 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanizing Robot Gaze Shifts: A Framework for Natural Gaze Shifts in Humanoid Robots
Feb 25, 2026Leveraging auditory and visual feedback for attention reorientation is essential for natural gaze shifts in social interaction. However, enabling humanoid robots to perform natural and context-appropriate gaze shifts in unconstrained human--robot interaction (HRI) remains challenging, as it requires the coupling of cognitive attention mechanisms and biomimetic motion generation. In this work, we propose the Robot Gaze-Shift (RGS) framework, which integrates these two components into a unified pipeline. First, RGS employs a vision--language model (VLM)-based gaze reasoning pipeline to infer context-appropriate gaze targets from multimodal interaction cues, ensuring consistency with human gaze-orienting regularities. Second, RGS introduces a conditional Vector Quantized-Variational Autoencoder (VQ-VAE) model for eye--head coordinated gaze-shift motion generation, producing diverse and human-like gaze-shift behaviors. Experiments validate that RGS effectively replicates human-like target selection and generates realistic, diverse gaze-shift motions.
Whole-body Motion Control of an Omnidirectional Wheel-Legged Mobile Manipulator via Contact-Aware Dynamic Optimization
Sep 17, 2025Wheel-legged robots with integrated manipulators hold great promise for mobile manipulation in logistics, industrial automation, and human-robot collaboration. However, unified control of such systems remains challenging due to the redundancy in degrees of freedom, complex wheel-ground contact dynamics, and the need for seamless coordination between locomotion and manipulation. In this work, we present the design and whole-body motion control of an omnidirectional wheel-legged quadrupedal robot equipped with a dexterous manipulator. The proposed platform incorporates independently actuated steering modules and hub-driven wheels, enabling agile omnidirectional locomotion with high maneuverability in structured environments. To address the challenges of contact-rich interaction, we develop a contact-aware whole-body dynamic optimization framework that integrates point-contact modeling for manipulation with line-contact modeling for wheel-ground interactions. A warm-start strategy is introduced to accelerate online optimization, ensuring real-time feasibility for high-dimensional control. Furthermore, a unified kinematic model tailored for the robot's 4WIS-4WID actuation scheme eliminates the need for mode switching across different locomotion strategies, improving control consistency and robustness. Simulation and experimental results validate the effectiveness of the proposed framework, demonstrating agile terrain traversal, high-speed omnidirectional mobility, and precise manipulation under diverse scenarios, underscoring the system's potential for factory automation, urban logistics, and service robotics in semi-structured environments.
MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
May 18, 2025Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, limiting their applicability to tasks where historical context is crucial for disambiguating current observations. This limitation hinders performance in long-horizon sequential manipulation tasks where the correct action depends on past events not fully captured by the current state. To address this fundamental challenge, we introduce Mamba Temporal Imitation Learning (MTIL), a novel approach that leverages the recurrent state dynamics inherent in State Space Models (SSMs), specifically the Mamba architecture. MTIL encodes the entire trajectory history into a compressed hidden state, conditioning action predictions on this comprehensive temporal context alongside current multi-modal observations. Through extensive experiments on simulated benchmarks (ACT dataset tasks, Robomimic, LIBERO) and real-world sequential manipulation tasks specifically designed to probe temporal dependencies, MTIL significantly outperforms state-of-the-art methods like ACT and Diffusion Policy. Our findings affirm the necessity of full temporal context for robust sequential decision-making and validate MTIL as a powerful approach that transcends the inherent limitations of Markovian imitation learning
GelSplitter: Tactile Reconstruction from Near Infrared and Visible Images
Sep 15, 2023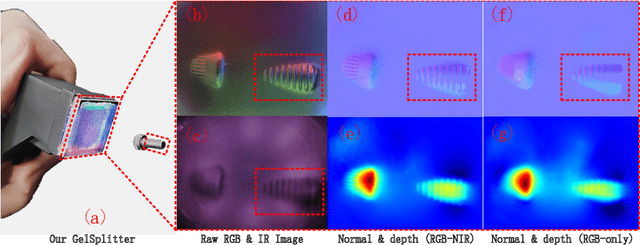

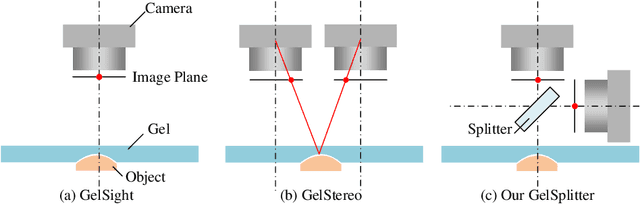
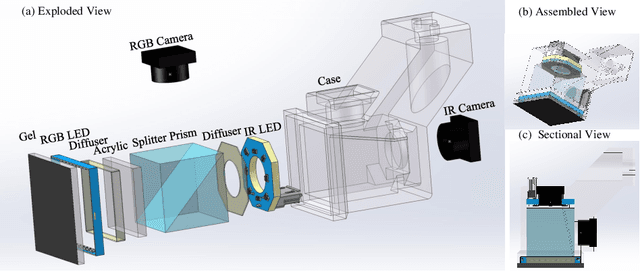
The GelSight-like visual tactile (VT) sensor has gained popularity as a high-resolution tactile sensing technology for robots, capable of measuring touch geometry using a single RGB camera. However, the development of multi-modal perception for VT sensors remains a challenge, limited by the mono camera. In this paper, we propose the GelSplitter, a new framework approach the multi-modal VT sensor with synchronized multi-modal cameras and resemble a more human-like tactile receptor. Furthermore, we focus on 3D tactile reconstruction and implement a compact sensor structure that maintains a comparable size to state-of-the-art VT sensors, even with the addition of a prism and a near infrared (NIR) camera. We also design a photometric fusion stereo neural network (PFSNN), which estimates surface normals of objects and reconstructs touch geometry from both infrared and visible images. Our results demonstrate that the accuracy of RGB and NIR fusion is higher than that of RGB images alone. Additionally, our GelSplitter framework allows for a flexible configuration of different camera sensor combinations, such as RGB and thermal imaging.
GelFlow: Self-supervised Learning of Optical Flow for Vision-Based Tactile Sensor Displacement Measurement
Sep 13, 2023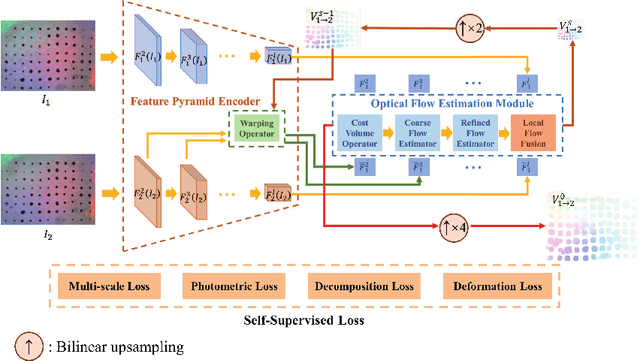
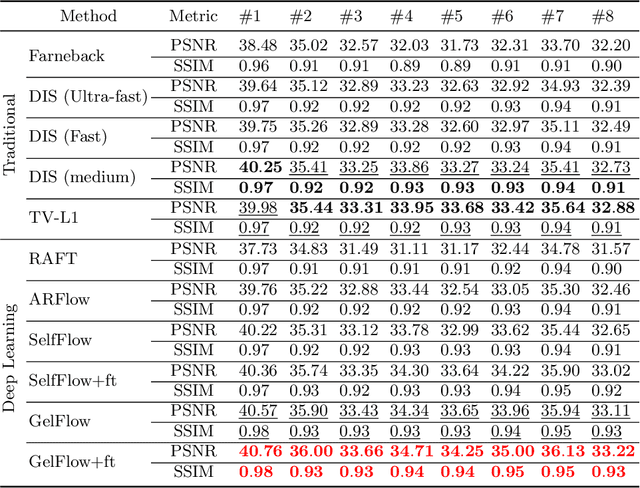
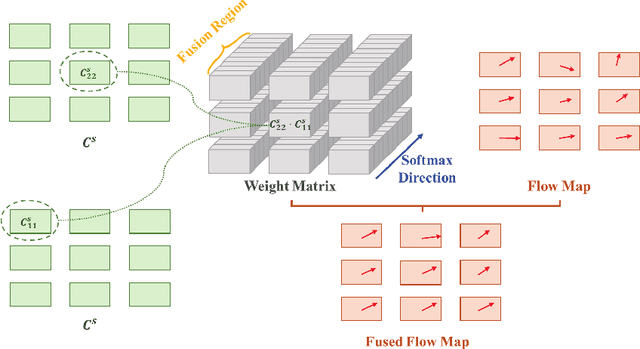
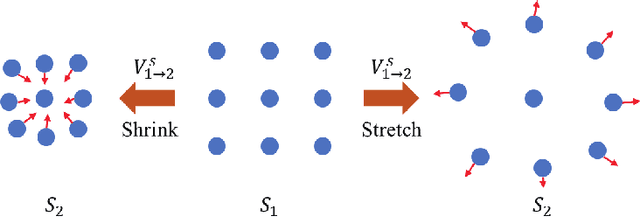
High-resolution multi-modality information acquired by vision-based tactile sensors can support more dexterous manipulations for robot fingers. Optical flow is low-level information directly obtained by vision-based tactile sensors, which can be transformed into other modalities like force, geometry and depth. Current vision-tactile sensors employ optical flow methods from OpenCV to estimate the deformation of markers in gels. However, these methods need to be more precise for accurately measuring the displacement of markers during large elastic deformation of the gel, as this can significantly impact the accuracy of downstream tasks. This study proposes a self-supervised optical flow method based on deep learning to achieve high accuracy in displacement measurement for vision-based tactile sensors. The proposed method employs a coarse-to-fine strategy to handle large deformations by constructing a multi-scale feature pyramid from the input image. To better deal with the elastic deformation caused by the gel, the Helmholtz velocity decomposition constraint combined with the elastic deformation constraint are adopted to address the distortion rate and area change rate, respectively. A local flow fusion module is designed to smooth the optical flow, taking into account the prior knowledge of the blurred effect of gel deformation. We trained the proposed self-supervised network using an open-source dataset and compared it with traditional and deep learning-based optical flow methods. The results show that the proposed method achieved the highest displacement measurement accuracy, thereby demonstrating its potential for enabling more precise measurement of downstream tasks using vision-based tactile sensors.
Adaptive adversarial training method for improving multi-scale GAN based on generalization bound theory
Nov 30, 2022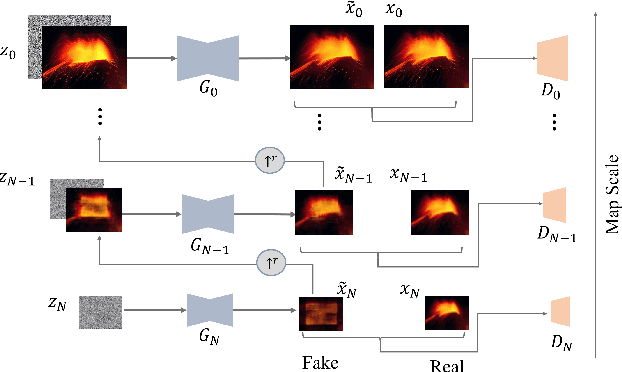

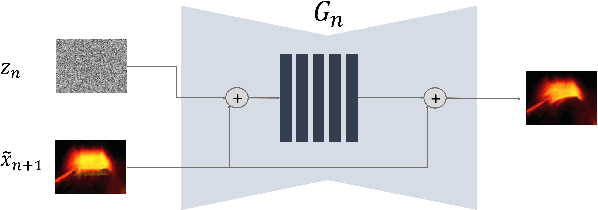

In recent years, multi-scale generative adversarial networks (GANs) have been proposed to build generalized image processing models based on single sample. Constraining on the sample size, multi-scale GANs have much difficulty converging to the global optimum, which ultimately leads to limitations in their capabilities. In this paper, we pioneered the introduction of PAC-Bayes generalized bound theory into the training analysis of specific models under different adversarial training methods, which can obtain a non-vacuous upper bound on the generalization error for the specified multi-scale GAN structure. Based on the drastic changes we found of the generalization error bound under different adversarial attacks and different training states, we proposed an adaptive training method which can greatly improve the image manipulation ability of multi-scale GANs. The final experimental results show that our adaptive training method in this paper has greatly contributed to the improvement of the quality of the images generated by multi-scale GANs on several image manipulation tasks. In particular, for the image super-resolution restoration task, the multi-scale GAN model trained by the proposed method achieves a 100% reduction in natural image quality evaluator (NIQE) and a 60% reduction in root mean squared error (RMSE), which is better than many models trained on large-scale datasets.