 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDT-Net: A novel network based on multi-directional integrated convolution and threshold convolution
Sep 26, 2020
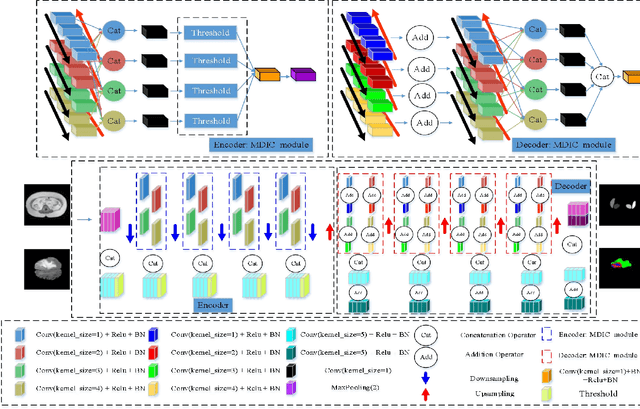
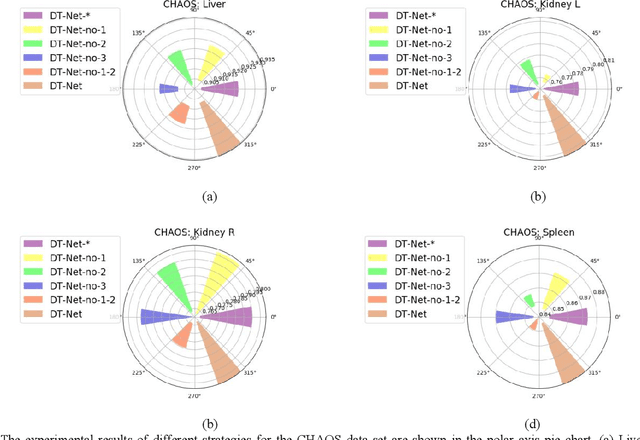
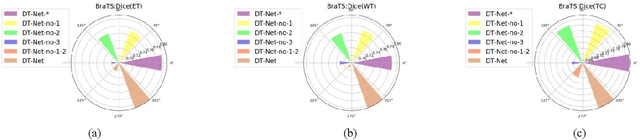
Since medical image data sets contain few samples and singular features, lesions are viewed as highly similar to other tissues. The traditional neural network has a limited ability to learn features. Even if a host of feature maps is expanded to obtain more semantic information, the accuracy of segmenting the final medical image is slightly improved, and the features are excessively redundant. To solve the above problems, in this paper, we propose a novel end-to-end semantic segmentation algorithm, DT-Net, and use two new convolution strategies to better achieve end-to-end semantic segmentation of medical images. 1. In the feature mining and feature fusion stage, we construct a multi-directional integrated convolution (MDIC). The core idea is to use the multi-scale convolution to enhance the local multi-directional feature maps to generate enhanced feature maps and to mine the generated features that contain more semantics without increasing the number of feature maps. 2. We also aim to further excavate and retain more meaningful deep features reduce a host of noise features in the training process. Therefore, we propose a convolution thresholding strategy. The central idea is to set a threshold to eliminate a large number of redundant features and reduce computational complexity. Through the two strategies proposed above, the algorithm proposed in this paper produces state-of-the-art results on two public medical image datasets. We prove in detail that our proposed strategy plays an important role in feature mining and eliminating redundant features. Compared with the existing semantic segmentation algorithms, our proposed algorithm has better robustness.
A New Multiple Max-pooling Integration Module and Cross Multiscale Deconvolution Network Based on Image Semantic Segmentation
Mar 25, 2020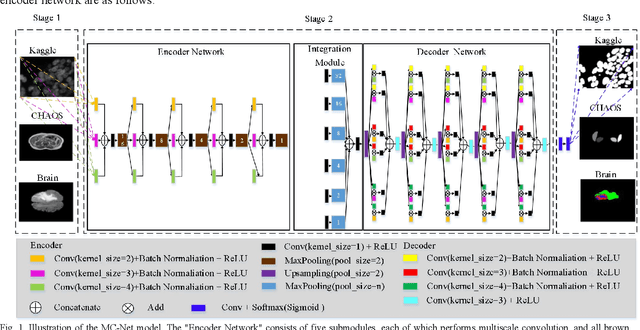
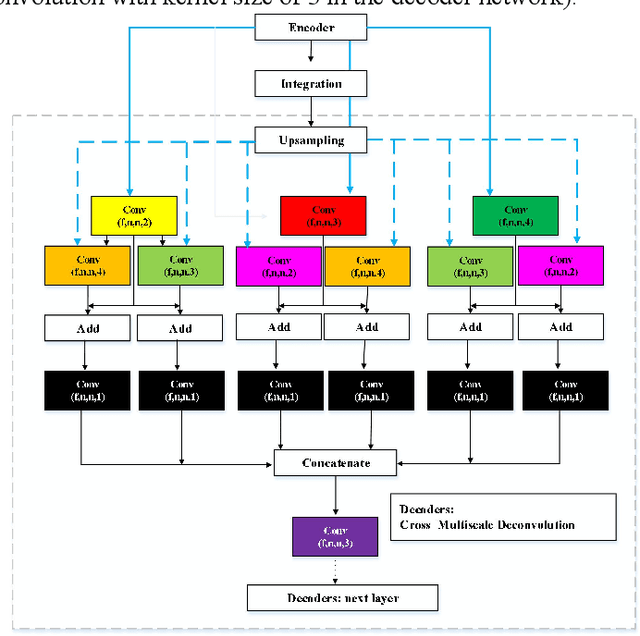

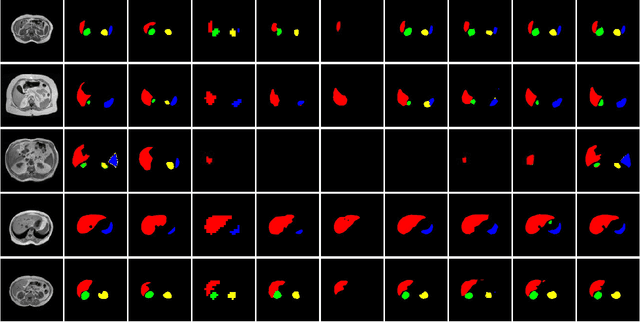
To better retain the deep features of an image and solve the sparsity problem of the end-to-end segmentation model, we propose a new deep convolutional network model for medical image pixel segmentation, called MC-Net. The core of this network model consists of four parts, namely, an encoder network, a multiple max-pooling integration module, a cross multiscale deconvolution decoder network and a pixel-level classification layer. In the network structure of the encoder, we use multiscale convolution instead of the traditional single-channel convolution. The multiple max-pooling integration module first integrates the output features of each submodule of the encoder network and reduces the number of parameters by convolution using a kernel size of 1. At the same time, each max-pooling layer (the pooling size of each layer is different) is spliced after each convolution to achieve the translation invariance of the feature maps of each submodule. We use the output feature maps from the multiple max-pooling integration module as the input of the decoder network; the multiscale convolution of each submodule in the decoder network is cross-fused with the feature maps generated by the corresponding multiscale convolution in the encoder network. Using the above feature map processing methods solves the sparsity problem after the max-pooling layer-generating matrix and enhances the robustness of the classification. We compare our proposed model with the well-known Fully Convolutional Networks for Semantic Segmentation (FCNs), DecovNet, PSPNet, U-net, SgeNet and other state-of-the-art segmentation networks such as HyperDenseNet, MS-Dual, Espnetv2, Denseaspp using one binary Kaggle 2018 data science bowl dataset and two multiclass dataset and obtain encouraging experimental results.