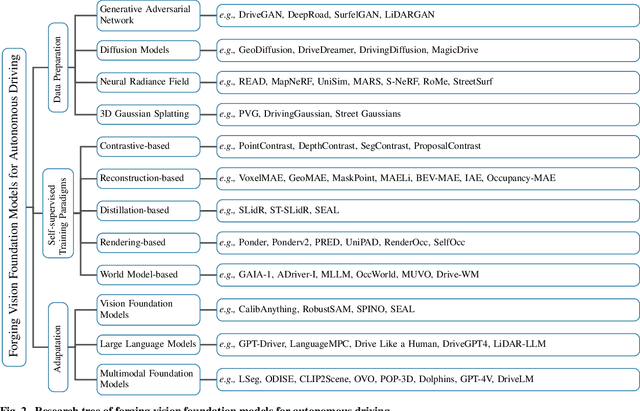

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Dec 19, 2023



3D occupancy prediction is an emerging task that aims to estimate the occupancy states and semantics of 3D scenes using multi-view images. However, image-based scene perception encounters significant challenges in achieving accurate prediction due to the absence of geometric priors. In this paper, we address this issue by exploring cross-modal knowledge distillation in this task, i.e., we leverage a stronger multi-modal model to guide the visual model during training. In practice, we observe that directly applying features or logits alignment, proposed and widely used in bird's-eyeview (BEV) perception, does not yield satisfactory results. To overcome this problem, we introduce RadOcc, a Rendering assisted distillation paradigm for 3D Occupancy prediction. By employing differentiable volume rendering, we generate depth and semantic maps in perspective views and propose two novel consistency criteria between the rendered outputs of teacher and student models. Specifically, the depth consistency loss aligns the termination distributions of the rendered rays, while the semantic consistency loss mimics the intra-segment similarity guided by vision foundation models (VLMs). Experimental results on the nuScenes dataset demonstrate the effectiveness of our proposed method in improving various 3D occupancy prediction approaches, e.g., our proposed methodology enhances our baseline by 2.2% in the metric of mIoU and achieves 50% in Occ3D benchmark.
Let Images Give You More:Point Cloud Cross-Modal Training for Shape Analysis
Oct 09, 2022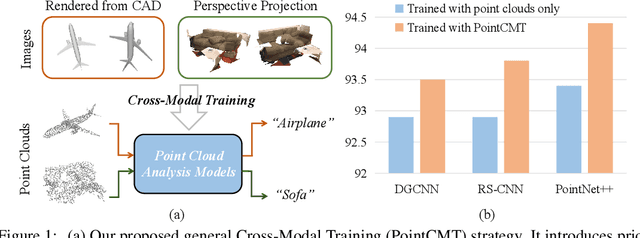
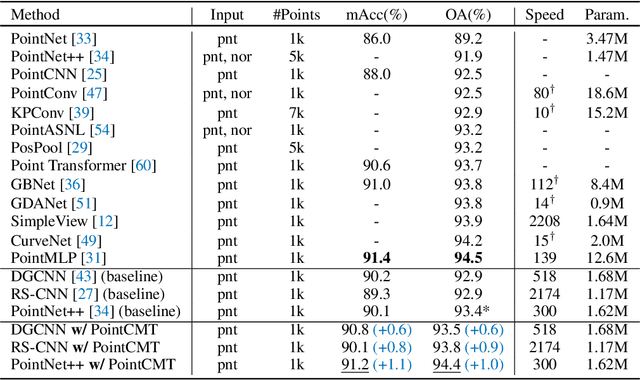
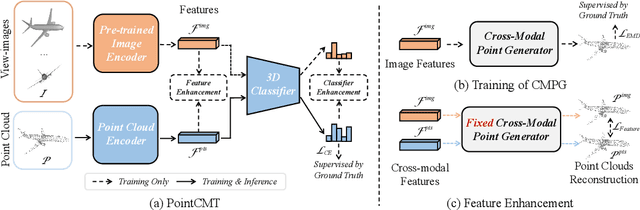
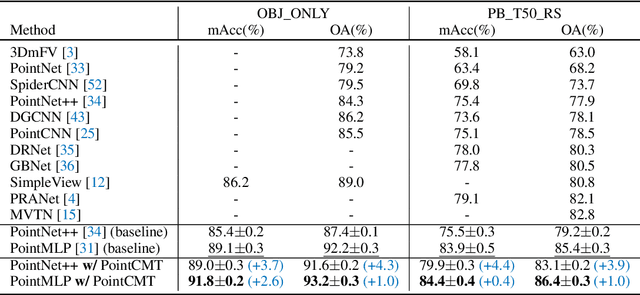
Although recent point cloud analysis achieves impressive progress, the paradigm of representation learning from a single modality gradually meets its bottleneck. In this work, we take a step towards more discriminative 3D point cloud representation by fully taking advantages of images which inherently contain richer appearance information, e.g., texture, color, and shade. Specifically, this paper introduces a simple but effective point cloud cross-modality training (PointCMT) strategy, which utilizes view-images, i.e., rendered or projected 2D images of the 3D object, to boost point cloud analysis. In practice, to effectively acquire auxiliary knowledge from view images, we develop a teacher-student framework and formulate the cross modal learning as a knowledge distillation problem. PointCMT eliminates the distribution discrepancy between different modalities through novel feature and classifier enhancement criteria and avoids potential negative transfer effectively. Note that PointCMT effectively improves the point-only representation without architecture modification. Sufficient experiments verify significant gains on various datasets using appealing backbones, i.e., equipped with PointCMT, PointNet++ and PointMLP achieve state-of-the-art performance on two benchmarks, i.e., 94.4% and 86.7% accuracy on ModelNet40 and ScanObjectNN, respectively. Code will be made available at https://github.com/ZhanHeshen/PointCMT.
2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds
Jul 10, 2022
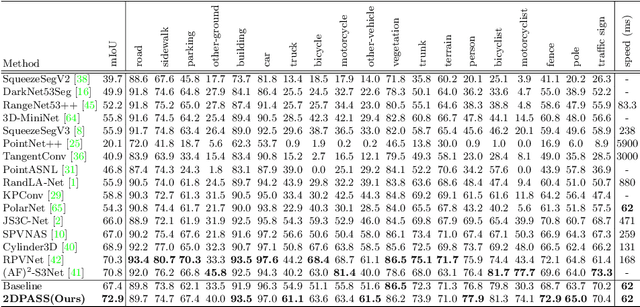
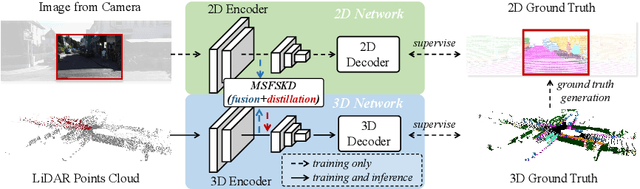
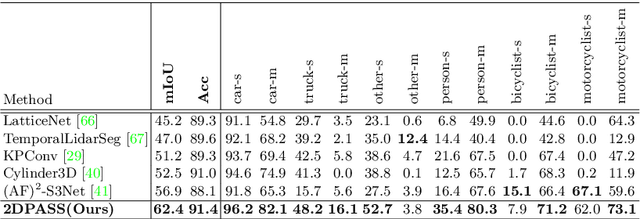
As camera and LiDAR sensors capture complementary information used in autonomous driving, great efforts have been made to develop semantic segmentation algorithms through multi-modality data fusion. However, fusion-based approaches require paired data, i.e., LiDAR point clouds and camera images with strict point-to-pixel mappings, as the inputs in both training and inference, which seriously hinders their application in practical scenarios. Thus, in this work, we propose the 2D Priors Assisted Semantic Segmentation (2DPASS), a general training scheme, to boost the representation learning on point clouds, by fully taking advantage of 2D images with rich appearance. In practice, by leveraging an auxiliary modal fusion and multi-scale fusion-to-single knowledge distillation (MSFSKD), 2DPASS acquires richer semantic and structural information from the multi-modal data, which are then online distilled to the pure 3D network. As a result, equipped with 2DPASS, our baseline shows significant improvement with only point cloud inputs. Specifically, it achieves the state-of-the-arts on two large-scale benchmarks (i.e. SemanticKITTI and NuScenes), including top-1 results in both single and multiple scan(s) competitions of SemanticKITTI.
Box-Aware Feature Enhancement for Single Object Tracking on Point Clouds
Aug 10, 2021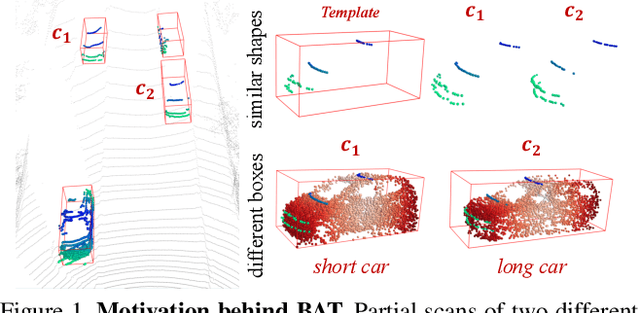
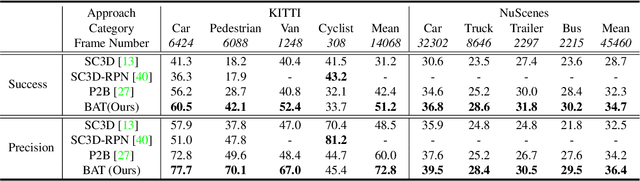
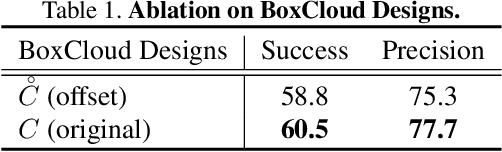
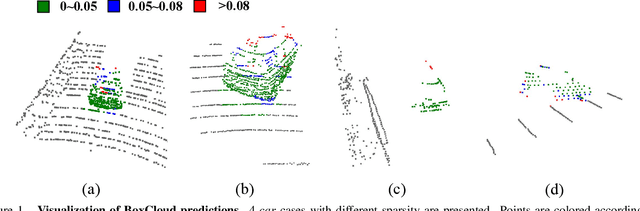
Current 3D single object tracking approaches track the target based on a feature comparison between the target template and the search area. However, due to the common occlusion in LiDAR scans, it is non-trivial to conduct accurate feature comparisons on severe sparse and incomplete shapes. In this work, we exploit the ground truth bounding box given in the first frame as a strong cue to enhance the feature description of the target object, enabling a more accurate feature comparison in a simple yet effective way. In particular, we first propose the BoxCloud, an informative and robust representation, to depict an object using the point-to-box relation. We further design an efficient box-aware feature fusion module, which leverages the aforementioned BoxCloud for reliable feature matching and embedding. Integrating the proposed general components into an existing model P2B, we construct a superior box-aware tracker (BAT). Experiments confirm that our proposed BAT outperforms the previous state-of-the-art by a large margin on both KITTI and NuScenes benchmarks, achieving a 12.8% improvement in terms of precision while running ~20% faster.
PointLIE: Locally Invertible Embedding for Point Cloud Sampling and Recovery
Apr 30, 2021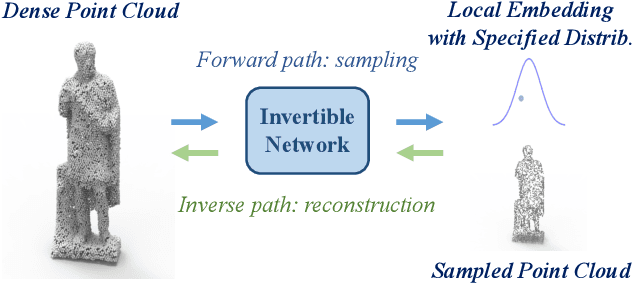
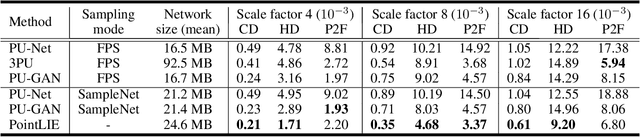
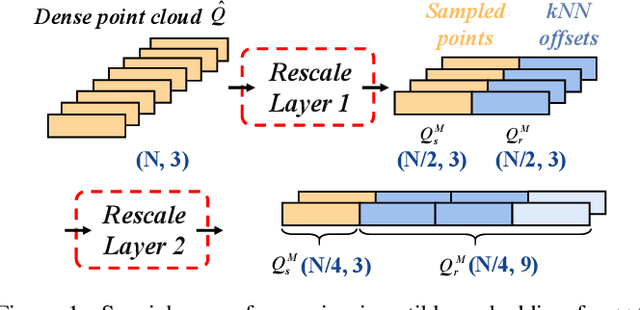
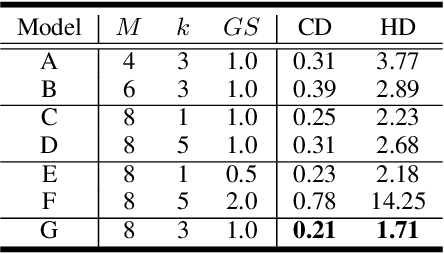
Point Cloud Sampling and Recovery (PCSR) is critical for massive real-time point cloud collection and processing since raw data usually requires large storage and computation. In this paper, we address a fundamental problem in PCSR: How to downsample the dense point cloud with arbitrary scales while preserving the local topology of discarding points in a case-agnostic manner (i.e. without additional storage for point relationship)? We propose a novel Locally Invertible Embedding for point cloud adaptive sampling and recovery (PointLIE). Instead of learning to predict the underlying geometry details in a seemingly plausible manner, PointLIE unifies point cloud sampling and upsampling to one single framework through bi-directional learning. Specifically, PointLIE recursively samples and adjusts neighboring points on each scale. Then it encodes the neighboring offsets of sampled points to a latent space and thus decouples the sampled points and the corresponding local geometric relationship. Once the latent space is determined and that the deep model is optimized, the recovery process could be conducted by passing the recover-pleasing sampled points and a randomly-drawn embedding to the same network through an invertible operation. Such a scheme could guarantee the fidelity of dense point recovery from sampled points. Extensive experiments demonstrate that the proposed PointLIE outperforms state-of-the-arts both quantitatively and qualitatively. Our code is released through https://github.com/zwb0/PointLIE.
* To appear in IJCAI 2021
Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion
Dec 07, 2020
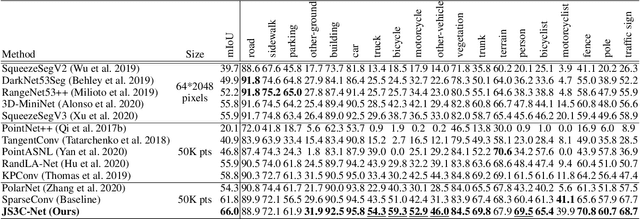
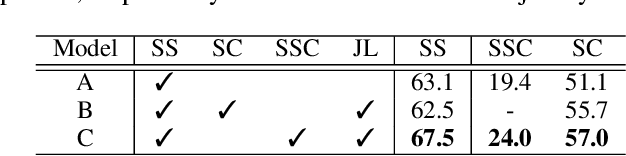
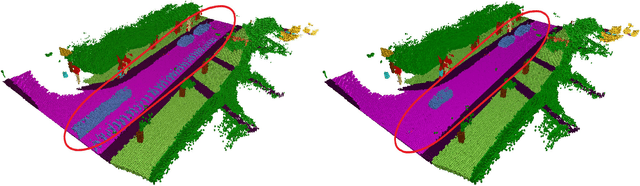
LiDAR point cloud analysis is a core task for 3D computer vision, especially for autonomous driving. However, due to the severe sparsity and noise interference in the single sweep LiDAR point cloud, the accurate semantic segmentation is non-trivial to achieve. In this paper, we propose a novel sparse LiDAR point cloud semantic segmentation framework assisted by learned contextual shape priors. In practice, an initial semantic segmentation (SS) of a single sweep point cloud can be achieved by any appealing network and then flows into the semantic scene completion (SSC) module as the input. By merging multiple frames in the LiDAR sequence as supervision, the optimized SSC module has learned the contextual shape priors from sequential LiDAR data, completing the sparse single sweep point cloud to the dense one. Thus, it inherently improves SS optimization through fully end-to-end training. Besides, a Point-Voxel Interaction (PVI) module is proposed to further enhance the knowledge fusion between SS and SSC tasks, i.e., promoting the interaction of incomplete local geometry of point cloud and complete voxel-wise global structure. Furthermore, the auxiliary SSC and PVI modules can be discarded during inference without extra burden for SS. Extensive experiments confirm that our JS3C-Net achieves superior performance on both SemanticKITTI and SemanticPOSS benchmarks, i.e., 4% and 3% improvement correspondingly.