 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEVR3D: Compositional Language and Elementary Visual Reasoning for Question Answering in 3D Real-World Scenes
Paper and Code
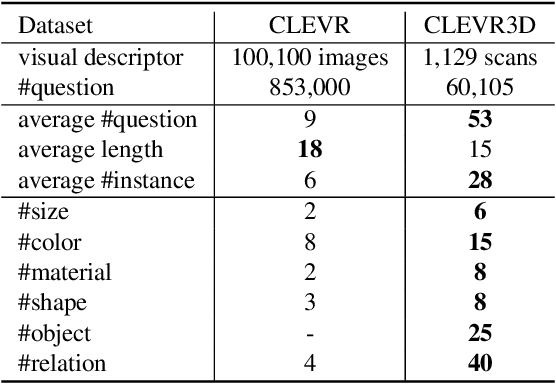

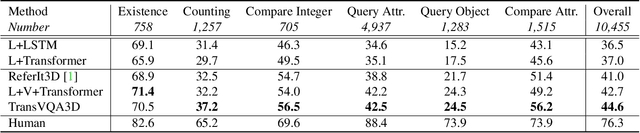
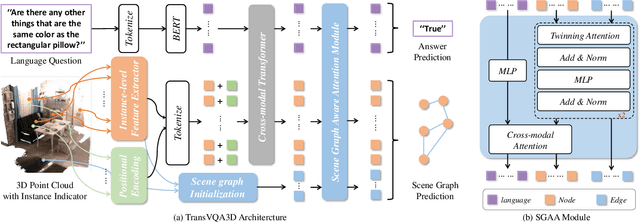
3D scene understanding is a relatively emerging research field. In this paper, we introduce the Visual Question Answering task in 3D real-world scenes (VQA-3D), which aims to answer all possible questions given a 3D scene. To tackle this problem, the first VQA-3D dataset, namely CLEVR3D, is proposed, which contains 60K questions in 1,129 real-world scenes. Specifically, we develop a question engine leveraging 3D scene graph structures to generate diverse reasoning questions, covering the questions of objects' attributes (i.e., size, color, and material) and their spatial relationships. Built upon this dataset, we further design the first VQA-3D baseline model, TransVQA3D. The TransVQA3D model adopts well-designed Transformer architectures to achieve superior VQA-3D performance, compared with the pure language baseline and previous 3D reasoning methods directly applied to 3D scenarios. Experimental results verify that taking VQA-3D as an auxiliary task can boost the performance of 3D scene understanding, including scene graph analysis for the node-wise classification and whole-graph recognition.