 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 18, 2021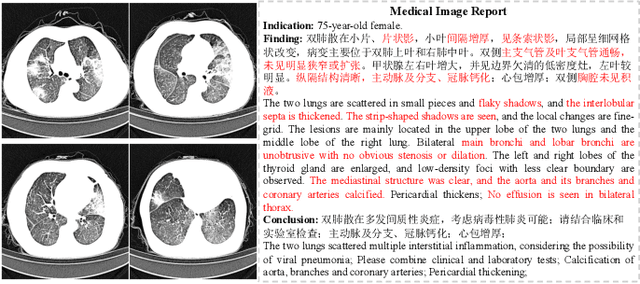
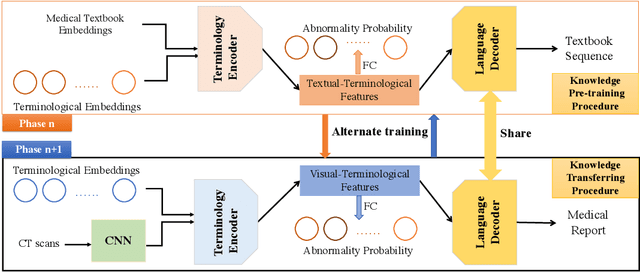
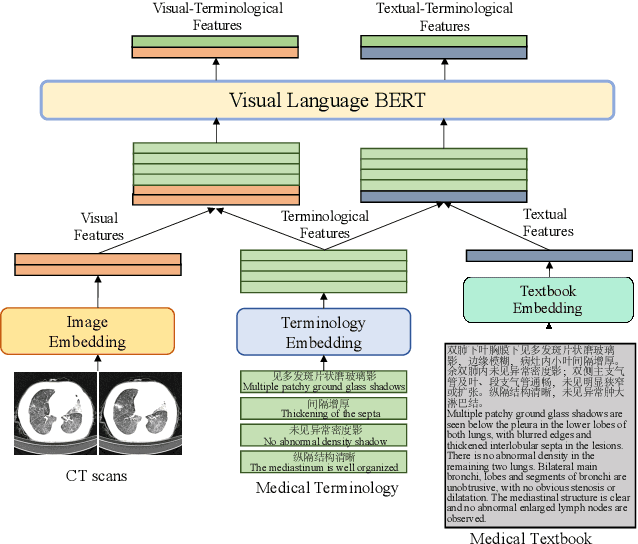
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
Hepatocellular Carcinoma Segmentation fromDigital Subtraction Angiography Videos usingLearnable Temporal Difference
Jul 09, 2021

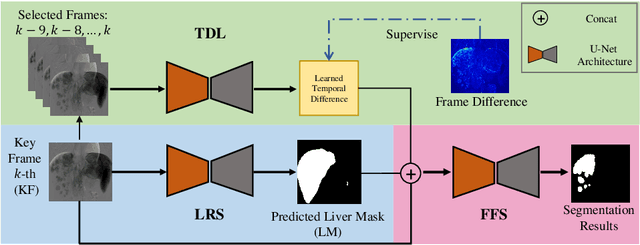

Automatic segmentation of hepatocellular carcinoma (HCC)in Digital Subtraction Angiography (DSA) videos can assist radiologistsin efficient diagnosis of HCC and accurate evaluation of tumors in clinical practice. Few studies have investigated HCC segmentation from DSAvideos. It shows great challenging due to motion artifacts in filming, ambiguous boundaries of tumor regions and high similarity in imaging toother anatomical tissues. In this paper, we raise the problem of HCCsegmentation in DSA videos, and build our own DSA dataset. We alsopropose a novel segmentation network called DSA-LTDNet, including asegmentation sub-network, a temporal difference learning (TDL) moduleand a liver region segmentation (LRS) sub-network for providing additional guidance. DSA-LTDNet is preferable for learning the latent motioninformation from DSA videos proactively and boosting segmentation performance. All of experiments are conducted on our self-collected dataset.Experimental results show that DSA-LTDNet increases the DICE scoreby nearly 4% compared to the U-Net baseline.