 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Jan 28, 2026Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
FigEx2: Visual-Conditioned Panel Detection and Captioning for Scientific Compound Figures
Jan 12, 2026Scientific compound figures combine multiple labeled panels into a single image, but captions in real pipelines are often missing or only provide figure-level summaries, making panel-level understanding difficult. In this paper, we propose FigEx2, visual-conditioned framework that localizes panels and generates panel-wise captions directly from the compound figure. To mitigate the impact of diverse phrasing in open-ended captioning, we introduce a noise-aware gated fusion module that adaptively filters token-level features to stabilize the detection query space. Furthermore, we employ a staged optimization strategy combining supervised learning with reinforcement learning (RL), utilizing CLIP-based alignment and BERTScore-based semantic rewards to enforce strict multimodal consistency. To support high-quality supervision, we curate BioSci-Fig-Cap, a refined benchmark for panel-level grounding, alongside cross-disciplinary test suites in physics and chemistry. Experimental results demonstrate that FigEx2 achieves a superior 0.726 mAP@0.5:0.95 for detection and significantly outperforms Qwen3-VL-8B by 0.51 in METEOR and 0.24 in BERTScore. Notably, FigEx2 exhibits remarkable zero-shot transferability to out-of-distribution scientific domains without any fine-tuning.
Aligning Findings with Diagnosis: A Self-Consistent Reinforcement Learning Framework for Trustworthy Radiology Reporting
Jan 06, 2026Multimodal Large Language Models (MLLMs) have shown strong potential for radiology report generation, yet their clinical translation is hindered by architectural heterogeneity and the prevalence of factual hallucinations. Standard supervised fine-tuning often fails to strictly align linguistic outputs with visual evidence, while existing reinforcement learning approaches struggle with either prohibitive computational costs or limited exploration. To address these challenges, we propose a comprehensive framework for self-consistent radiology report generation. First, we conduct a systematic evaluation to identify optimal vision encoder and LLM backbone configurations for medical imaging. Building on this foundation, we introduce a novel "Reason-then-Summarize" architecture optimized via Group Relative Policy Optimization (GRPO). This framework restructures generation into two distinct components: a think block for detailed findings and an answer block for structured disease labels. By utilizing a multi-dimensional composite reward function, we explicitly penalize logical discrepancies between the generated narrative and the final diagnosis. Extensive experiments on the MIMIC-CXR benchmark demonstrate that our method achieves state-of-the-art performance in clinical efficacy metrics and significantly reduces hallucinations compared to strong supervised baselines.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
Dec 16, 2024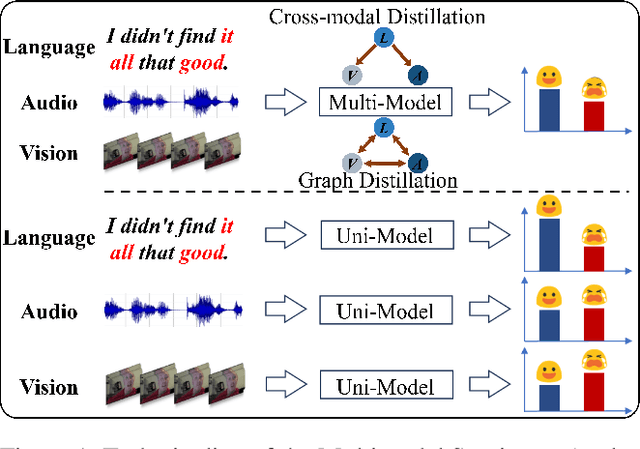
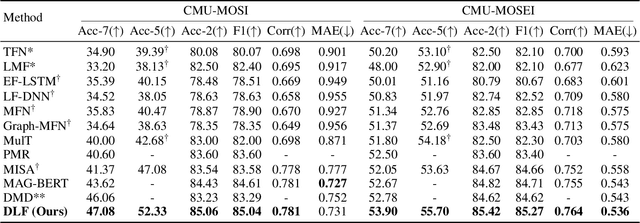
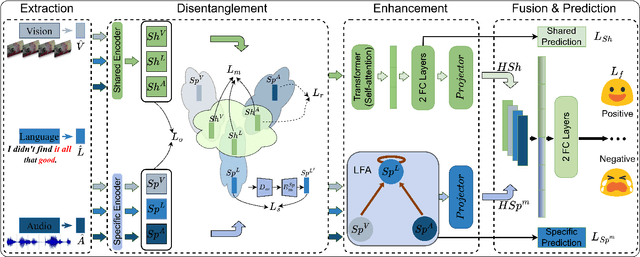
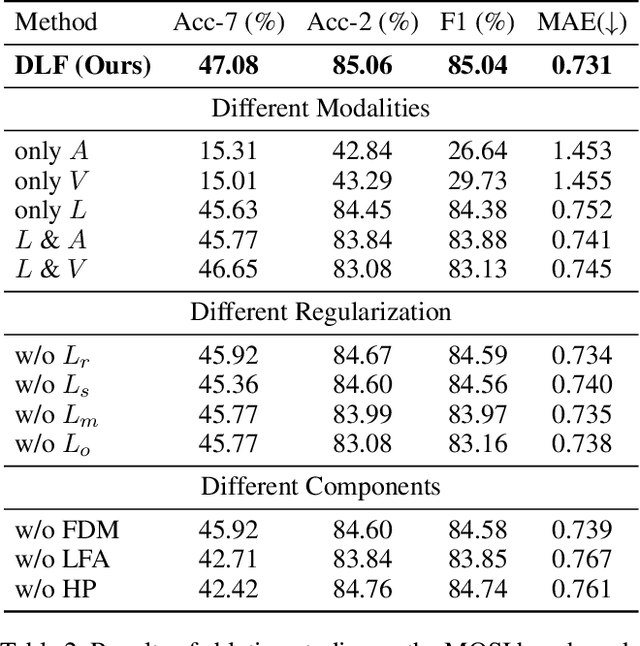
Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at https://github.com/pwang322/DLF.
FairSkin: Fair Diffusion for Skin Disease Image Generation
Oct 31, 2024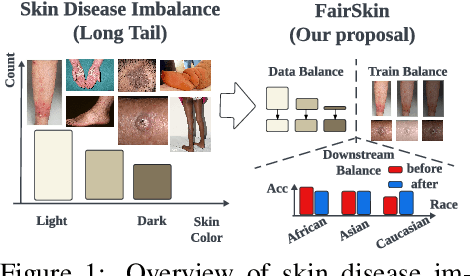
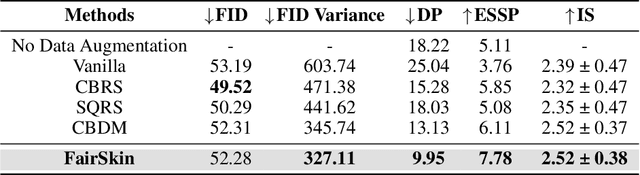


Image generation is a prevailing technique for clinical data augmentation for advancing diagnostic accuracy and reducing healthcare disparities. Diffusion Model (DM) has become a leading method in generating synthetic medical images, but it suffers from a critical twofold bias: (1) The quality of images generated for Caucasian individuals is significantly higher, as measured by the Frechet Inception Distance (FID). (2) The ability of the downstream-task learner to learn critical features from disease images varies across different skin tones. These biases pose significant risks, particularly in skin disease detection, where underrepresentation of certain skin tones can lead to misdiagnosis or neglect of specific conditions. To address these challenges, we propose FairSkin, a novel DM framework that mitigates these biases through a three-level resampling mechanism, ensuring fairer representation across racial and disease categories. Our approach significantly improves the diversity and quality of generated images, contributing to more equitable skin disease detection in clinical settings.
FrameNeRF: A Simple and Efficient Framework for Few-shot Novel View Synthesis
Feb 26, 2024



We present a novel framework, called FrameNeRF, designed to apply off-the-shelf fast high-fidelity NeRF models with fast training speed and high rendering quality for few-shot novel view synthesis tasks. The training stability of fast high-fidelity models is typically constrained to dense views, making them unsuitable for few-shot novel view synthesis tasks. To address this limitation, we utilize a regularization model as a data generator to produce dense views from sparse inputs, facilitating subsequent training of fast high-fidelity models. Since these dense views are pseudo ground truth generated by the regularization model, original sparse images are then used to fine-tune the fast high-fidelity model. This process helps the model learn realistic details and correct artifacts introduced in earlier stages. By leveraging an off-the-shelf regularization model and a fast high-fidelity model, our approach achieves state-of-the-art performance across various benchmark datasets.
RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Dec 19, 2023



3D occupancy prediction is an emerging task that aims to estimate the occupancy states and semantics of 3D scenes using multi-view images. However, image-based scene perception encounters significant challenges in achieving accurate prediction due to the absence of geometric priors. In this paper, we address this issue by exploring cross-modal knowledge distillation in this task, i.e., we leverage a stronger multi-modal model to guide the visual model during training. In practice, we observe that directly applying features or logits alignment, proposed and widely used in bird's-eyeview (BEV) perception, does not yield satisfactory results. To overcome this problem, we introduce RadOcc, a Rendering assisted distillation paradigm for 3D Occupancy prediction. By employing differentiable volume rendering, we generate depth and semantic maps in perspective views and propose two novel consistency criteria between the rendered outputs of teacher and student models. Specifically, the depth consistency loss aligns the termination distributions of the rendered rays, while the semantic consistency loss mimics the intra-segment similarity guided by vision foundation models (VLMs). Experimental results on the nuScenes dataset demonstrate the effectiveness of our proposed method in improving various 3D occupancy prediction approaches, e.g., our proposed methodology enhances our baseline by 2.2% in the metric of mIoU and achieves 50% in Occ3D benchmark.
FedEdge AI-TC: A Semi-supervised Traffic Classification Method based on Trusted Federated Deep Learning for Mobile Edge Computing
Aug 14, 2023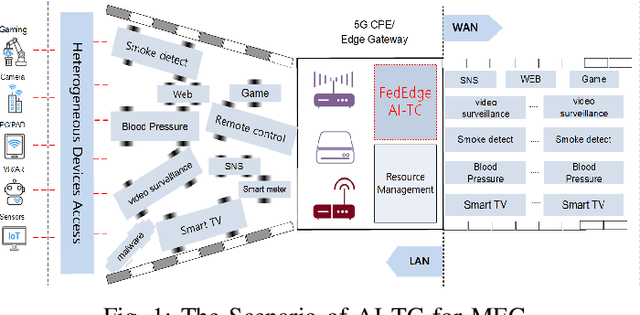
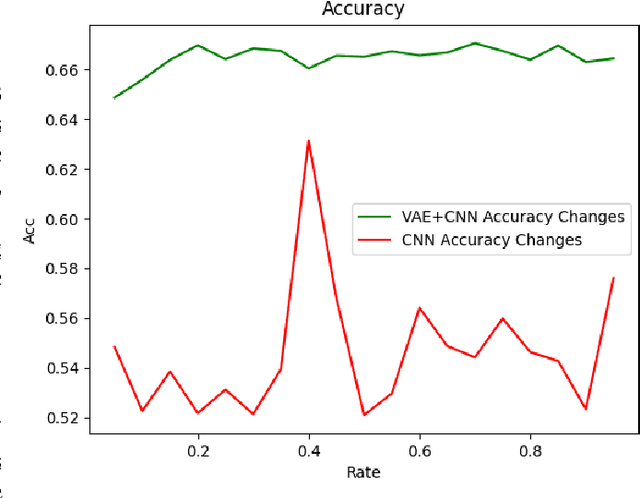
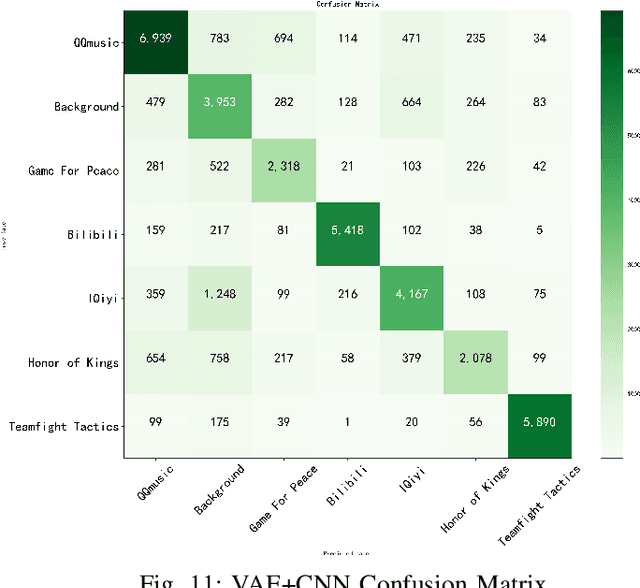
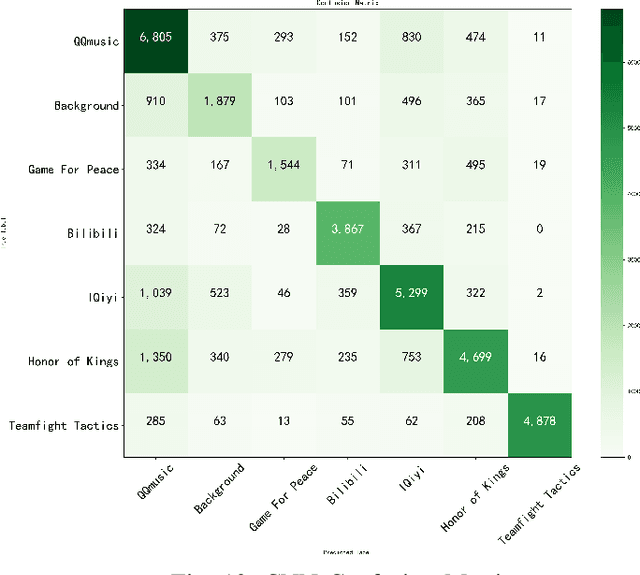
As a typical entity of MEC (Mobile Edge Computing), 5G CPE (Customer Premise Equipment)/HGU (Home Gateway Unit) has proven to be a promising alternative to traditional Smart Home Gateway. Network TC (Traffic Classification) is a vital service quality assurance and security management method for communication networks, which has become a crucial functional entity in 5G CPE/HGU. In recent years, many researchers have applied Machine Learning or Deep Learning (DL) to TC, namely AI-TC, to improve its performance. However, AI-TC faces challenges, including data dependency, resource-intensive traffic labeling, and user privacy concerns. The limited computing resources of 5G CPE further complicate efficient classification. Moreover, the "black box" nature of AI-TC models raises transparency and credibility issues. The paper proposes the FedEdge AI-TC framework, leveraging Federated Learning (FL) for reliable Network TC in 5G CPE. FL ensures privacy by employing local training, model parameter iteration, and centralized training. A semi-supervised TC algorithm based on Variational Auto-Encoder (VAE) and convolutional neural network (CNN) reduces data dependency while maintaining accuracy. To optimize model light-weight deployment, the paper introduces XAI-Pruning, an AI model compression method combined with DL model interpretability. Experimental evaluation demonstrates FedEdge AI-TC's superiority over benchmarks in terms of accuracy and efficient TC performance. The framework enhances user privacy and model credibility, offering a comprehensive solution for dependable and transparent Network TC in 5G CPE, thus enhancing service quality and security.