 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Network for Domain Adaptive Semantic Segmentation
Paper and Code
Dec 05, 2022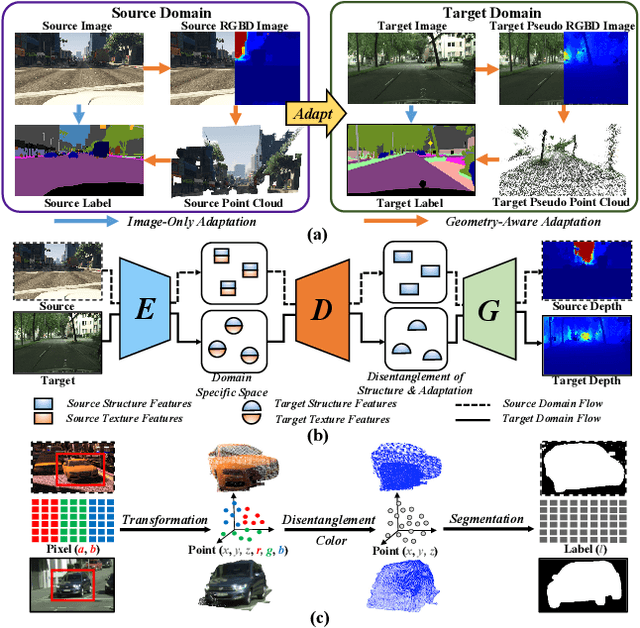

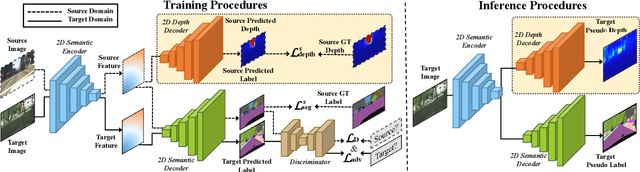

Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.