 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCSD: An Efficient Language Model with Diverse Fusion
Paper and Code
Jun 18, 2024
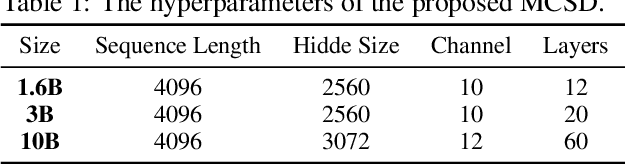


Transformers excel in Natural Language Processing (NLP) due to their prowess in capturing long-term dependencies but suffer from exponential resource consumption with increasing sequence lengths. To address these challenges, we propose MCSD model, an efficient language model with linear scaling and fast inference speed. MCSD model leverages diverse feature fusion, primarily through the multi-channel slope and decay (MCSD) block, to robustly represent features. This block comprises slope and decay sections that extract features across diverse temporal receptive fields, facilitating capture of both local and global information. In addition, MCSD block conducts element-wise fusion of diverse features to further enhance the delicate feature extraction capability. For inference, we formulate the inference process into a recurrent representation, slashing space complexity to $O(1)$ and time complexity to $O(N)$ respectively. Our experiments show that MCSD attains higher throughput and lower GPU memory consumption compared to Transformers, while maintaining comparable performance to larger-scale language learning models on benchmark tests. These attributes position MCSD as a promising base for edge deployment and embodied intelligence.