 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLWM: Dual Latent World Models enable Holistic Gaussian-centric Pre-training in Autonomous Driving
Apr 01, 2026Vision-based autonomous driving has gained much attention due to its low costs and excellent performance. Compared with dense BEV (Bird's Eye View) or sparse query models, Gaussian-centric method is a comprehensive yet sparse representation by describing scene with 3D semantic Gaussians. In this paper, we introduce DLWM, a novel paradigm with Dual Latent World Models specifically designed to enable holistic gaussian-centric pre-training in autonomous driving using two stages. In the first stage, DLWM predicts 3D Gaussians from queries by self-supervised reconstructing multi-view semantic and depth images. Equipped with fine-grained contextual features, in the second stage, two latent world models are trained separately for temporal feature learning, including Gaussian-flow-guided latent prediction for downstream occupancy perception and forecasting tasks, and ego-planning-guided latent prediction for motion planning. Extensive experiments in SurroundOcc and nuScenes benchmarks demonstrate that DLWM shows significant performance gains across Gaussian-centric 3D occupancy perception, 4D occupancy forecasting and motion planning tasks.
VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Nov 22, 2024



This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
Geometry-Aware Network for Domain Adaptive Semantic Segmentation
Dec 05, 2022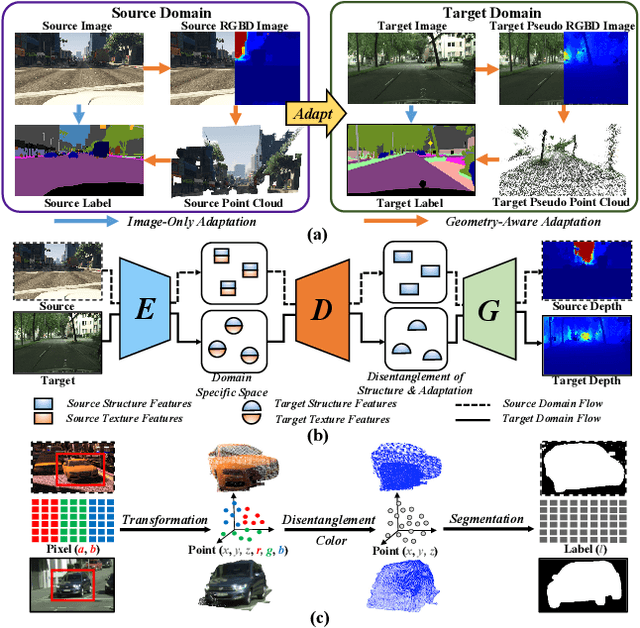

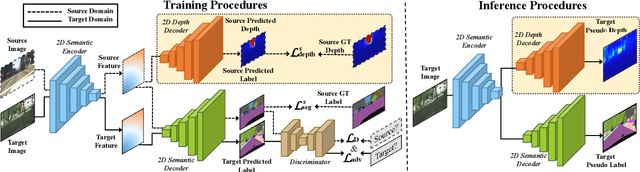

Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.
Dynamic Spatial Propagation Network for Depth Completion
Feb 20, 2022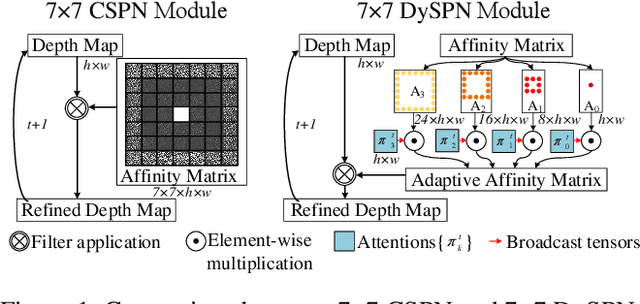
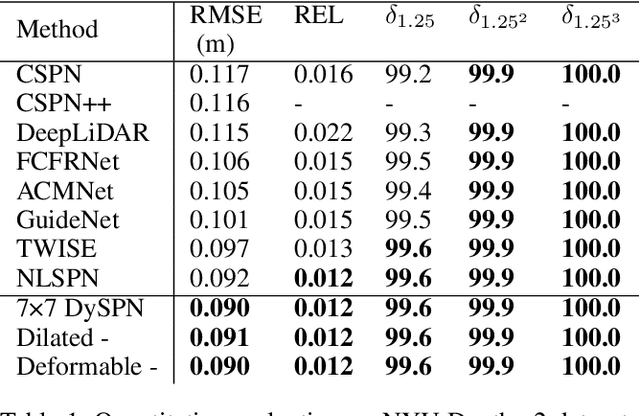
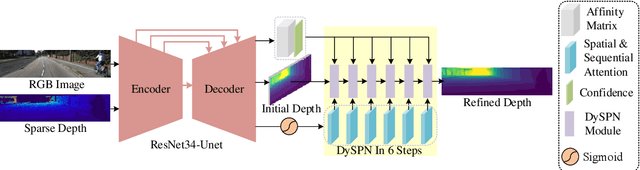
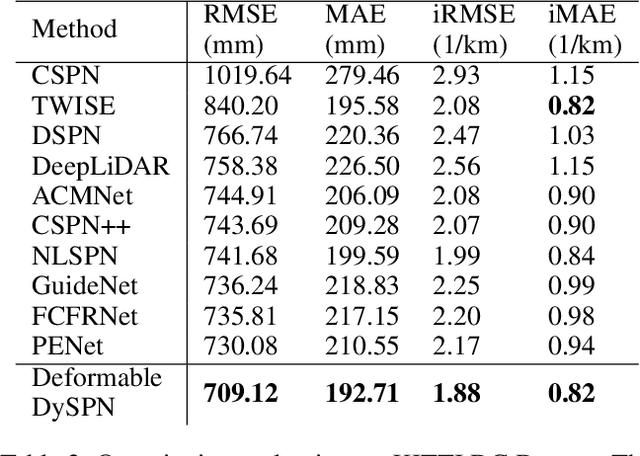
Image-guided depth completion aims to generate dense depth maps with sparse depth measurements and corresponding RGB images. Currently, spatial propagation networks (SPNs) are the most popular affinity-based methods in depth completion, but they still suffer from the representation limitation of the fixed affinity and the over smoothing during iterations. Our solution is to estimate independent affinity matrices in each SPN iteration, but it is over-parameterized and heavy calculation. This paper introduces an efficient model that learns the affinity among neighboring pixels with an attention-based, dynamic approach. Specifically, the Dynamic Spatial Propagation Network (DySPN) we proposed makes use of a non-linear propagation model (NLPM). It decouples the neighborhood into parts regarding to different distances and recursively generates independent attention maps to refine these parts into adaptive affinity matrices. Furthermore, we adopt a diffusion suppression (DS) operation so that the model converges at an early stage to prevent over-smoothing of dense depth. Finally, in order to decrease the computational cost required, we also introduce three variations that reduce the amount of neighbors and attentions needed while still retaining similar accuracy. In practice, our method requires less iteration to match the performance of other SPNs and yields better results overall. DySPN outperforms other state-of-the-art (SoTA) methods on KITTI Depth Completion (DC) evaluation by the time of submission and is able to yield SoTA performance in NYU Depth v2 dataset as well.