 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyScene3D: Physically Consistent Interactive 3D Tabletop Scene Generation
Jun 01, 2026Generating physically consistent 3D tabletop scenes is a fundamental yet underexplored problem for interactive and generalist robotic learning. The challenge stems from dense object hierarchies and irregular affordances. Here, an interactive scene denotes a physically valid, collision-free environment directly loadable into physics simulators. Existing methods, ranging from decoupled symbolic solvers to end-to-end regression models, often suffer from error propagation or overfitting to noisy supervision containing widespread physical violations. To address these limitations, we introduce PhyScene3D, a framework that reformulates generation as a Human-Mimetic Constructive Process. The proposed Cognitive Topological Reasoning Chain (CTRC) factorizes scene synthesis into a sequential, anchor-conditioned process. It employs a 3D AABB-based placement scheme that imposes a strong structural inductive bias. To address imperfect supervision and physical infeasibility, we introduce Physics-Aware Denoising Alignment (PADA). It integrates a differentiable Signed Distance Field (SDF) with Test-Time Optimization (TTO) to project generated scenes onto a physics-feasible manifold while preserving semantic intent. Experiments demonstrate that PhyScene3D outperforms state-of-the-art approaches in both semantic accuracy and physical validity, achieving a 40% reduction in scene-wise collision rate relative to the human-annotated training data.
Empowering Large Language Models with 3D Situation Awareness
Mar 29, 2025Driven by the great success of Large Language Models (LLMs) in the 2D image domain, their applications in 3D scene understanding has emerged as a new trend. A key difference between 3D and 2D is that the situation of an egocentric observer in 3D scenes can change, resulting in different descriptions (e.g., ''left" or ''right"). However, current LLM-based methods overlook the egocentric perspective and simply use datasets from a global viewpoint. To address this issue, we propose a novel approach to automatically generate a situation-aware dataset by leveraging the scanning trajectory during data collection and utilizing Vision-Language Models (VLMs) to produce high-quality captions and question-answer pairs. Furthermore, we introduce a situation grounding module to explicitly predict the position and orientation of observer's viewpoint, thereby enabling LLMs to ground situation description in 3D scenes. We evaluate our approach on several benchmarks, demonstrating that our method effectively enhances the 3D situational awareness of LLMs while significantly expanding existing datasets and reducing manual effort.
Geometry-Aware Network for Domain Adaptive Semantic Segmentation
Dec 05, 2022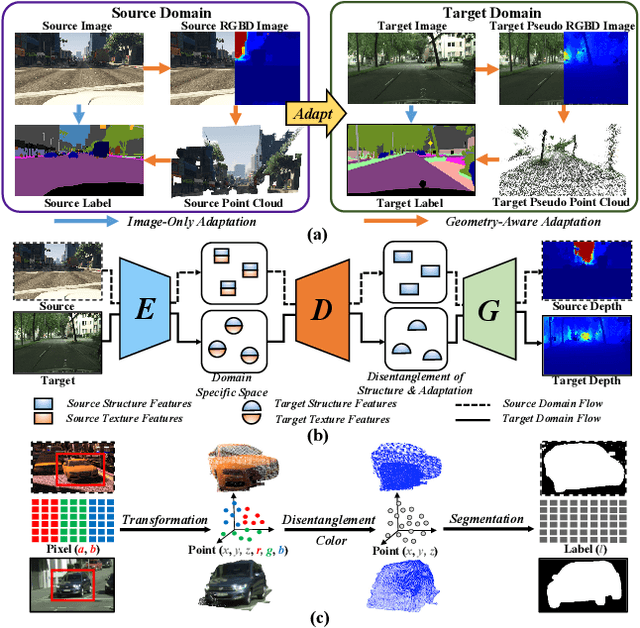

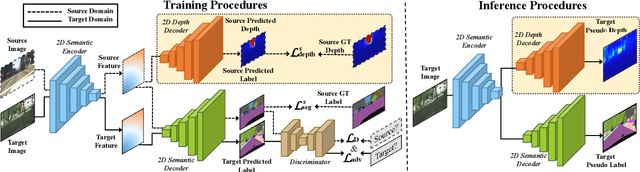

Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Apr 06, 2022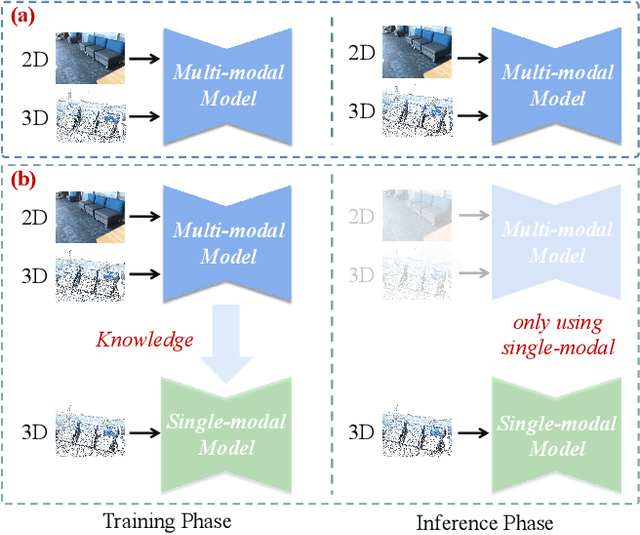
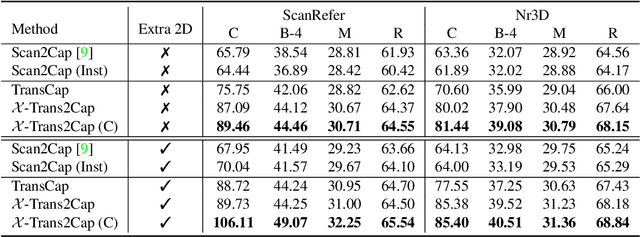


3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
CLEVR3D: Compositional Language and Elementary Visual Reasoning for Question Answering in 3D Real-World Scenes
Dec 31, 2021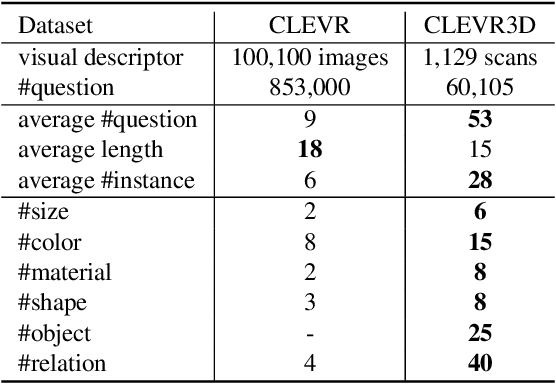

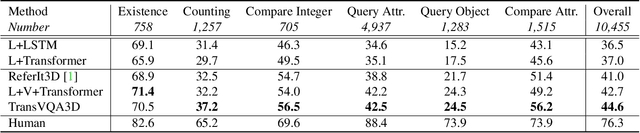
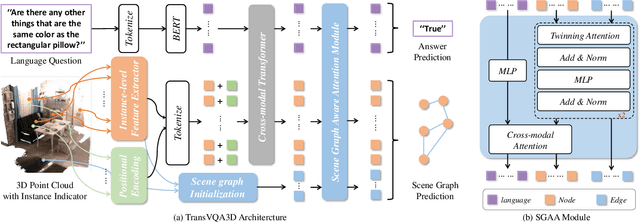
3D scene understanding is a relatively emerging research field. In this paper, we introduce the Visual Question Answering task in 3D real-world scenes (VQA-3D), which aims to answer all possible questions given a 3D scene. To tackle this problem, the first VQA-3D dataset, namely CLEVR3D, is proposed, which contains 60K questions in 1,129 real-world scenes. Specifically, we develop a question engine leveraging 3D scene graph structures to generate diverse reasoning questions, covering the questions of objects' attributes (i.e., size, color, and material) and their spatial relationships. Built upon this dataset, we further design the first VQA-3D baseline model, TransVQA3D. The TransVQA3D model adopts well-designed Transformer architectures to achieve superior VQA-3D performance, compared with the pure language baseline and previous 3D reasoning methods directly applied to 3D scenarios. Experimental results verify that taking VQA-3D as an auxiliary task can boost the performance of 3D scene understanding, including scene graph analysis for the node-wise classification and whole-graph recognition.
Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 18, 2021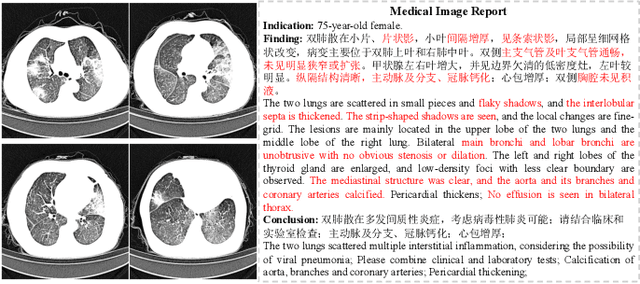
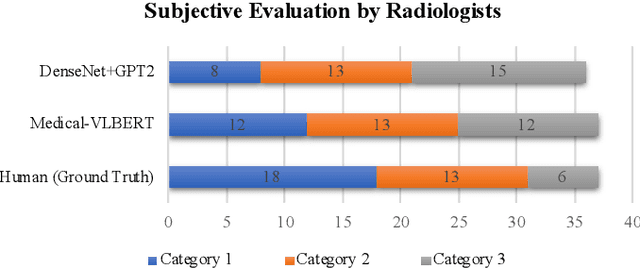
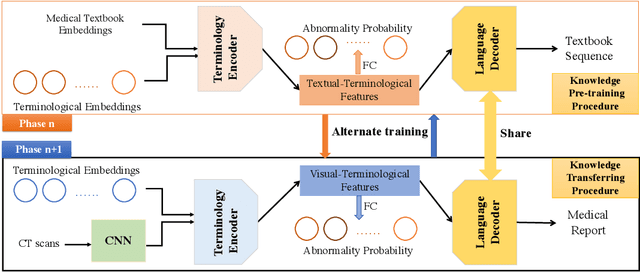
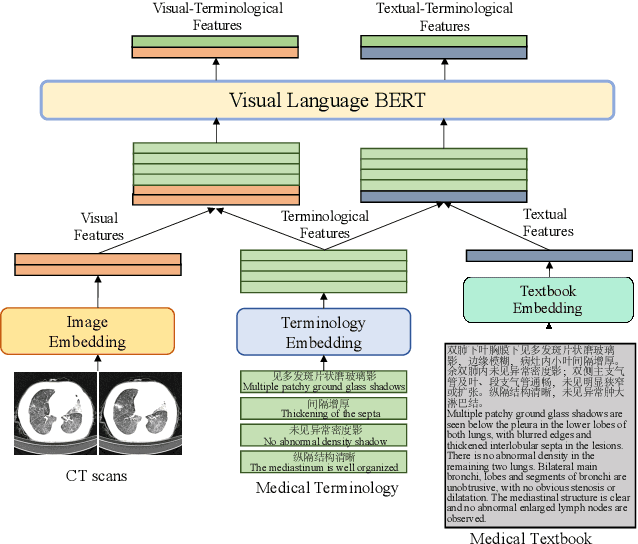
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
InstanceRefer: Cooperative Holistic Understanding for Visual Grounding on Point Clouds through Instance Multi-level Contextual Referring
Mar 01, 2021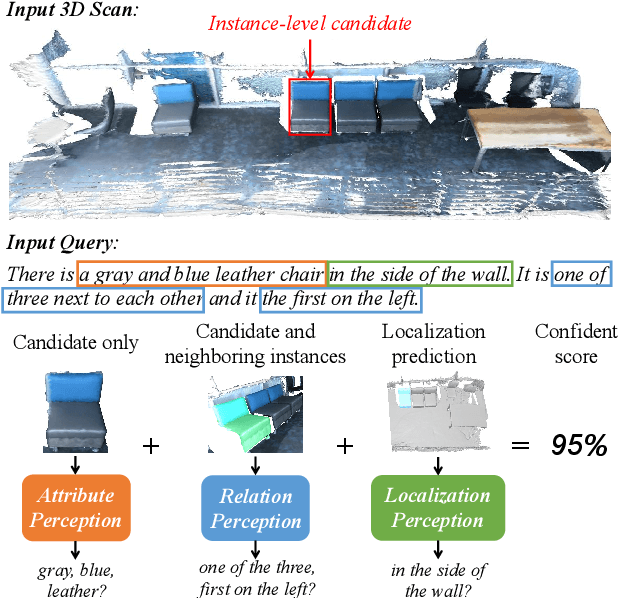
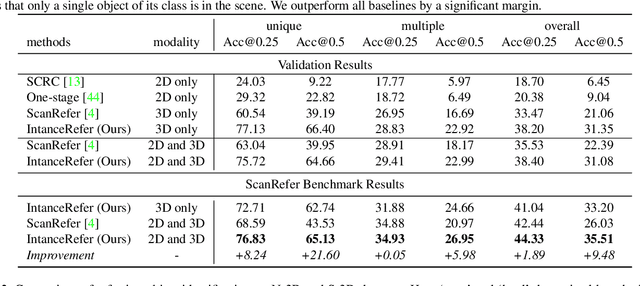


Compared with the visual grounding in 2D images, the natural-language-guided 3D object localization on point clouds is more challenging due to the sparse and disordered property. In this paper, we propose a new model, named InstanceRefer, to achieve a superior 3D visual grounding through unifying instance attribute, relation and localization perceptions. In practice, based on the predicted target category from natural language, our model first filters instances from panoptic segmentation on point clouds to obtain a small number of candidates. Note that such instance-level candidates are more effective and rational than the redundant 3D object-proposal candidates. Then, for each candidate, we conduct the cooperative holistic scene-language understanding, i.e., multi-level contextual referring from instance attribute perception, instance-to-instance relation perception and instance-to-background global localization perception. Eventually, the most relevant candidate is localized effectively through adaptive confidence fusion. Experiments confirm that our InstanceRefer outperforms previous state-of-the-art methods by a large margin, i.e., 9.5% improvement on the ScanRefer benchmark (ranked 1st place) and 7.2% improvement on Sr3D.