 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMformer with Adaptive Transferable Attention: Advancing Multivariate Time Series Forecasting for Environmental Applications
Apr 18, 2025



Environmental crisis remains a global challenge that affects public health and environmental quality. Despite extensive research, accurately forecasting environmental change trends to inform targeted policies and assess prediction efficiency remains elusive. Conventional methods for multivariate time series (MTS) analysis often fail to capture the complex dynamics of environmental change. To address this, we introduce an innovative meta-learning MTS model, MMformer with Adaptive Transferable Multi-head Attention (ATMA), which combines self-attention and meta-learning for enhanced MTS forecasting. Specifically, MMformer is used to model and predict the time series of seven air quality indicators across 331 cities in China from January 2018 to June 2021 and the time series of precipitation and temperature at 2415 monitoring sites during the summer (276 days) from 2012 to 2014, validating the network's ability to perform and forecast MTS data successfully. Experimental results demonstrate that in these datasets, the MMformer model reaching SOTA outperforms iTransformer, Transformer, and the widely used traditional time series prediction algorithm SARIMAX in the prediction of MTS, reducing by 50\% in MSE, 20\% in MAE as compared to others in air quality datasets, reducing by 20\% in MAPE except SARIMAX. Compared with Transformer and SARIMAX in the climate datasets, MSE, MAE, and MAPE are decreased by 30\%, and there is an improvement compared to iTransformer. This approach represents a significant advance in our ability to forecast and respond to dynamic environmental quality challenges in diverse urban and rural environments. Its predictive capabilities provide valuable public health and environmental quality information, informing targeted interventions.
A New Multiple Max-pooling Integration Module and Cross Multiscale Deconvolution Network Based on Image Semantic Segmentation
Mar 25, 2020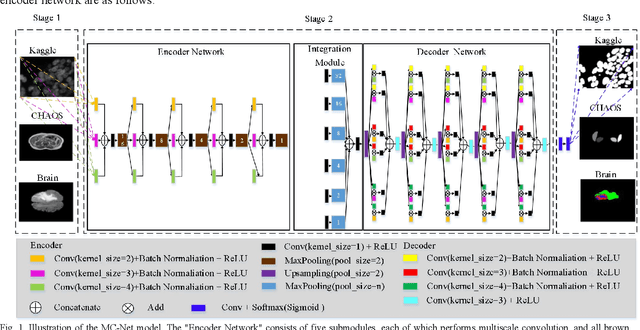
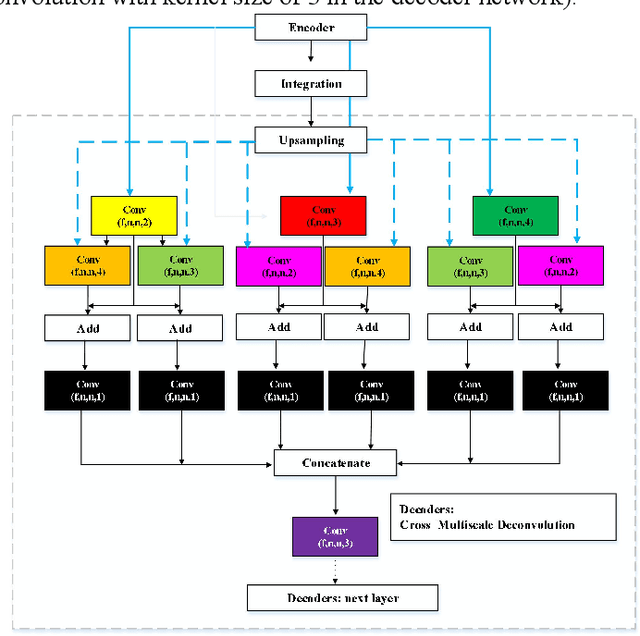

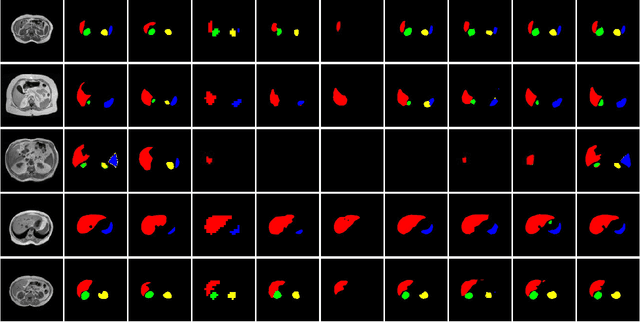
To better retain the deep features of an image and solve the sparsity problem of the end-to-end segmentation model, we propose a new deep convolutional network model for medical image pixel segmentation, called MC-Net. The core of this network model consists of four parts, namely, an encoder network, a multiple max-pooling integration module, a cross multiscale deconvolution decoder network and a pixel-level classification layer. In the network structure of the encoder, we use multiscale convolution instead of the traditional single-channel convolution. The multiple max-pooling integration module first integrates the output features of each submodule of the encoder network and reduces the number of parameters by convolution using a kernel size of 1. At the same time, each max-pooling layer (the pooling size of each layer is different) is spliced after each convolution to achieve the translation invariance of the feature maps of each submodule. We use the output feature maps from the multiple max-pooling integration module as the input of the decoder network; the multiscale convolution of each submodule in the decoder network is cross-fused with the feature maps generated by the corresponding multiscale convolution in the encoder network. Using the above feature map processing methods solves the sparsity problem after the max-pooling layer-generating matrix and enhances the robustness of the classification. We compare our proposed model with the well-known Fully Convolutional Networks for Semantic Segmentation (FCNs), DecovNet, PSPNet, U-net, SgeNet and other state-of-the-art segmentation networks such as HyperDenseNet, MS-Dual, Espnetv2, Denseaspp using one binary Kaggle 2018 data science bowl dataset and two multiclass dataset and obtain encouraging experimental results.