 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Interactive Semantic Alignment for Efficient HOI Detection with Vision-language Model
Apr 19, 2024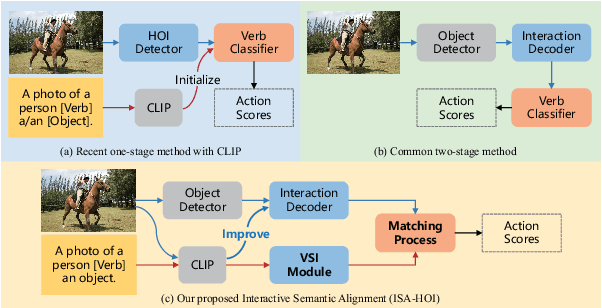
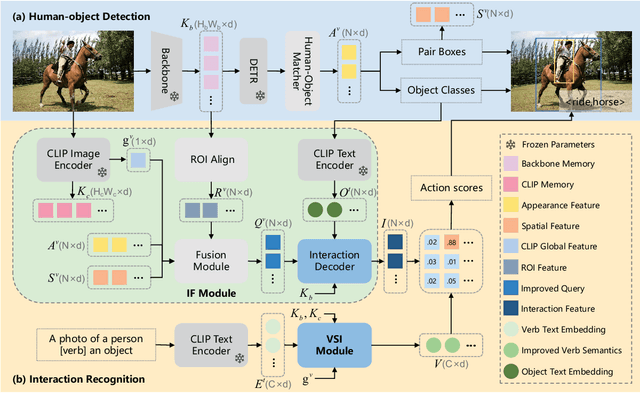
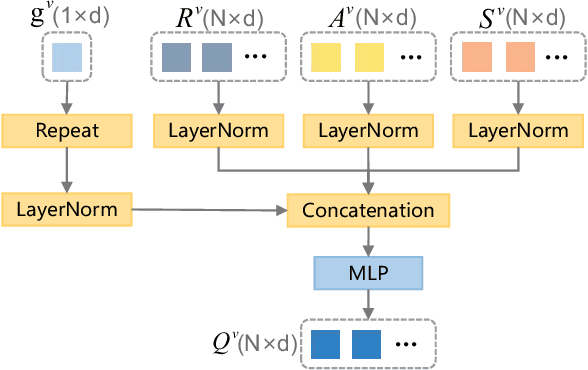

Human-Object Interaction (HOI) detection aims to localize human-object pairs and comprehend their interactions. Recently, two-stage transformer-based methods have demonstrated competitive performance. However, these methods frequently focus on object appearance features and ignore global contextual information. Besides, vision-language model CLIP which effectively aligns visual and text embeddings has shown great potential in zero-shot HOI detection. Based on the former facts, We introduce a novel HOI detector named ISA-HOI, which extensively leverages knowledge from CLIP, aligning interactive semantics between visual and textual features. We first extract global context of image and local features of object to Improve interaction Features in images (IF). On the other hand, we propose a Verb Semantic Improvement (VSI) module to enhance textual features of verb labels via cross-modal fusion. Ultimately, our method achieves competitive results on the HICO-DET and V-COCO benchmarks with much fewer training epochs, and outperforms the state-of-the-art under zero-shot settings.