 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphDancer: Training LLMs to Explore and Reason over Graphs via Curriculum Reinforcement Learning
Jan 24, 2026Large language models (LLMs) increasingly rely on external knowledge to improve factuality, yet many real-world knowledge sources are organized as heterogeneous graphs rather than plain text. Reasoning over such graph-structured knowledge poses two key challenges: (1) navigating structured, schema-defined relations requires precise function calls rather than similarity-based retrieval, and (2) answering complex questions often demands multi-hop evidence aggregation through iterative information seeking. We propose GraphDancer, a reinforcement learning (RL) framework that teaches LLMs to navigate graphs by interleaving reasoning and function execution. To make RL effective for moderate-sized LLMs, we introduce a graph-aware curriculum that schedules training by the structural complexity of information-seeking trajectories using an easy-to-hard biased sampler. We evaluate GraphDancer on a multi-domain benchmark by training on one domain only and testing on unseen domains and out-of-distribution question types. Despite using only a 3B backbone, GraphDancer outperforms baselines equipped with either a 14B backbone or GPT-4o-mini, demonstrating robust cross-domain generalization of graph exploration and reasoning skills. Our code and models can be found at https://yuyangbai.com/graphdancer/ .
CVP: Central-Peripheral Vision-Inspired Multimodal Model for Spatial Reasoning
Dec 09, 2025We present a central-peripheral vision-inspired framework (CVP), a simple yet effective multimodal model for spatial reasoning that draws inspiration from the two types of human visual fields -- central vision and peripheral vision. Existing approaches primarily rely on unstructured representations, such as point clouds, voxels, or patch features, and inject scene context implicitly via coordinate embeddings. However, this often results in limited spatial reasoning capabilities due to the lack of explicit, high-level structural understanding. To address this limitation, we introduce two complementary components into a Large Multimodal Model-based architecture: target-affinity token, analogous to central vision, that guides the model's attention toward query-relevant objects; and allocentric grid, akin to peripheral vision, that captures global scene context and spatial arrangements. These components work in tandem to enable structured, context-aware understanding of complex 3D environments. Experiments show that CVP achieves state-of-the-art performance across a range of 3D scene understanding benchmarks.
VideoNSA: Native Sparse Attention Scales Video Understanding
Oct 02, 2025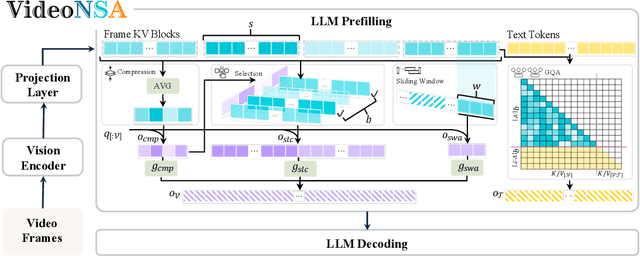
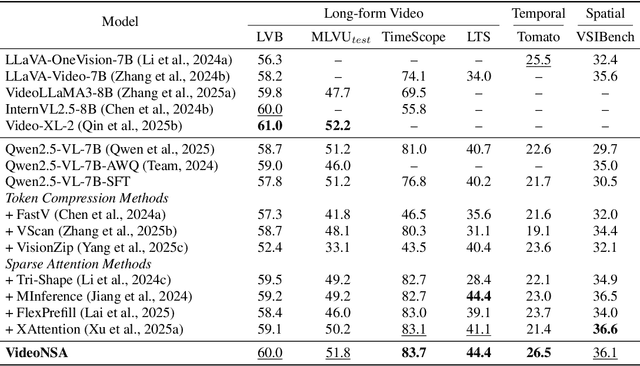
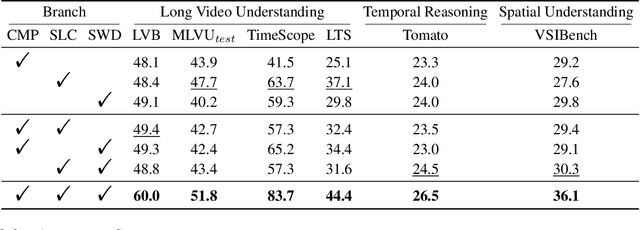
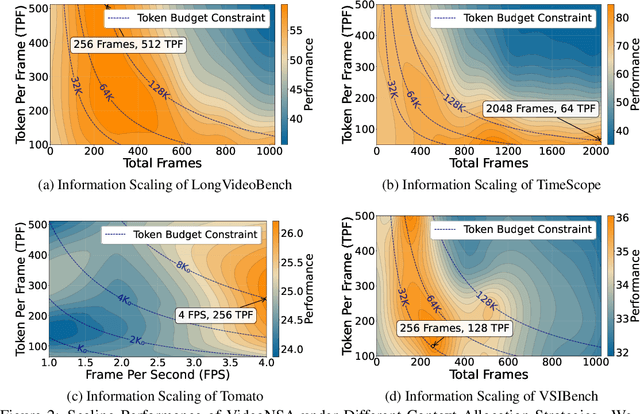
Video understanding in multimodal language models remains limited by context length: models often miss key transition frames and struggle to maintain coherence across long time scales. To address this, we adapt Native Sparse Attention (NSA) to video-language models. Our method, VideoNSA, adapts Qwen2.5-VL through end-to-end training on a 216K video instruction dataset. We employ a hardware-aware hybrid approach to attention, preserving dense attention for text, while employing NSA for video. Compared to token-compression and training-free sparse baselines, VideoNSA achieves improved performance on long-video understanding, temporal reasoning, and spatial benchmarks. Further ablation analysis reveals four key findings: (1) reliable scaling to 128K tokens; (2) an optimal global-local attention allocation at a fixed budget; (3) task-dependent branch usage patterns; and (4) the learnable combined sparse attention help induce dynamic attention sinks.
DepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
Jul 30, 2025We propose DepR, a depth-guided single-view scene reconstruction framework that integrates instance-level diffusion within a compositional paradigm. Instead of reconstructing the entire scene holistically, DepR generates individual objects and subsequently composes them into a coherent 3D layout. Unlike previous methods that use depth solely for object layout estimation during inference and therefore fail to fully exploit its rich geometric information, DepR leverages depth throughout both training and inference. Specifically, we introduce depth-guided conditioning to effectively encode shape priors into diffusion models. During inference, depth further guides DDIM sampling and layout optimization, enhancing alignment between the reconstruction and the input image. Despite being trained on limited synthetic data, DepR achieves state-of-the-art performance and demonstrates strong generalization in single-view scene reconstruction, as shown through evaluations on both synthetic and real-world datasets.
Tensor Decomposition Networks for Fast Machine Learning Interatomic Potential Computations
Jul 01, 2025$\rm{SO}(3)$-equivariant networks are the dominant models for machine learning interatomic potentials (MLIPs). The key operation of such networks is the Clebsch-Gordan (CG) tensor product, which is computationally expensive. To accelerate the computation, we develop tensor decomposition networks (TDNs) as a class of approximately equivariant networks whose CG tensor products are replaced by low-rank tensor decompositions, such as the CANDECOMP/PARAFAC (CP) decomposition. With the CP decomposition, we prove (i) a uniform bound on the induced error of $\rm{SO}(3)$-equivariance, and (ii) the universality of approximating any equivariant bilinear map. To further reduce the number of parameters, we propose path-weight sharing that ties all multiplicity-space weights across the $O(L^3)$ CG paths into a single path without compromising equivariance, where $L$ is the maximum angular degree. The resulting layer acts as a plug-and-play replacement for tensor products in existing networks, and the computational complexity of tensor products is reduced from $O(L^6)$ to $O(L^4)$. We evaluate TDNs on PubChemQCR, a newly curated molecular relaxation dataset containing 105 million DFT-calculated snapshots. We also use existing datasets, including OC20, and OC22. Results show that TDNs achieve competitive performance with dramatic speedup in computations.
Natural Language Guided Ligand-Binding Protein Design
Jun 11, 2025Can AI protein models follow human language instructions and design proteins with desired functions (e.g. binding to a ligand)? Designing proteins that bind to a given ligand is crucial in a wide range of applications in biology and chemistry. Most prior AI models are trained on protein-ligand complex data, which is scarce due to the high cost and time requirements of laboratory experiments. In contrast, there is a substantial body of human-curated text descriptions about protein-ligand interactions and ligand formula. In this paper, we propose InstructPro, a family of protein generative models that follow natural language instructions to design ligand-binding proteins. Given a textual description of the desired function and a ligand formula in SMILES, InstructPro generates protein sequences that are functionally consistent with the specified instructions. We develop the model architecture, training strategy, and a large-scale dataset, InstructProBench, to support both training and evaluation. InstructProBench consists of 9,592,829 triples of (function description, ligand formula, protein sequence). We train two model variants: InstructPro-1B (with 1 billion parameters) and InstructPro-3B~(with 3 billion parameters). Both variants consistently outperform strong baselines, including ProGen2, ESM3, and Pinal. Notably, InstructPro-1B achieves the highest docking success rate (81.52% at moderate confidence) and the lowest average root mean square deviation (RMSD) compared to ground truth structures (4.026{\AA}). InstructPro-3B further descreases the average RMSD to 2.527{\AA}, demonstrating InstructPro's ability to generate ligand-binding proteins that align with the functional specifications.
DEL-ToM: Inference-Time Scaling for Theory-of-Mind Reasoning via Dynamic Epistemic Logic
May 22, 2025Theory-of-Mind (ToM) tasks pose a unique challenge for small language models (SLMs) with limited scale, which often lack the capacity to perform deep social reasoning. In this work, we propose DEL-ToM, a framework that improves ToM reasoning through inference-time scaling rather than architectural changes. Our approach decomposes ToM tasks into a sequence of belief updates grounded in Dynamic Epistemic Logic (DEL), enabling structured and transparent reasoning. We train a verifier, called the Process Belief Model (PBM), to score each belief update step using labels generated automatically via a DEL simulator. During inference, candidate belief traces generated by a language model are evaluated by the PBM, and the highest-scoring trace is selected. This allows SLMs to emulate more deliberate reasoning by allocating additional compute at test time. Experiments across multiple model scales and benchmarks show that DEL-ToM consistently improves performance, demonstrating that verifiable belief supervision can significantly enhance ToM abilities of SLMs without retraining.
Latent Adaptive Planner for Dynamic Manipulation
May 06, 2025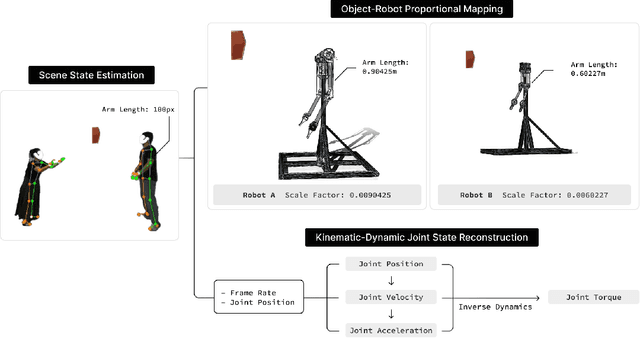
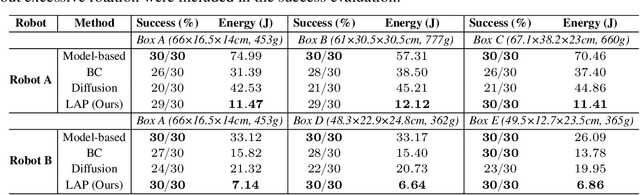
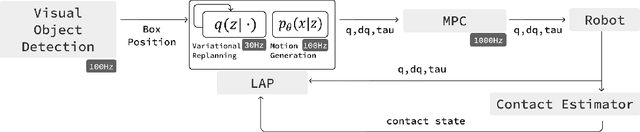

This paper presents Latent Adaptive Planner (LAP), a novel approach for dynamic nonprehensile manipulation tasks that formulates planning as latent space inference, effectively learned from human demonstration videos. Our method addresses key challenges in visuomotor policy learning through a principled variational replanning framework that maintains temporal consistency while efficiently adapting to environmental changes. LAP employs Bayesian updating in latent space to incrementally refine plans as new observations become available, striking an optimal balance between computational efficiency and real-time adaptability. We bridge the embodiment gap between humans and robots through model-based proportional mapping that regenerates accurate kinematic-dynamic joint states and object positions from human demonstrations. Experimental evaluations across multiple complex manipulation benchmarks demonstrate that LAP achieves state-of-the-art performance, outperforming existing approaches in success rate, trajectory smoothness, and energy efficiency, particularly in dynamic adaptation scenarios. Our approach enables robots to perform complex interactions with human-like adaptability while providing an expandable framework applicable to diverse robotic platforms using the same human demonstration videos.
SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
Apr 28, 2025



Recent studies in 3D spatial reasoning explore data-driven approaches and achieve enhanced spatial reasoning performance with reinforcement learning (RL). However, these methods typically perform spatial reasoning in an implicit manner, and it remains underexplored whether the acquired 3D knowledge generalizes to unseen question types at any stage of the training. In this work we introduce SpatialReasoner, a novel large vision-language model (LVLM) that address 3D spatial reasoning with explicit 3D representations shared between stages -- 3D perception, computation, and reasoning. Explicit 3D representations provide a coherent interface that supports advanced 3D spatial reasoning and enable us to study the factual errors made by LVLMs. Results show that our SpatialReasoner achieve improved performance on a variety of spatial reasoning benchmarks and generalizes better when evaluating on novel 3D spatial reasoning questions. Our study bridges the 3D parsing capabilities of prior visual foundation models with the powerful reasoning abilities of large language models, opening new directions for 3D spatial reasoning.
Video-MMLU: A Massive Multi-Discipline Lecture Understanding Benchmark
Apr 20, 2025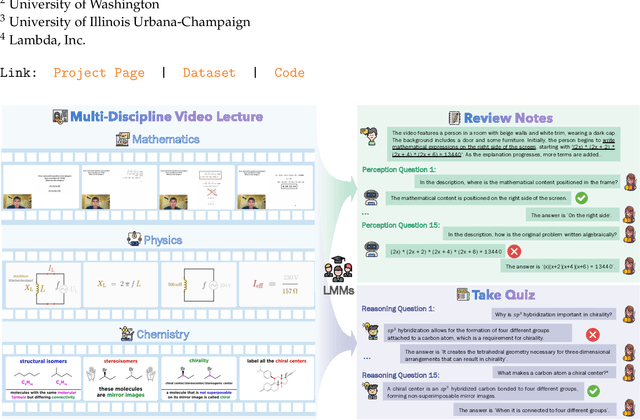
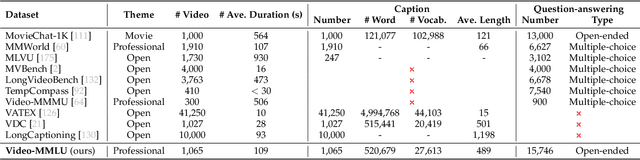
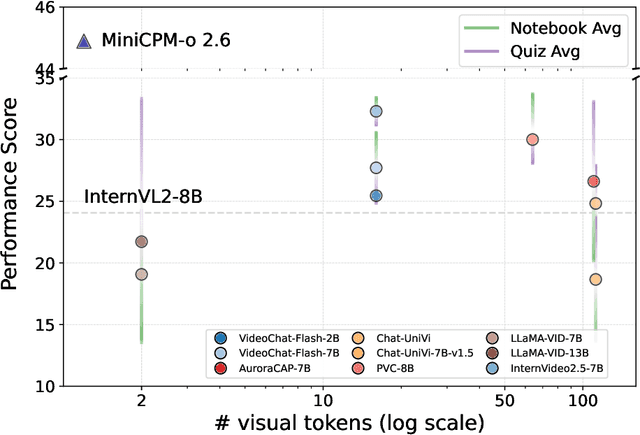
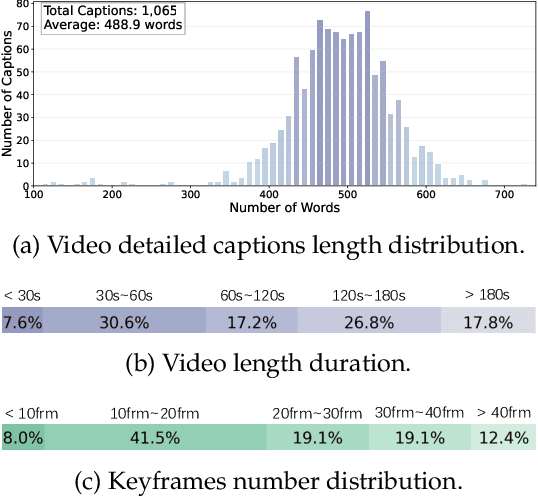
Recent advancements in language multimodal models (LMMs) for video have demonstrated their potential for understanding video content, yet the task of comprehending multi-discipline lectures remains largely unexplored. We introduce Video-MMLU, a massive benchmark designed to evaluate the capabilities of LMMs in understanding Multi-Discipline Lectures. We evaluate over 90 open-source and proprietary models, ranging from 0.5B to 40B parameters. Our results highlight the limitations of current models in addressing the cognitive challenges presented by these lectures, especially in tasks requiring both perception and reasoning. Additionally, we explore how the number of visual tokens and the large language models influence performance, offering insights into the interplay between multimodal perception and reasoning in lecture comprehension.