 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Confidence Discrepancy Can Guide Federated Semi-Supervised Learning Across Pseudo-Mismatch
Mar 17, 2025Federated Semi-Supervised Learning (FSSL) aims to leverage unlabeled data across clients with limited labeled data to train a global model with strong generalization ability. Most FSSL methods rely on consistency regularization with pseudo-labels, converting predictions from local or global models into hard pseudo-labels as supervisory signals. However, we discover that the quality of pseudo-label is largely deteriorated by data heterogeneity, an intrinsic facet of federated learning. In this paper, we study the problem of FSSL in-depth and show that (1) heterogeneity exacerbates pseudo-label mismatches, further degrading model performance and convergence, and (2) local and global models' predictive tendencies diverge as heterogeneity increases. Motivated by these findings, we propose a simple and effective method called Semi-supervised Aggregation for Globally-Enhanced Ensemble (SAGE), that can flexibly correct pseudo-labels based on confidence discrepancies. This strategy effectively mitigates performance degradation caused by incorrect pseudo-labels and enhances consensus between local and global models. Experimental results demonstrate that SAGE outperforms existing FSSL methods in both performance and convergence. Our code is available at https://github.com/Jay-Codeman/SAGE
Lightweight Multimodal Artificial Intelligence Framework for Maritime Multi-Scene Recognition
Mar 10, 2025Maritime Multi-Scene Recognition is crucial for enhancing the capabilities of intelligent marine robotics, particularly in applications such as marine conservation, environmental monitoring, and disaster response. However, this task presents significant challenges due to environmental interference, where marine conditions degrade image quality, and the complexity of maritime scenes, which requires deeper reasoning for accurate recognition. Pure vision models alone are insufficient to address these issues. To overcome these limitations, we propose a novel multimodal Artificial Intelligence (AI) framework that integrates image data, textual descriptions and classification vectors generated by a Multimodal Large Language Model (MLLM), to provide richer semantic understanding and improve recognition accuracy. Our framework employs an efficient multimodal fusion mechanism to further enhance model robustness and adaptability in complex maritime environments. Experimental results show that our model achieves 98$\%$ accuracy, surpassing previous SOTA models by 3.5$\%$. To optimize deployment on resource-constrained platforms, we adopt activation-aware weight quantization (AWQ) as a lightweight technique, reducing the model size to 68.75MB with only a 0.5$\%$ accuracy drop while significantly lowering computational overhead. This work provides a high-performance solution for real-time maritime scene recognition, enabling Autonomous Surface Vehicles (ASVs) to support environmental monitoring and disaster response in resource-limited settings.
Movable-Antenna Position Optimization for Physical-Layer Security via Discrete Sampling
Aug 01, 2024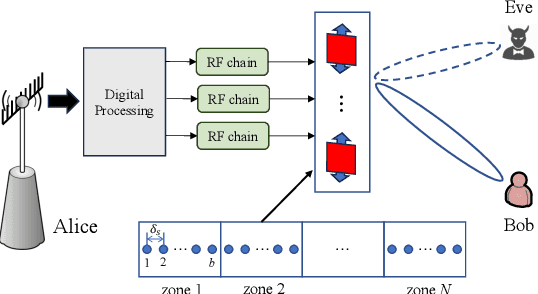
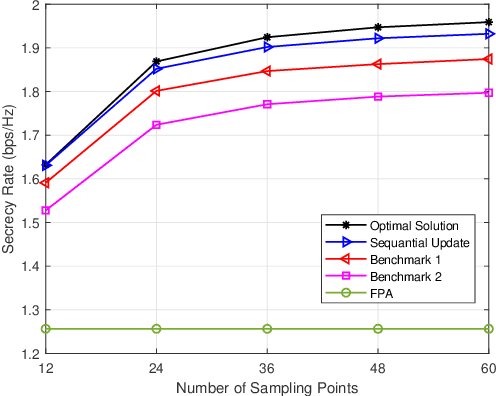
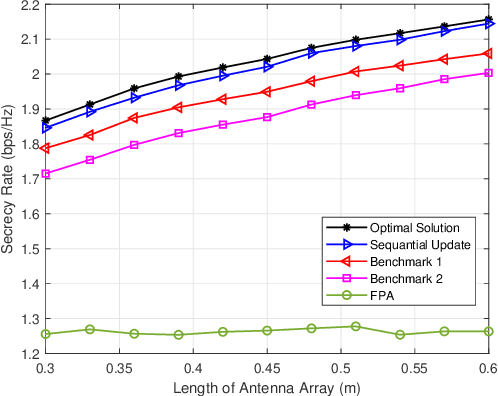
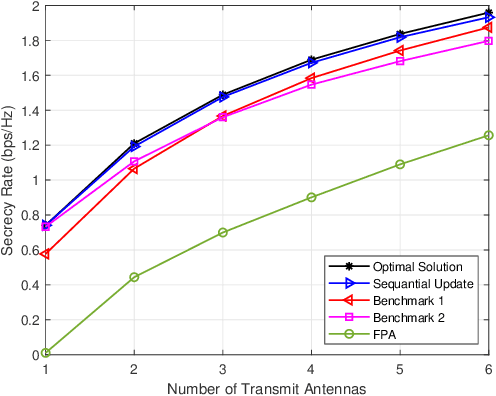
Fluid antennas (FAs) and mobile antennas (MAs) are innovative technologies in wireless communications that are able to proactively improve channel conditions by dynamically adjusting the transmit/receive antenna positions within a given spatial region. In this paper, we investigate an MA-enhanced multiple-input single-output (MISO) secure communication system, aiming to maximize the secrecy rate by jointly optimizing the positions of multiple MAs. Instead of continuously searching for the optimal MA positions as in prior works, we propose to discretize the transmit region into multiple sampling points, thereby converting the continuous antenna position optimization into a discrete sampling point selection problem. However, this point selection problem is combinatory and thus difficult to be optimally solved. To tackle this challenge, we ingeniously transform this combinatory problem into a recursive path selection problem in graph theory and propose a partial enumeration algorithm to obtain its optimal solution without the need for high-complexity exhaustive search. To further reduce the complexity, a linear-time sequential update algorithm is also proposed to obtain a high-quality suboptimal solution. Numerical results show that our proposed algorithms yield much higher secrecy rates as compared to the conventional FPA and other baseline schemes.
Musical Instrument Recognition by XGBoost Combining Feature Fusion
Jun 02, 2022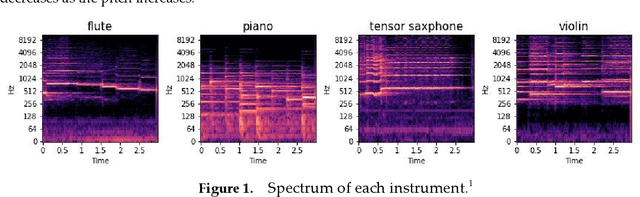

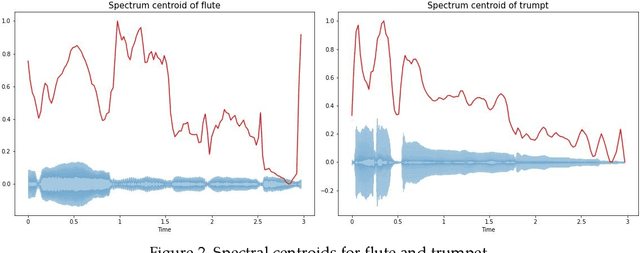
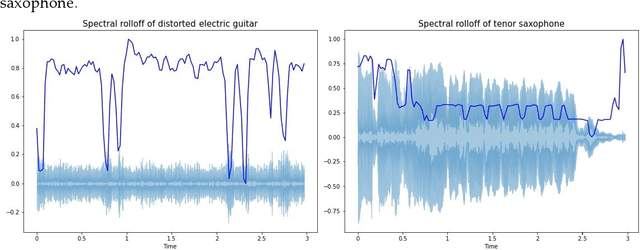
Musical instrument classification is one of the focuses of Music Information Retrieval (MIR). In order to solve the problem of poor performance of current musical instrument classification models, we propose a musical instrument classification algorithm based on multi-channel feature fusion and XGBoost. Based on audio feature extraction and fusion of the dataset, the features are input into the XGBoost model for training; secondly, we verified the superior performance of the algorithm in the musical instrument classification task by com-paring different feature combinations and several classical machine learning models such as Naive Bayes. The algorithm achieves an accuracy of 97.65% on the Medley-solos-DB dataset, outperforming existing models. The experiments provide a reference for feature selection in feature engineering for musical instrument classification.