 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-GenRM: Personalized Generative Reward Model with Test-time User-based Scaling
Feb 12, 2026Personalized alignment of large language models seeks to adapt responses to individual user preferences, typically via reinforcement learning. A key challenge is obtaining accurate, user-specific reward signals in open-ended scenarios. Existing personalized reward models face two persistent limitations: (1) oversimplifying diverse, scenario-specific preferences into a small, fixed set of evaluation principles, and (2) struggling with generalization to new users with limited feedback. To this end, we propose P-GenRM, the first Personalized Generative Reward Model with test-time user-based scaling. P-GenRM transforms preference signals into structured evaluation chains that derive adaptive personas and scoring rubrics across various scenarios. It further clusters users into User Prototypes and introduces a dual-granularity scaling mechanism: at the individual level, it adaptively scales and aggregates each user's scoring scheme; at the prototype level, it incorporates preferences from similar users. This design mitigates noise in inferred preferences and enhances generalization to unseen users through prototype-based transfer. Empirical results show that P-GenRM achieves state-of-the-art results on widely-used personalized reward model benchmarks, with an average improvement of 2.31%, and demonstrates strong generalization on an out-of-distribution dataset. Notably, Test-time User-based scaling provides an additional 3% boost, demonstrating stronger personalized alignment with test-time scalability.
SAL: Selective Adaptive Learning for Backpropagation-Free Training with Sparsification
Jan 29, 2026Standard deep learning relies on Backpropagation (BP), which is constrained by biologically implausible weight symmetry and suffers from significant gradient interference within dense representations. To mitigate these bottlenecks, we propose Selective Adaptive Learning (SAL), a training method that combines selective parameter activation with adaptive area partitioning. Specifically, SAL decomposes the parameter space into mutually exclusive, sample-dependent regions. This decoupling mitigates gradient interference across divergent semantic patterns and addresses explicit weight symmetry requirements through our refined feedback alignment. Empirically, SAL demonstrates competitive convergence rates, leading to improved classification performance across 10 standard benchmarks. Additionally, SAL achieves numerical consistency and competitive accuracy even in deep regimes (up to 128 layers) and large-scale models (up to 1B parameters). Our approach is loosely inspired by biological learning mechanisms, offering a plausible alternative that contributes to the study of scalable neural network training.
How Do Semantically Equivalent Code Transformations Impact Membership Inference on LLMs for Code?
Dec 17, 2025The success of large language models for code relies on vast amounts of code data, including public open-source repositories, such as GitHub, and private, confidential code from companies. This raises concerns about intellectual property compliance and the potential unauthorized use of license-restricted code. While membership inference (MI) techniques have been proposed to detect such unauthorized usage, their effectiveness can be undermined by semantically equivalent code transformation techniques, which modify code syntax while preserving semantic. In this work, we systematically investigate whether semantically equivalent code transformation rules might be leveraged to evade MI detection. The results reveal that model accuracy drops by only 1.5% in the worst case for each rule, demonstrating that transformed datasets can effectively serve as substitutes for fine-tuning. Additionally, we find that one of the rules (RenameVariable) reduces MI success by 10.19%, highlighting its potential to obscure the presence of restricted code. To validate these findings, we conduct a causal analysis confirming that variable renaming has the strongest causal effect in disrupting MI detection. Notably, we find that combining multiple transformations does not further reduce MI effectiveness. Our results expose a critical loophole in license compliance enforcement for training large language models for code, showing that MI detection can be substantially weakened by transformation-based obfuscation techniques.
Understanding Privacy Risks in Code Models Through Training Dynamics: A Causal Approach
Dec 09, 2025Large language models for code (LLM4Code) have greatly improved developer productivity but also raise privacy concerns due to their reliance on open-source repositories containing abundant personally identifiable information (PII). Prior work shows that commercial models can reproduce sensitive PII, yet existing studies largely treat PII as a single category and overlook the heterogeneous risks among different types. We investigate whether distinct PII types vary in their likelihood of being learned and leaked by LLM4Code, and whether this relationship is causal. Our methodology includes building a dataset with diverse PII types, fine-tuning representative models of different scales, computing training dynamics on real PII data, and formulating a structural causal model to estimate the causal effect of learnability on leakage. Results show that leakage risks differ substantially across PII types and correlate with their training dynamics: easy-to-learn instances such as IP addresses exhibit higher leakage, while harder types such as keys and passwords leak less frequently. Ambiguous types show mixed behaviors. This work provides the first causal evidence that leakage risks are type-dependent and offers guidance for developing type-aware and learnability-aware defenses for LLM4Code.
3D Vision-tactile Reconstruction from Infrared and Visible Images for Robotic Fine-grained Tactile Perception
Jun 18, 2025To achieve human-like haptic perception in anthropomorphic grippers, the compliant sensing surfaces of vision tactile sensor (VTS) must evolve from conventional planar configurations to biomimetically curved topographies with continuous surface gradients. However, planar VTSs have challenges when extended to curved surfaces, including insufficient lighting of surfaces, blurring in reconstruction, and complex spatial boundary conditions for surface structures. With an end goal of constructing a human-like fingertip, our research (i) develops GelSplitter3D by expanding imaging channels with a prism and a near-infrared (NIR) camera, (ii) proposes a photometric stereo neural network with a CAD-based normal ground truth generation method to calibrate tactile geometry, and (iii) devises a normal integration method with boundary constraints of depth prior information to correcting the cumulative error of surface integrals. We demonstrate better tactile sensing performance, a 40$\%$ improvement in normal estimation accuracy, and the benefits of sensor shapes in grasping and manipulation tasks.
MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
May 18, 2025Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, limiting their applicability to tasks where historical context is crucial for disambiguating current observations. This limitation hinders performance in long-horizon sequential manipulation tasks where the correct action depends on past events not fully captured by the current state. To address this fundamental challenge, we introduce Mamba Temporal Imitation Learning (MTIL), a novel approach that leverages the recurrent state dynamics inherent in State Space Models (SSMs), specifically the Mamba architecture. MTIL encodes the entire trajectory history into a compressed hidden state, conditioning action predictions on this comprehensive temporal context alongside current multi-modal observations. Through extensive experiments on simulated benchmarks (ACT dataset tasks, Robomimic, LIBERO) and real-world sequential manipulation tasks specifically designed to probe temporal dependencies, MTIL significantly outperforms state-of-the-art methods like ACT and Diffusion Policy. Our findings affirm the necessity of full temporal context for robust sequential decision-making and validate MTIL as a powerful approach that transcends the inherent limitations of Markovian imitation learning
Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing
Apr 03, 2025Large Multi-modality Models (LMMs) have made significant progress in visual understanding and generation, but they still face challenges in General Visual Editing, particularly in following complex instructions, preserving appearance consistency, and supporting flexible input formats. To address this gap, we introduce RISEBench, the first benchmark for evaluating Reasoning-Informed viSual Editing (RISE). RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning. We curate high-quality test cases for each category and propose an evaluation framework that assesses Instruction Reasoning, Appearance Consistency, and Visual Plausibility with both human judges and an LMM-as-a-judge approach. Our experiments reveal that while GPT-4o-Native significantly outperforms other open-source and proprietary models, even this state-of-the-art system struggles with logical reasoning tasks, highlighting an area that remains underexplored. As an initial effort, RISEBench aims to provide foundational insights into reasoning-aware visual editing and to catalyze future research. Though still in its early stages, we are committed to continuously expanding and refining the benchmark to support more comprehensive, reliable, and scalable evaluations of next-generation multimodal systems. Our code and data will be released at https://github.com/PhoenixZ810/RISEBench.
Lightweight Multimodal Artificial Intelligence Framework for Maritime Multi-Scene Recognition
Mar 10, 2025Maritime Multi-Scene Recognition is crucial for enhancing the capabilities of intelligent marine robotics, particularly in applications such as marine conservation, environmental monitoring, and disaster response. However, this task presents significant challenges due to environmental interference, where marine conditions degrade image quality, and the complexity of maritime scenes, which requires deeper reasoning for accurate recognition. Pure vision models alone are insufficient to address these issues. To overcome these limitations, we propose a novel multimodal Artificial Intelligence (AI) framework that integrates image data, textual descriptions and classification vectors generated by a Multimodal Large Language Model (MLLM), to provide richer semantic understanding and improve recognition accuracy. Our framework employs an efficient multimodal fusion mechanism to further enhance model robustness and adaptability in complex maritime environments. Experimental results show that our model achieves 98$\%$ accuracy, surpassing previous SOTA models by 3.5$\%$. To optimize deployment on resource-constrained platforms, we adopt activation-aware weight quantization (AWQ) as a lightweight technique, reducing the model size to 68.75MB with only a 0.5$\%$ accuracy drop while significantly lowering computational overhead. This work provides a high-performance solution for real-time maritime scene recognition, enabling Autonomous Surface Vehicles (ASVs) to support environmental monitoring and disaster response in resource-limited settings.
OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
Feb 25, 2025Recent advancements in open-source multi-modal large language models (MLLMs) have primarily focused on enhancing foundational capabilities, leaving a significant gap in human preference alignment. This paper introduces OmniAlign-V, a comprehensive dataset of 200K high-quality training samples featuring diverse images, complex questions, and varied response formats to improve MLLMs' alignment with human preferences. We also present MM-AlignBench, a human-annotated benchmark specifically designed to evaluate MLLMs' alignment with human values. Experimental results show that finetuning MLLMs with OmniAlign-V, using Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO), significantly enhances human preference alignment while maintaining or enhancing performance on standard VQA benchmarks, preserving their fundamental capabilities. Our datasets, benchmark, code and checkpoints have been released at https://github.com/PhoenixZ810/OmniAlign-V.
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Jun 25, 2024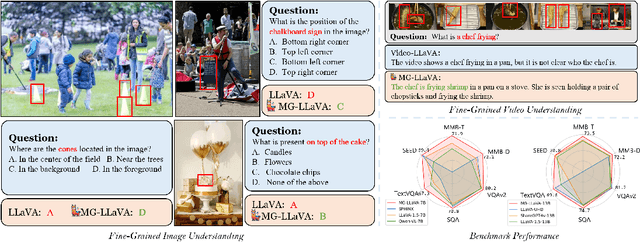
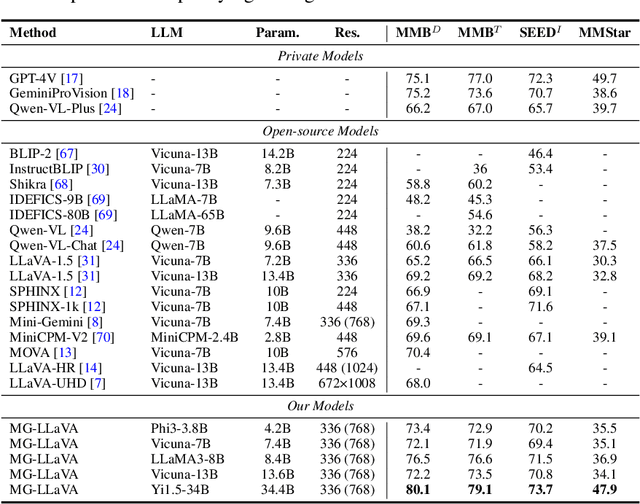
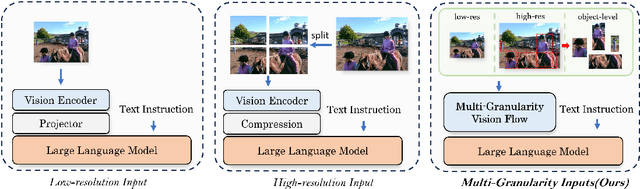
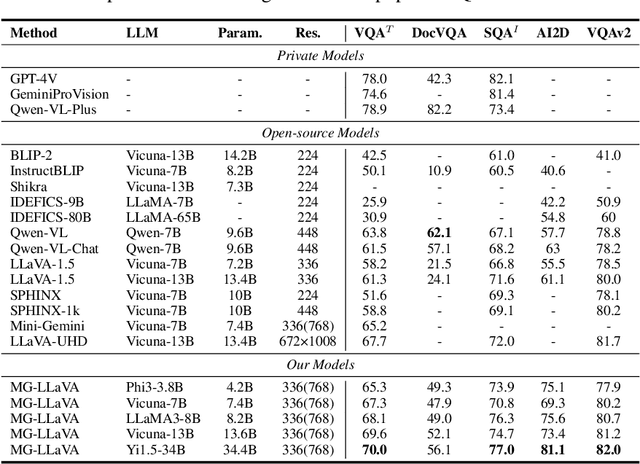
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.