 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlace Cells as Position Embeddings of Multi-Time Random Walk Transition Kernels for Path Planning
May 20, 2025The hippocampus orchestrates spatial navigation through collective place cell encodings that form cognitive maps. We reconceptualize the population of place cells as position embeddings approximating multi-scale symmetric random walk transition kernels: the inner product $\langle h(x, t), h(y, t) \rangle = q(y|x, t)$ represents normalized transition probabilities, where $h(x, t)$ is the embedding at location $ x $, and $q(y|x, t)$ is the normalized symmetric transition probability over time $t$. The time parameter $\sqrt{t}$ defines a spatial scale hierarchy, mirroring the hippocampal dorsoventral axis. $q(y|x, t)$ defines spatial adjacency between $x$ and $y$ at scale or resolution $\sqrt{t}$, and the pairwise adjacency relationships $(q(y|x, t), \forall x, y)$ are reduced into individual embeddings $(h(x, t), \forall x)$ that collectively form a map of the environment at sale $\sqrt{t}$. Our framework employs gradient ascent on $q(y|x, t) = \langle h(x, t), h(y, t)\rangle$ with adaptive scale selection, choosing the time scale with maximal gradient at each step for trap-free, smooth trajectories. Efficient matrix squaring $P_{2t} = P_t^2$ builds global representations from local transitions $P_1$ without memorizing past trajectories, enabling hippocampal preplay-like path planning. This produces robust navigation through complex environments, aligning with hippocampal navigation. Experimental results show that our model captures place cell properties -- field size distribution, adaptability, and remapping -- while achieving computational efficiency. By modeling collective transition probabilities rather than individual place fields, we offer a biologically plausible, scalable framework for spatial navigation.
Latent Adaptive Planner for Dynamic Manipulation
May 06, 2025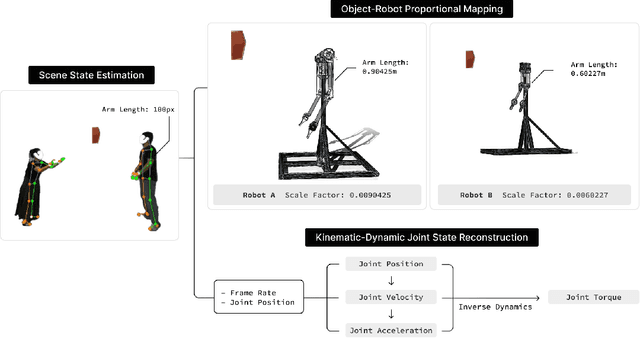
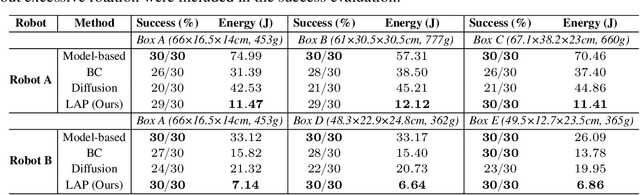
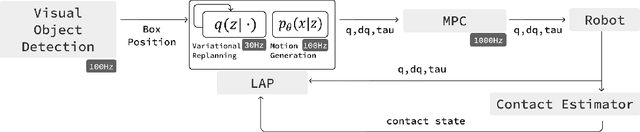

This paper presents Latent Adaptive Planner (LAP), a novel approach for dynamic nonprehensile manipulation tasks that formulates planning as latent space inference, effectively learned from human demonstration videos. Our method addresses key challenges in visuomotor policy learning through a principled variational replanning framework that maintains temporal consistency while efficiently adapting to environmental changes. LAP employs Bayesian updating in latent space to incrementally refine plans as new observations become available, striking an optimal balance between computational efficiency and real-time adaptability. We bridge the embodiment gap between humans and robots through model-based proportional mapping that regenerates accurate kinematic-dynamic joint states and object positions from human demonstrations. Experimental evaluations across multiple complex manipulation benchmarks demonstrate that LAP achieves state-of-the-art performance, outperforming existing approaches in success rate, trajectory smoothness, and energy efficiency, particularly in dynamic adaptation scenarios. Our approach enables robots to perform complex interactions with human-like adaptability while providing an expandable framework applicable to diverse robotic platforms using the same human demonstration videos.
Scalable Language Models with Posterior Inference of Latent Thought Vectors
Feb 03, 2025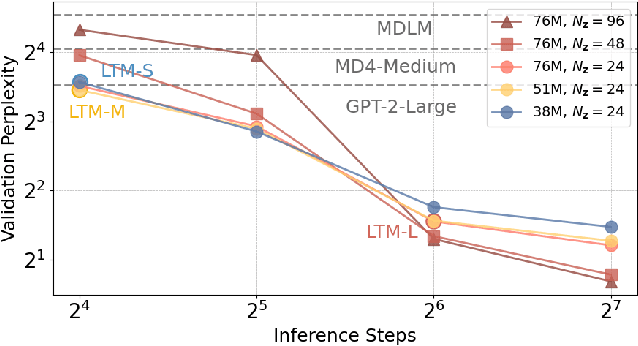
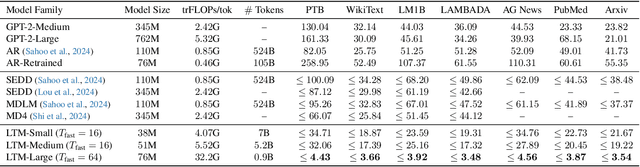
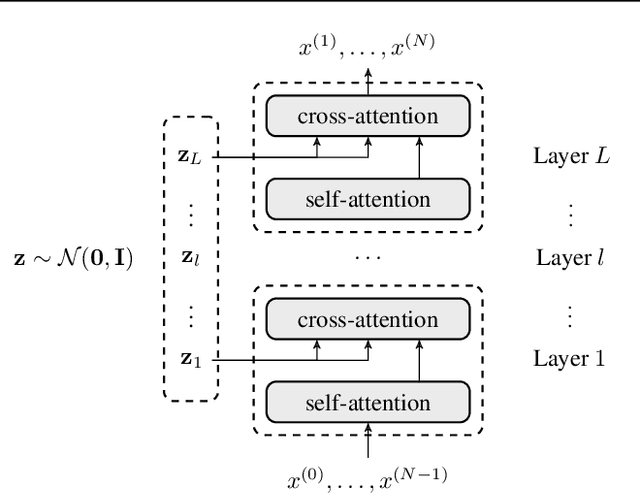
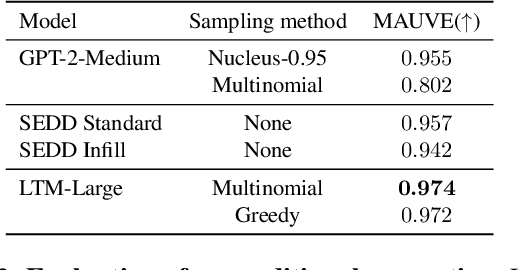
We propose a novel family of language models, Latent-Thought Language Models (LTMs), which incorporate explicit latent thought vectors that follow an explicit prior model in latent space. These latent thought vectors guide the autoregressive generation of ground tokens through a Transformer decoder. Training employs a dual-rate optimization process within the classical variational Bayes framework: fast learning of local variational parameters for the posterior distribution of latent vectors, and slow learning of global decoder parameters. Empirical studies reveal that LTMs possess additional scaling dimensions beyond traditional LLMs, yielding a structured design space. Higher sample efficiency can be achieved by increasing training compute per token, with further gains possible by trading model size for more inference steps. Designed based on these scaling properties, LTMs demonstrate superior sample and parameter efficiency compared to conventional autoregressive models and discrete diffusion models. They significantly outperform these counterparts in validation perplexity and zero-shot language modeling. Additionally, LTMs exhibit emergent few-shot in-context reasoning capabilities that scale with model and latent size, and achieve competitive performance in conditional and unconditional text generation.
A minimalistic representation model for head direction system
Nov 15, 2024



We present a minimalistic representation model for the head direction (HD) system, aiming to learn a high-dimensional representation of head direction that captures essential properties of HD cells. Our model is a representation of rotation group $U(1)$, and we study both the fully connected version and convolutional version. We demonstrate the emergence of Gaussian-like tuning profiles and a 2D circle geometry in both versions of the model. We also demonstrate that the learned model is capable of accurate path integration.
Inverse Attention Agent for Multi-Agent System
Oct 29, 2024
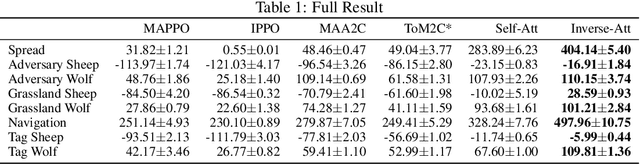

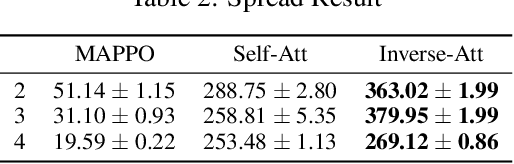
A major challenge for Multi-Agent Systems is enabling agents to adapt dynamically to diverse environments in which opponents and teammates may continually change. Agents trained using conventional methods tend to excel only within the confines of their training cohorts; their performance drops significantly when confronting unfamiliar agents. To address this shortcoming, we introduce Inverse Attention Agents that adopt concepts from the Theory of Mind, implemented algorithmically using an attention mechanism and trained in an end-to-end manner. Crucial to determining the final actions of these agents, the weights in their attention model explicitly represent attention to different goals. We furthermore propose an inverse attention network that deduces the ToM of agents based on observations and prior actions. The network infers the attentional states of other agents, thereby refining the attention weights to adjust the agent's final action. We conduct experiments in a continuous environment, tackling demanding tasks encompassing cooperation, competition, and a blend of both. They demonstrate that the inverse attention network successfully infers the attention of other agents, and that this information improves agent performance. Additional human experiments show that, compared to baseline agent models, our inverse attention agents exhibit superior cooperation with humans and better emulate human behaviors.
Latent Plan Transformer: Planning as Latent Variable Inference
Feb 07, 2024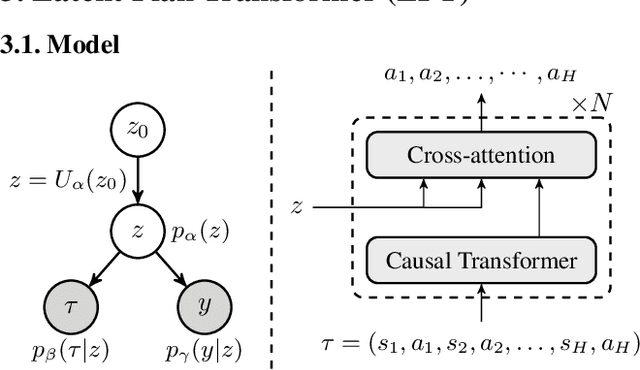
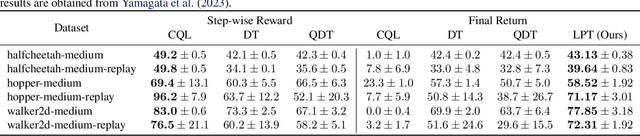

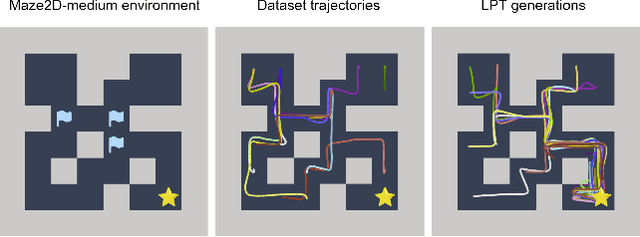
In tasks aiming for long-term returns, planning becomes necessary. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent space to connect a Transformer-based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally gathers sub-trajectories to form a consistent abstraction despite the finite context. During test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. It then guides the autoregressive policy throughout the episode, functioning as a plan. Our experiments demonstrate that LPT can discover improved decisions from suboptimal trajectories. It achieves competitive performance across several benchmarks, including Gym-Mujoco, Maze2D, and Connect Four, exhibiting capabilities of nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.
Modeling Communication to Coordinate Perspectives in Cooperation
Jun 03, 2021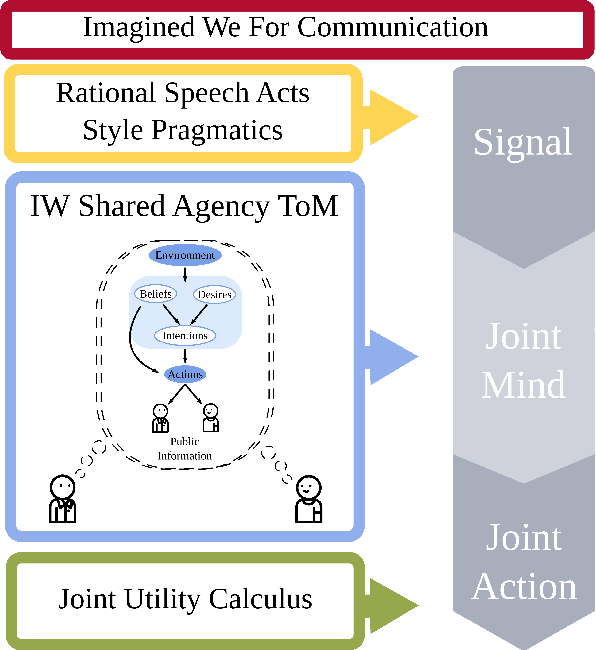
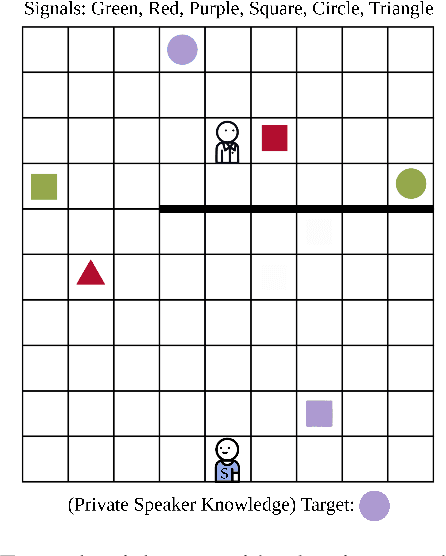
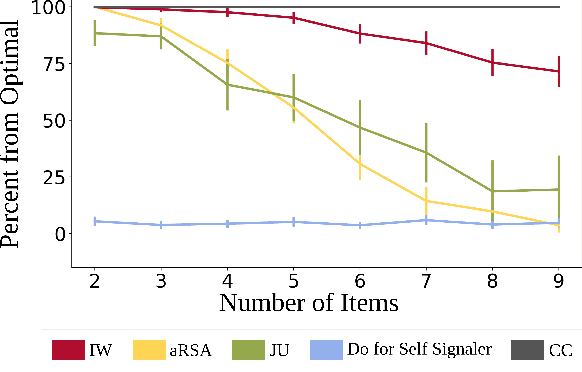
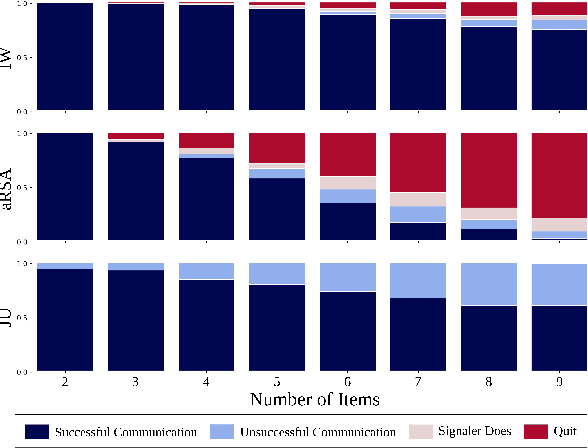
Communication is highly overloaded. Despite this, even young children are good at leveraging context to understand ambiguous signals. We propose a computational account of overloaded signaling from a shared agency perspective which we call the Imagined We for Communication. Under this framework, communication helps cooperators coordinate their perspectives, allowing them to act together to achieve shared goals. We assume agents are rational cooperators, which puts constraints on how signals can be sent and interpreted. We implement this model in a set of simulations demonstrating this model's success under increasing ambiguity as well as increasing layers of reasoning. Our model is capable of improving performance with deeper recursive reasoning; however, it outperforms comparison baselines at even the shallowest level, highlighting how shared knowledge and cooperative logic can do much of the heavy-lifting in language.