 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceRefer: Cooperative Holistic Understanding for Visual Grounding on Point Clouds through Instance Multi-level Contextual Referring
Paper and Code
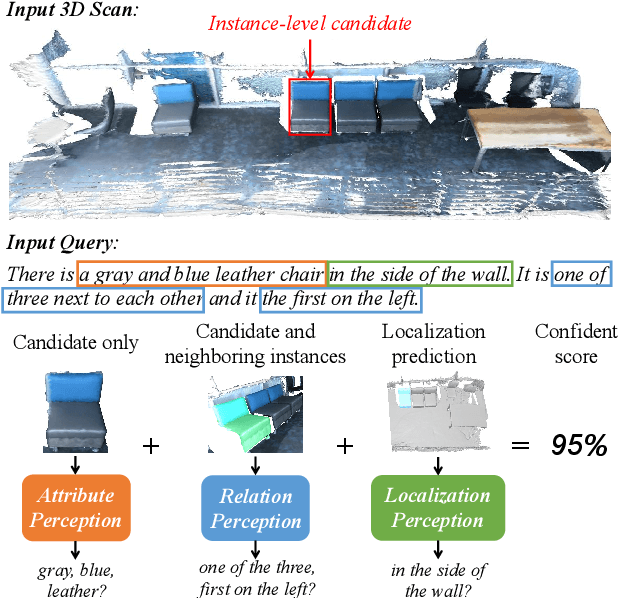
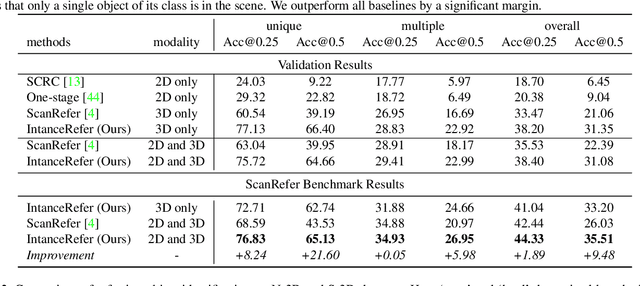


Compared with the visual grounding in 2D images, the natural-language-guided 3D object localization on point clouds is more challenging due to the sparse and disordered property. In this paper, we propose a new model, named InstanceRefer, to achieve a superior 3D visual grounding through unifying instance attribute, relation and localization perceptions. In practice, based on the predicted target category from natural language, our model first filters instances from panoptic segmentation on point clouds to obtain a small number of candidates. Note that such instance-level candidates are more effective and rational than the redundant 3D object-proposal candidates. Then, for each candidate, we conduct the cooperative holistic scene-language understanding, i.e., multi-level contextual referring from instance attribute perception, instance-to-instance relation perception and instance-to-background global localization perception. Eventually, the most relevant candidate is localized effectively through adaptive confidence fusion. Experiments confirm that our InstanceRefer outperforms previous state-of-the-art methods by a large margin, i.e., 9.5% improvement on the ScanRefer benchmark (ranked 1st place) and 7.2% improvement on Sr3D.