 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 18, 2021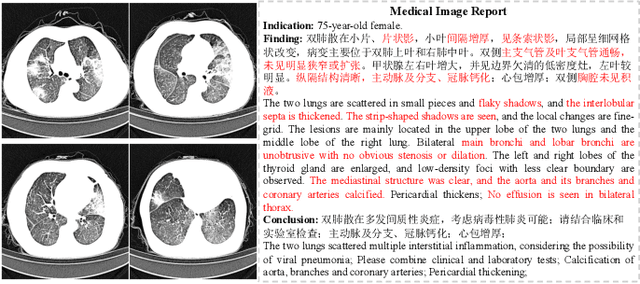
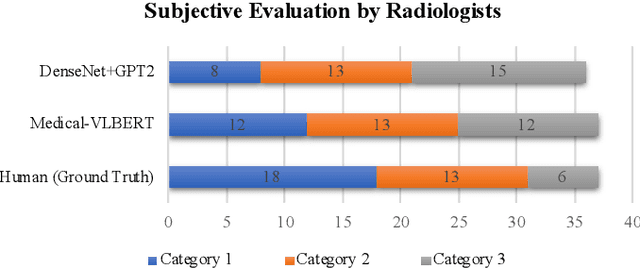
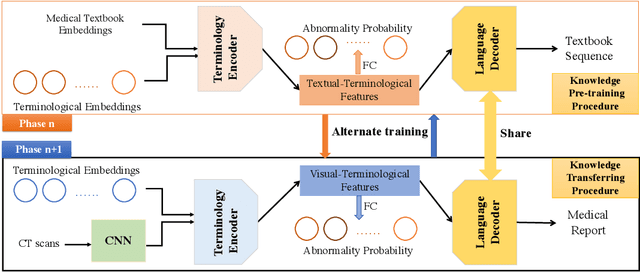
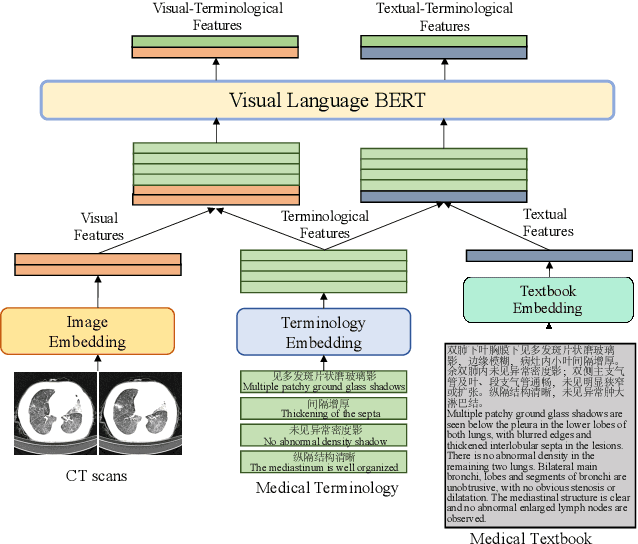
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
Unifying Relational Sentence Generation and Retrieval for Medical Image Report Composition
Jan 09, 2021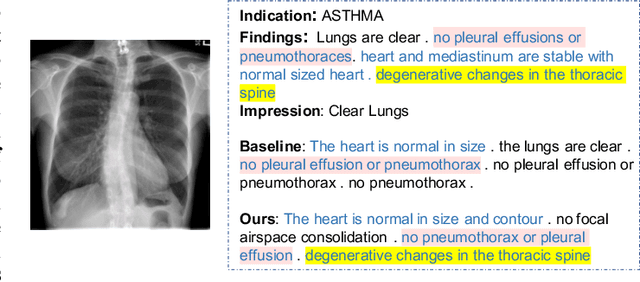
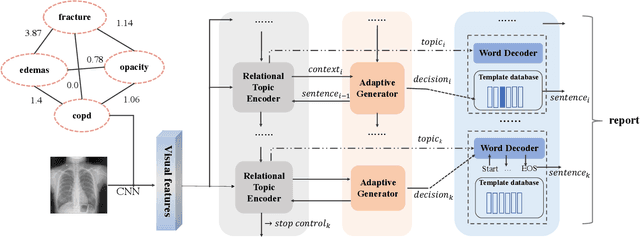
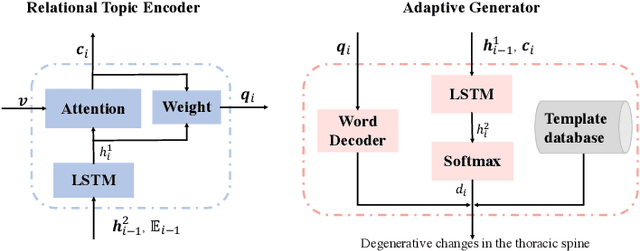
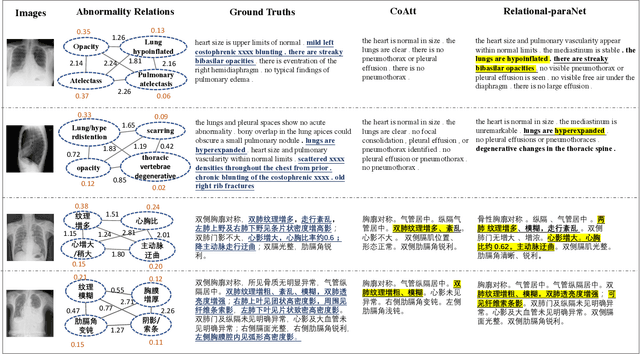
Beyond generating long and topic-coherent paragraphs in traditional captioning tasks, the medical image report composition task poses more task-oriented challenges by requiring both the highly-accurate medical term diagnosis and multiple heterogeneous forms of information including impression and findings. Current methods often generate the most common sentences due to dataset bias for individual case, regardless of whether the sentences properly capture key entities and relationships. Such limitations severely hinder their applicability and generalization capability in medical report composition where the most critical sentences lie in the descriptions of abnormal diseases that are relatively rare. Moreover, some medical terms appearing in one report are often entangled with each other and co-occurred, e.g. symptoms associated with a specific disease. To enforce the semantic consistency of medical terms to be incorporated into the final reports and encourage the sentence generation for rare abnormal descriptions, we propose a novel framework that unifies template retrieval and sentence generation to handle both common and rare abnormality while ensuring the semantic-coherency among the detected medical terms. Specifically, our approach exploits hybrid-knowledge co-reasoning: i) explicit relationships among all abnormal medical terms to induce the visual attention learning and topic representation encoding for better topic-oriented symptoms descriptions; ii) adaptive generation mode that changes between the template retrieval and sentence generation according to a contextual topic encoder. Experimental results on two medical report benchmarks demonstrate the superiority of the proposed framework in terms of both human and metrics evaluation.
Auxiliary Signal-Guided Knowledge Encoder-Decoder for Medical Report Generation
Jun 06, 2020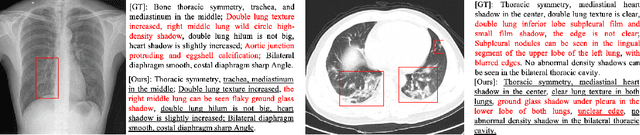
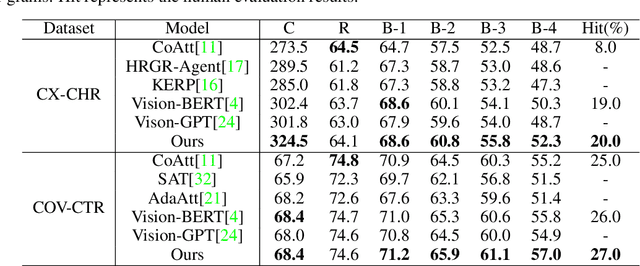
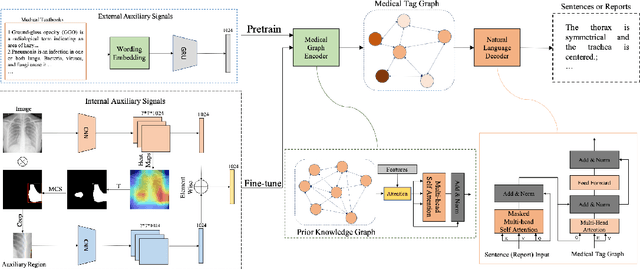
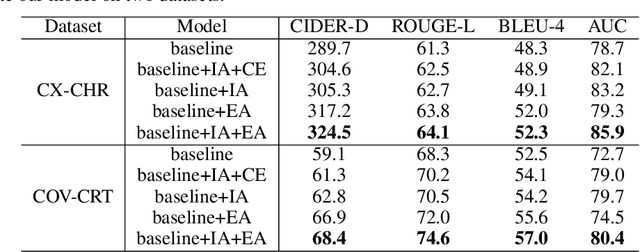
Beyond the common difficulties faced in the natural image captioning, medical report generation specifically requires the model to describe a medical image with a fine-grained and semantic-coherence paragraph that should satisfy both medical commonsense and logic. Previous works generally extract the global image features and attempt to generate a paragraph that is similar to referenced reports; however, this approach has two limitations. Firstly, the regions of primary interest to radiologists are usually located in a small area of the global image, meaning that the remainder parts of the image could be considered as irrelevant noise in the training procedure. Secondly, there are many similar sentences used in each medical report to describe the normal regions of the image, which causes serious data bias. This deviation is likely to teach models to generate these inessential sentences on a regular basis. To address these problems, we propose an Auxiliary Signal-Guided Knowledge Encoder-Decoder (ASGK) to mimic radiologists' working patterns. In more detail, ASGK integrates internal visual feature fusion and external medical linguistic information to guide medical knowledge transfer and learning. The core structure of ASGK consists of a medical graph encoder and a natural language decoder, inspired by advanced Generative Pre-Training (GPT). Experiments on the CX-CHR dataset and our COVID-19 CT Report dataset demonstrate that our proposed ASGK is able to generate a robust and accurate report, and moreover outperforms state-of-the-art methods on both medical terminology classification and paragraph generation metrics.