 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Twice Before You Act: Improving Inverse Problem Solving With MCMC
Sep 13, 2024Recent studies demonstrate that diffusion models can serve as a strong prior for solving inverse problems. A prominent example is Diffusion Posterior Sampling (DPS), which approximates the posterior distribution of data given the measure using Tweedie's formula. Despite the merits of being versatile in solving various inverse problems without re-training, the performance of DPS is hindered by the fact that this posterior approximation can be inaccurate especially for high noise levels. Therefore, we propose \textbf{D}iffusion \textbf{P}osterior \textbf{MC}MC (\textbf{DPMC}), a novel inference algorithm based on Annealed MCMC to solve inverse problems with pretrained diffusion models. We define a series of intermediate distributions inspired by the approximated conditional distributions used by DPS. Through annealed MCMC sampling, we encourage the samples to follow each intermediate distribution more closely before moving to the next distribution at a lower noise level, and therefore reduce the accumulated error along the path. We test our algorithm in various inverse problems, including super resolution, Gaussian deblurring, motion deblurring, inpainting, and phase retrieval. Our algorithm outperforms DPS with less number of evaluations across nearly all tasks, and is competitive among existing approaches.
Flow Priors for Linear Inverse Problems via Iterative Corrupted Trajectory Matching
May 29, 2024Generative models based on flow matching have attracted significant attention for their simplicity and superior performance in high-resolution image synthesis. By leveraging the instantaneous change-of-variables formula, one can directly compute image likelihoods from a learned flow, making them enticing candidates as priors for downstream tasks such as inverse problems. In particular, a natural approach would be to incorporate such image probabilities in a maximum-a-posteriori (MAP) estimation problem. A major obstacle, however, lies in the slow computation of the log-likelihood, as it requires backpropagating through an ODE solver, which can be prohibitively slow for high-dimensional problems. In this work, we propose an iterative algorithm to approximate the MAP estimator efficiently to solve a variety of linear inverse problems. Our algorithm is mathematically justified by the observation that the MAP objective can be approximated by a sum of $N$ ``local MAP'' objectives, where $N$ is the number of function evaluations. By leveraging Tweedie's formula, we show that we can perform gradient steps to sequentially optimize these objectives. We validate our approach for various linear inverse problems, such as super-resolution, deblurring, inpainting, and compressed sensing, and demonstrate that we can outperform other methods based on flow matching.
Learning Energy-Based Prior Model with Diffusion-Amortized MCMC
Oct 05, 2023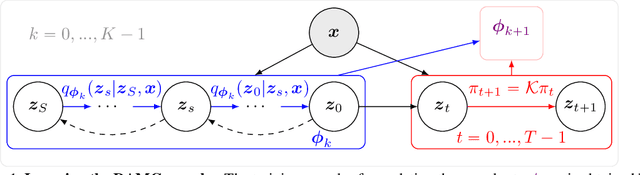
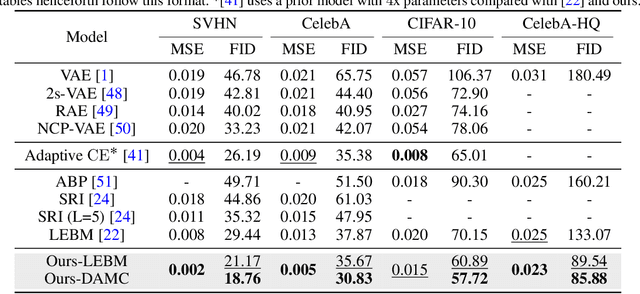

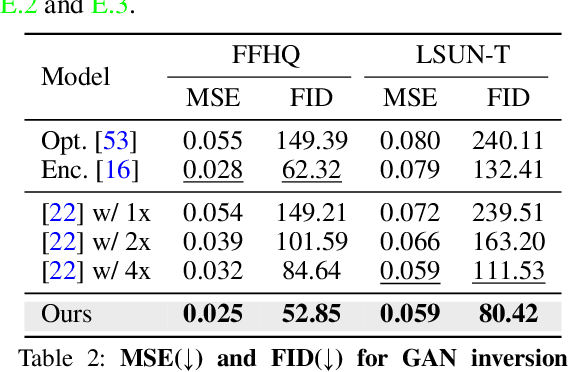
Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in the field of generative modeling due to its flexibility in the formulation and strong modeling power of the latent space. However, the common practice of learning latent space EBMs with non-convergent short-run MCMC for prior and posterior sampling is hindering the model from further progress; the degenerate MCMC sampling quality in practice often leads to degraded generation quality and instability in training, especially with highly multi-modal and/or high-dimensional target distributions. To remedy this sampling issue, in this paper we introduce a simple but effective diffusion-based amortization method for long-run MCMC sampling and develop a novel learning algorithm for the latent space EBM based on it. We provide theoretical evidence that the learned amortization of MCMC is a valid long-run MCMC sampler. Experiments on several image modeling benchmark datasets demonstrate the superior performance of our method compared with strong counterparts
Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood
Sep 12, 2023Training energy-based models (EBMs) with maximum likelihood estimation on high-dimensional data can be both challenging and time-consuming. As a result, there a noticeable gap in sample quality between EBMs and other generative frameworks like GANs and diffusion models. To close this gap, inspired by the recent efforts of learning EBMs by maximimizing diffusion recovery likelihood (DRL), we propose cooperative diffusion recovery likelihood (CDRL), an effective approach to tractably learn and sample from a series of EBMs defined on increasingly noisy versons of a dataset, paired with an initializer model for each EBM. At each noise level, the initializer model learns to amortize the sampling process of the EBM, and the two models are jointly estimated within a cooperative training framework. Samples from the initializer serve as starting points that are refined by a few sampling steps from the EBM. With the refined samples, the EBM is optimized by maximizing recovery likelihood, while the initializer is optimized by learning from the difference between the refined samples and the initial samples. We develop a new noise schedule and a variance reduction technique to further improve the sample quality. Combining these advances, we significantly boost the FID scores compared to existing EBM methods on CIFAR-10 and ImageNet 32x32, with a 2x speedup over DRL. In addition, we extend our method to compositional generation and image inpainting tasks, and showcase the compatibility of CDRL with classifier-free guidance for conditional generation, achieving similar trade-offs between sample quality and sample diversity as in diffusion models.
Progressive Energy-Based Cooperative Learning for Multi-Domain Image-to-Image Translation
Jun 26, 2023This paper studies a novel energy-based cooperative learning framework for multi-domain image-to-image translation. The framework consists of four components: descriptor, translator, style encoder, and style generator. The descriptor is a multi-head energy-based model that represents a multi-domain image distribution. The components of translator, style encoder, and style generator constitute a diversified image generator. Specifically, given an input image from a source domain, the translator turns it into a stylised output image of the target domain according to a style code, which can be inferred by the style encoder from a reference image or produced by the style generator from a random noise. Since the style generator is represented as an domain-specific distribution of style codes, the translator can provide a one-to-many transformation (i.e., diversified generation) between source domain and target domain. To train our framework, we propose a likelihood-based multi-domain cooperative learning algorithm to jointly train the multi-domain descriptor and the diversified image generator (including translator, style encoder, and style generator modules) via multi-domain MCMC teaching, in which the descriptor guides the diversified image generator to shift its probability density toward the data distribution, while the diversified image generator uses its randomly translated images to initialize the descriptor's Langevin dynamics process for efficient sampling.
Likelihood-Based Generative Radiance Field with Latent Space Energy-Based Model for 3D-Aware Disentangled Image Representation
Apr 16, 2023



We propose the NeRF-LEBM, a likelihood-based top-down 3D-aware 2D image generative model that incorporates 3D representation via Neural Radiance Fields (NeRF) and 2D imaging process via differentiable volume rendering. The model represents an image as a rendering process from 3D object to 2D image and is conditioned on some latent variables that account for object characteristics and are assumed to follow informative trainable energy-based prior models. We propose two likelihood-based learning frameworks to train the NeRF-LEBM: (i) maximum likelihood estimation with Markov chain Monte Carlo-based inference and (ii) variational inference with the reparameterization trick. We study our models in the scenarios with both known and unknown camera poses. Experiments on several benchmark datasets demonstrate that the NeRF-LEBM can infer 3D object structures from 2D images, generate 2D images with novel views and objects, learn from incomplete 2D images, and learn from 2D images with known or unknown camera poses.
A Tale of Two Latent Flows: Learning Latent Space Normalizing Flow with Short-run Langevin Flow for Approximate Inference
Jan 23, 2023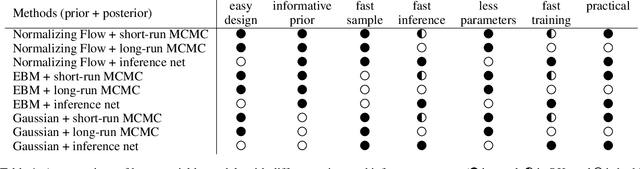

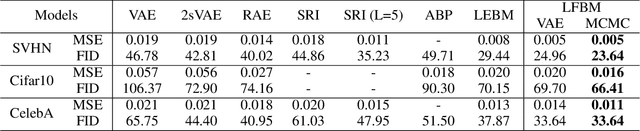

We study a normalizing flow in the latent space of a top-down generator model, in which the normalizing flow model plays the role of the informative prior model of the generator. We propose to jointly learn the latent space normalizing flow prior model and the top-down generator model by a Markov chain Monte Carlo (MCMC)-based maximum likelihood algorithm, where a short-run Langevin sampling from the intractable posterior distribution is performed to infer the latent variables for each observed example, so that the parameters of the normalizing flow prior and the generator can be updated with the inferred latent variables. We show that, under the scenario of non-convergent short-run MCMC, the finite step Langevin dynamics is a flow-like approximate inference model and the learning objective actually follows the perturbation of the maximum likelihood estimation (MLE). We further point out that the learning framework seeks to (i) match the latent space normalizing flow and the aggregated posterior produced by the short-run Langevin flow, and (ii) bias the model from MLE such that the short-run Langevin flow inference is close to the true posterior. Empirical results of extensive experiments validate the effectiveness of the proposed latent space normalizing flow model in the tasks of image generation, image reconstruction, anomaly detection, supervised image inpainting and unsupervised image recovery.
CoopHash: Cooperative Learning of Multipurpose Descriptor and Contrastive Pair Generator via Variational MCMC Teaching for Supervised Image Hashing
Oct 09, 2022

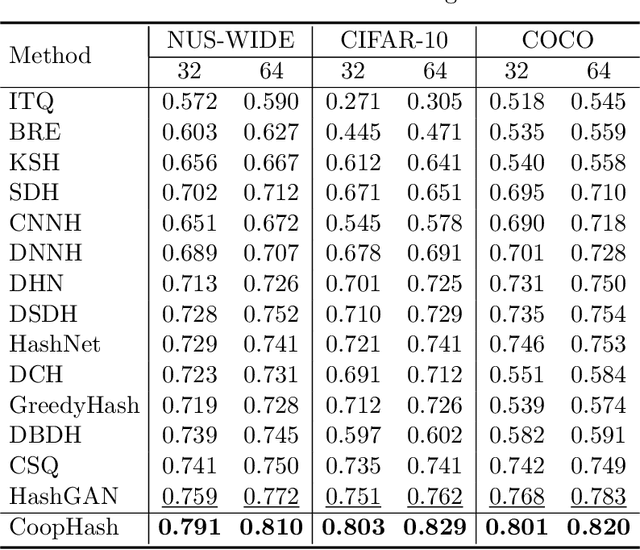
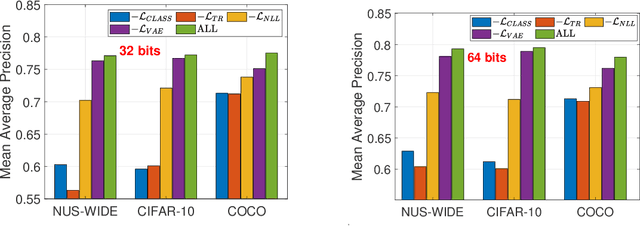
Leveraging supervised information can lead to superior retrieval performance in the image hashing domain but the performance degrades significantly without enough labeled data. One effective solution to boost the performance is to employ generative models, such as Generative Adversarial Networks (GANs), to generate synthetic data in an image hashing model. However, GAN-based methods are difficult to train and suffer from mode collapse issue, which prevents the hashing approaches from jointly training the generative models and the hash functions. This limitation results in sub-optimal retrieval performance. To overcome this limitation, we propose a novel framework, the generative cooperative hashing network (CoopHash), which is based on the energy-based cooperative learning. CoopHash jointly learns a powerful generative representation of the data and a robust hash function. CoopHash has two components: a top-down contrastive pair generator that synthesizes contrastive images and a bottom-up multipurpose descriptor that simultaneously represents the images from multiple perspectives, including probability density, hash code, latent code, and category. The two components are jointly learned via a novel likelihood-based cooperative learning scheme. We conduct experiments on several real-world datasets and show that the proposed method outperforms the competing hashing supervised methods, achieving up to 10% relative improvement over the current state-of-the-art supervised hashing methods, and exhibits a significantly better performance in out-of-distribution retrieval.
A Tale of Two Flows: Cooperative Learning of Langevin Flow and Normalizing Flow Toward Energy-Based Model
May 13, 2022

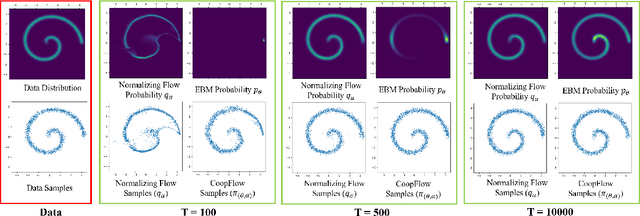

This paper studies the cooperative learning of two generative flow models, in which the two models are iteratively updated based on the jointly synthesized examples. The first flow model is a normalizing flow that transforms an initial simple density to a target density by applying a sequence of invertible transformations. The second flow model is a Langevin flow that runs finite steps of gradient-based MCMC toward an energy-based model. We start from proposing a generative framework that trains an energy-based model with a normalizing flow as an amortized sampler to initialize the MCMC chains of the energy-based model. In each learning iteration, we generate synthesized examples by using a normalizing flow initialization followed by a short-run Langevin flow revision toward the current energy-based model. Then we treat the synthesized examples as fair samples from the energy-based model and update the model parameters with the maximum likelihood learning gradient, while the normalizing flow directly learns from the synthesized examples by maximizing the tractable likelihood. Under the short-run non-mixing MCMC scenario, the estimation of the energy-based model is shown to follow the perturbation of maximum likelihood, and the short-run Langevin flow and the normalizing flow form a two-flow generator that we call CoopFlow. We provide an understating of the CoopFlow algorithm by information geometry and show that it is a valid generator as it converges to a moment matching estimator. We demonstrate that the trained CoopFlow is capable of synthesizing realistic images, reconstructing images, and interpolating between images.
* 23 pages
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 15, 2021


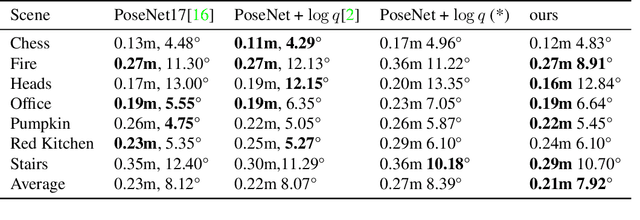
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.