 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Difference: Find Any Change Instance in 3D Scenes
Feb 24, 2025Instance-level change detection in 3D scenes presents significant challenges, particularly in uncontrolled environments lacking labeled image pairs, consistent camera poses, or uniform lighting conditions. This paper addresses these challenges by introducing a novel approach for detecting changes in real-world scenarios. Our method leverages 4D Gaussians to embed multiple images into Gaussian distributions, enabling the rendering of two coherent image sequences. We segment each image and assign unique identifiers to instances, facilitating efficient change detection through ID comparison. Additionally, we utilize change maps and classification encodings to categorize 4D Gaussians as changed or unchanged, allowing for the rendering of comprehensive change maps from any viewpoint. Extensive experiments across various instance-level change detection datasets demonstrate that our method significantly outperforms state-of-the-art approaches like C-NERF and CYWS-3D, especially in scenarios with substantial lighting variations. Our approach offers improved detection accuracy, robustness to lighting changes, and efficient processing times, advancing the field of 3D change detection.
A Saliency Enhanced Feature Fusion based multiscale RGB-D Salient Object Detection Network
Jan 22, 2024Multiscale convolutional neural network (CNN) has demonstrated remarkable capabilities in solving various vision problems. However, fusing features of different scales alwaysresults in large model sizes, impeding the application of multiscale CNNs in RGB-D saliency detection. In this paper, we propose a customized feature fusion module, called Saliency Enhanced Feature Fusion (SEFF), for RGB-D saliency detection. SEFF utilizes saliency maps of the neighboring scales to enhance the necessary features for fusing, resulting in more representative fused features. Our multiscale RGB-D saliency detector uses SEFF and processes images with three different scales. SEFF is used to fuse the features of RGB and depth images, as well as the features of decoders at different scales. Extensive experiments on five benchmark datasets have demonstrated the superiority of our method over ten SOTA saliency detectors.
C-NERF: Representing Scene Changes as Directional Consistency Difference-based NeRF
Dec 23, 2023In this work, we aim to detect the changes caused by object variations in a scene represented by the neural radiance fields (NeRFs). Given an arbitrary view and two sets of scene images captured at different timestamps, we can predict the scene changes in that view, which has significant potential applications in scene monitoring and measuring. We conducted preliminary studies and found that such an exciting task cannot be easily achieved by utilizing existing NeRFs and 2D change detection methods with many false or missing detections. The main reason is that the 2D change detection is based on the pixel appearance difference between spatial-aligned image pairs and neglects the stereo information in the NeRF. To address the limitations, we propose the C-NERF to represent scene changes as directional consistency difference-based NeRF, which mainly contains three modules. We first perform the spatial alignment of two NeRFs captured before and after changes. Then, we identify the change points based on the direction-consistent constraint; that is, real change points have similar change representations across view directions, but fake change points do not. Finally, we design the change map rendering process based on the built NeRFs and can generate the change map of an arbitrarily specified view direction. To validate the effectiveness, we build a new dataset containing ten scenes covering diverse scenarios with different changing objects. Our approach surpasses state-of-the-art 2D change detection and NeRF-based methods by a significant margin.
Modeling Communication to Coordinate Perspectives in Cooperation
Jun 03, 2021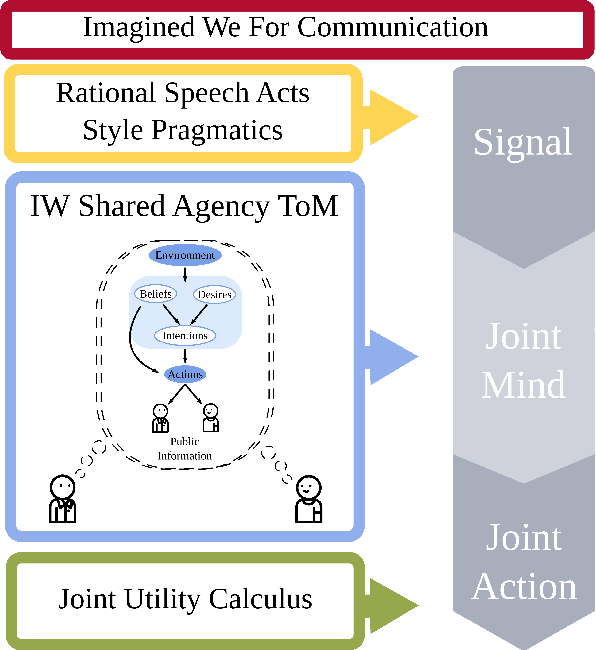
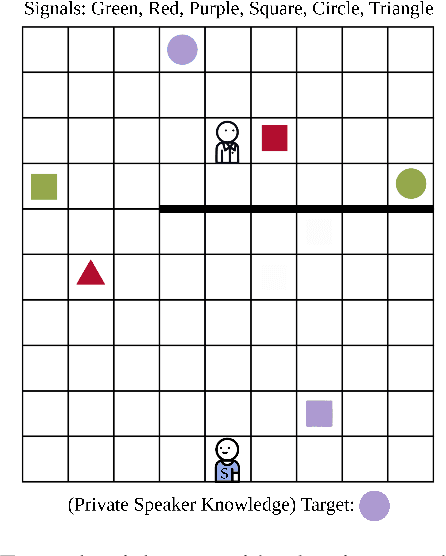
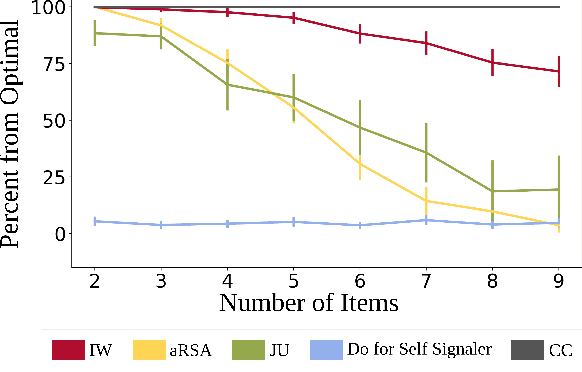
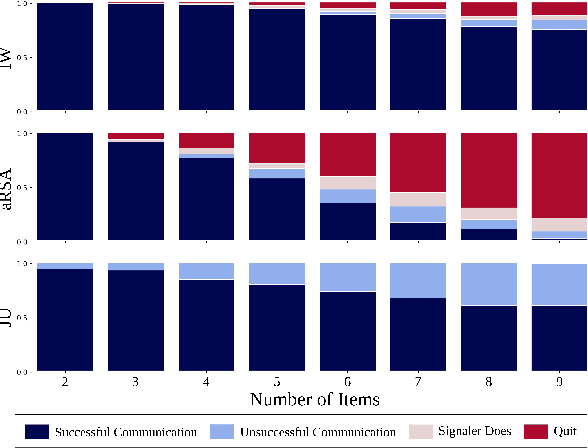
Communication is highly overloaded. Despite this, even young children are good at leveraging context to understand ambiguous signals. We propose a computational account of overloaded signaling from a shared agency perspective which we call the Imagined We for Communication. Under this framework, communication helps cooperators coordinate their perspectives, allowing them to act together to achieve shared goals. We assume agents are rational cooperators, which puts constraints on how signals can be sent and interpreted. We implement this model in a set of simulations demonstrating this model's success under increasing ambiguity as well as increasing layers of reasoning. Our model is capable of improving performance with deeper recursive reasoning; however, it outperforms comparison baselines at even the shallowest level, highlighting how shared knowledge and cooperative logic can do much of the heavy-lifting in language.