 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
IQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
3D-SSM: A Novel 3D Selective Scan Module for Remote Sensing Change Detection
Jun 24, 2025Existing Mamba-based approaches in remote sensing change detection have enhanced scanning models, yet remain limited by their inability to capture long-range dependencies between image channels effectively, which restricts their feature representation capabilities. To address this limitation, we propose a 3D selective scan module (3D-SSM) that captures global information from both the spatial plane and channel perspectives, enabling a more comprehensive understanding of the data.Based on the 3D-SSM, we present two key components: a spatiotemporal interaction module (SIM) and a multi-branch feature extraction module (MBFEM). The SIM facilitates bi-temporal feature integration by enabling interactions between global and local features across images from different time points, thereby enhancing the detection of subtle changes. Meanwhile, the MBFEM combines features from the frequency domain, spatial domain, and 3D-SSM to provide a rich representation of contextual information within the image. Our proposed method demonstrates favourable performance compared to state-of-the-art change detection methods on five benchmark datasets through extensive experiments. Code is available at https://github.com/VerdantMist/3D-SSM
CEBSNet: Change-Excited and Background-Suppressed Network with Temporal Dependency Modeling for Bitemporal Change Detection
May 21, 2025Change detection, a critical task in remote sensing and computer vision, aims to identify pixel-level differences between image pairs captured at the same geographic area but different times. It faces numerous challenges such as illumination variation, seasonal changes, background interference, and shooting angles, especially with a large time gap between images. While current methods have advanced, they often overlook temporal dependencies and overemphasize prominent changes while ignoring subtle but equally important changes. To address these limitations, we introduce \textbf{CEBSNet}, a novel change-excited and background-suppressed network with temporal dependency modeling for change detection. During the feature extraction, we utilize a simple Channel Swap Module (CSM) to model temporal dependency, reducing differences and noise. The Feature Excitation and Suppression Module (FESM) is developed to capture both obvious and subtle changes, maintaining the integrity of change regions. Additionally, we design a Pyramid-Aware Spatial-Channel Attention module (PASCA) to enhance the ability to detect change regions at different sizes and focus on critical regions. We conduct extensive experiments on three common street view datasets and two remote sensing datasets, and our method achieves the state-of-the-art performance.
GTPC-SSCD: Gate-guided Two-level Perturbation Consistency-based Semi-Supervised Change Detection
Nov 28, 2024



Semi-supervised change detection (SSCD) employs partially labeled data and a substantial amount of unlabeled data to identify differences between images captured in the same geographic area but at different times. However, existing consistency regularization-based SSCD methods only implement perturbations at a single level and can not exploit the full potential of unlabeled data. In this paper, we introduce a novel Gate-guided Two-level Perturbation Consistency regularization-based SSCD method (GTPC-SSCD), which simultaneously maintains strong-to-weak consistency at the image level and perturbation consistency at the feature level, thus effectively utilizing the unlabeled data. Moreover, a gate module is designed to evaluate the training complexity of different samples and determine the necessity of performing feature perturbations on each sample. This differential treatment enables the network to more effectively explore the potential of unlabeled data. Extensive experiments conducted on six public remote sensing change detection datasets demonstrate the superiority of our method over seven state-of-the-art SSCD methods.
FrameNeRF: A Simple and Efficient Framework for Few-shot Novel View Synthesis
Feb 26, 2024



We present a novel framework, called FrameNeRF, designed to apply off-the-shelf fast high-fidelity NeRF models with fast training speed and high rendering quality for few-shot novel view synthesis tasks. The training stability of fast high-fidelity models is typically constrained to dense views, making them unsuitable for few-shot novel view synthesis tasks. To address this limitation, we utilize a regularization model as a data generator to produce dense views from sparse inputs, facilitating subsequent training of fast high-fidelity models. Since these dense views are pseudo ground truth generated by the regularization model, original sparse images are then used to fine-tune the fast high-fidelity model. This process helps the model learn realistic details and correct artifacts introduced in earlier stages. By leveraging an off-the-shelf regularization model and a fast high-fidelity model, our approach achieves state-of-the-art performance across various benchmark datasets.
A Saliency Enhanced Feature Fusion based multiscale RGB-D Salient Object Detection Network
Jan 22, 2024Multiscale convolutional neural network (CNN) has demonstrated remarkable capabilities in solving various vision problems. However, fusing features of different scales alwaysresults in large model sizes, impeding the application of multiscale CNNs in RGB-D saliency detection. In this paper, we propose a customized feature fusion module, called Saliency Enhanced Feature Fusion (SEFF), for RGB-D saliency detection. SEFF utilizes saliency maps of the neighboring scales to enhance the necessary features for fusing, resulting in more representative fused features. Our multiscale RGB-D saliency detector uses SEFF and processes images with three different scales. SEFF is used to fuse the features of RGB and depth images, as well as the features of decoders at different scales. Extensive experiments on five benchmark datasets have demonstrated the superiority of our method over ten SOTA saliency detectors.
DT-Net: A novel network based on multi-directional integrated convolution and threshold convolution
Sep 26, 2020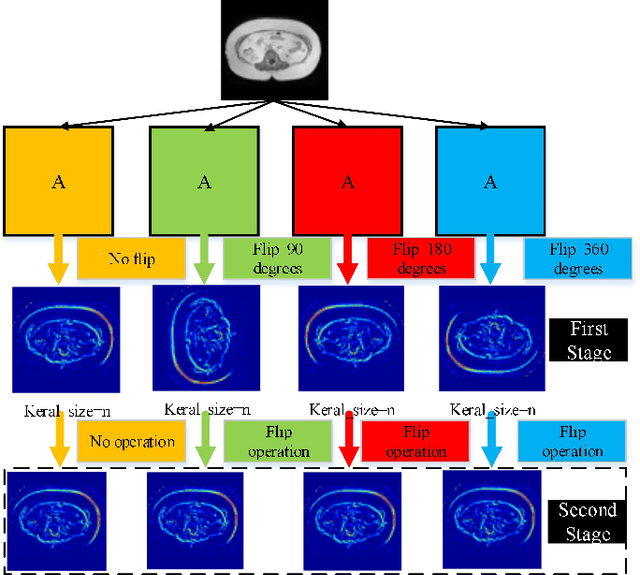
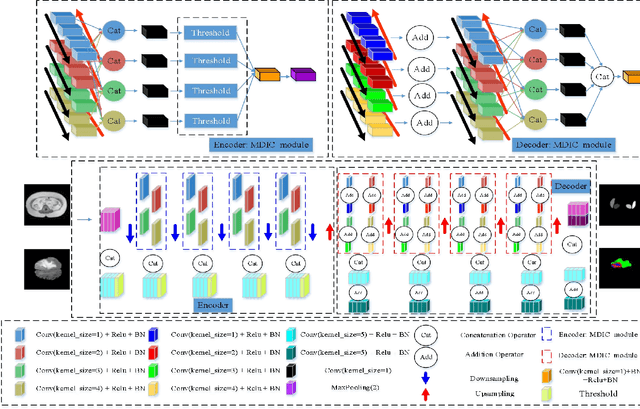
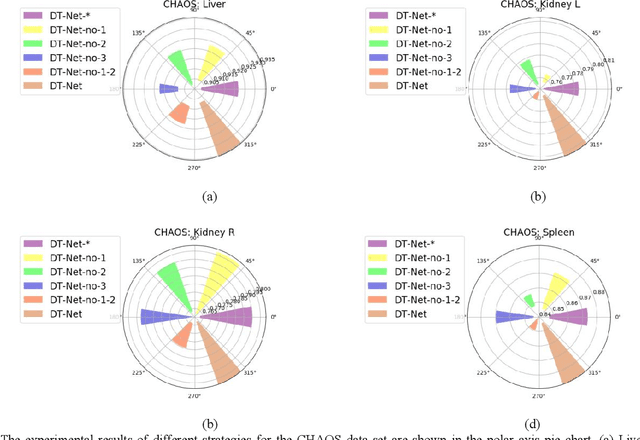
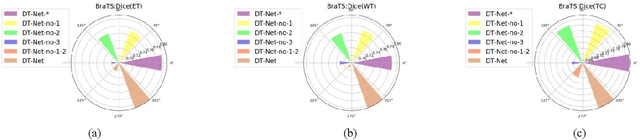
Since medical image data sets contain few samples and singular features, lesions are viewed as highly similar to other tissues. The traditional neural network has a limited ability to learn features. Even if a host of feature maps is expanded to obtain more semantic information, the accuracy of segmenting the final medical image is slightly improved, and the features are excessively redundant. To solve the above problems, in this paper, we propose a novel end-to-end semantic segmentation algorithm, DT-Net, and use two new convolution strategies to better achieve end-to-end semantic segmentation of medical images. 1. In the feature mining and feature fusion stage, we construct a multi-directional integrated convolution (MDIC). The core idea is to use the multi-scale convolution to enhance the local multi-directional feature maps to generate enhanced feature maps and to mine the generated features that contain more semantics without increasing the number of feature maps. 2. We also aim to further excavate and retain more meaningful deep features reduce a host of noise features in the training process. Therefore, we propose a convolution thresholding strategy. The central idea is to set a threshold to eliminate a large number of redundant features and reduce computational complexity. Through the two strategies proposed above, the algorithm proposed in this paper produces state-of-the-art results on two public medical image datasets. We prove in detail that our proposed strategy plays an important role in feature mining and eliminating redundant features. Compared with the existing semantic segmentation algorithms, our proposed algorithm has better robustness.
A New Multiple Max-pooling Integration Module and Cross Multiscale Deconvolution Network Based on Image Semantic Segmentation
Mar 25, 2020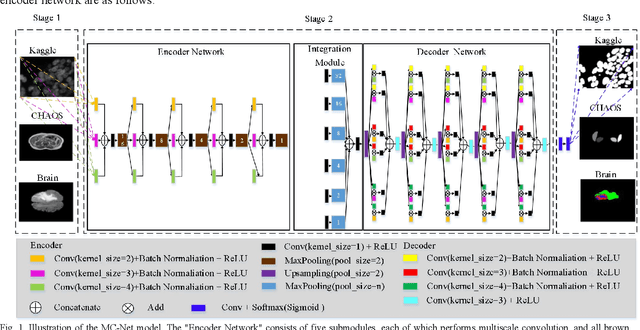
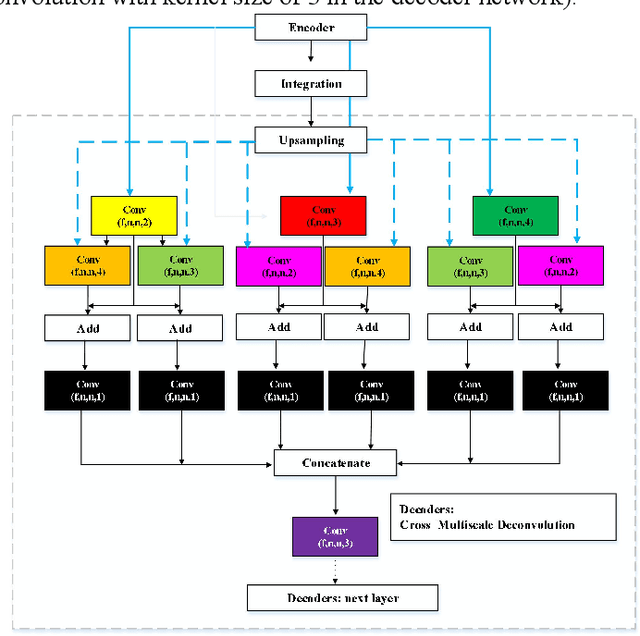

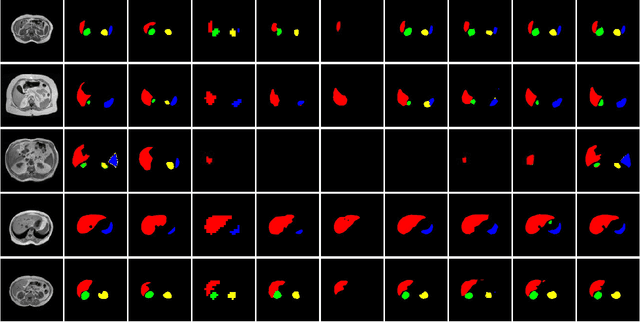
To better retain the deep features of an image and solve the sparsity problem of the end-to-end segmentation model, we propose a new deep convolutional network model for medical image pixel segmentation, called MC-Net. The core of this network model consists of four parts, namely, an encoder network, a multiple max-pooling integration module, a cross multiscale deconvolution decoder network and a pixel-level classification layer. In the network structure of the encoder, we use multiscale convolution instead of the traditional single-channel convolution. The multiple max-pooling integration module first integrates the output features of each submodule of the encoder network and reduces the number of parameters by convolution using a kernel size of 1. At the same time, each max-pooling layer (the pooling size of each layer is different) is spliced after each convolution to achieve the translation invariance of the feature maps of each submodule. We use the output feature maps from the multiple max-pooling integration module as the input of the decoder network; the multiscale convolution of each submodule in the decoder network is cross-fused with the feature maps generated by the corresponding multiscale convolution in the encoder network. Using the above feature map processing methods solves the sparsity problem after the max-pooling layer-generating matrix and enhances the robustness of the classification. We compare our proposed model with the well-known Fully Convolutional Networks for Semantic Segmentation (FCNs), DecovNet, PSPNet, U-net, SgeNet and other state-of-the-art segmentation networks such as HyperDenseNet, MS-Dual, Espnetv2, Denseaspp using one binary Kaggle 2018 data science bowl dataset and two multiclass dataset and obtain encouraging experimental results.