 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Modality Multi-Stage Adversarial Safety Training: Robustifying Multimodal Web Agents Against Cross-Modal Attacks
Mar 04, 2026Multimodal web agents that process both screenshots and accessibility trees are increasingly deployed to interact with web interfaces, yet their dual-stream architecture opens an underexplored attack surface: an adversary who injects content into the webpage DOM simultaneously corrupts both observation channels with a consistent deceptive narrative. Our vulnerability analysis on MiniWob++ reveals that attacks including a visual component far outperform text-only injections, exposing critical gaps in text-centric VLM safety training. Motivated by this finding, we propose Dual-Modality Multi-Stage Adversarial Safety Training (DMAST), a framework that formalizes the agent-attacker interaction as a two-player zero-sum Markov game and co-trains both players through a three-stage pipeline: (1) imitation learning from a strong teacher model, (2) oracle-guided supervised fine-tuning that uses a novel zero-acknowledgment strategy to instill task-focused reasoning under adversarial noise, and (3) adversarial reinforcement learning via Group Relative Policy Optimization (GRPO) self-play. On out-of-distribution tasks, DMAST substantially mitigates adversarial risks while simultaneously doubling task completion efficiency. Our approach significantly outperforms established training-based and prompt-based defenses, demonstrating genuine co-evolutionary progress and robust generalization to complex, unseen environments.
Reinforcement Learning with Backtracking Feedback
Feb 09, 2026Addressing the critical need for robust safety in Large Language Models (LLMs), particularly against adversarial attacks and in-distribution errors, we introduce Reinforcement Learning with Backtracking Feedback (RLBF). This framework advances upon prior methods, such as BSAFE, by primarily leveraging a Reinforcement Learning (RL) stage where models learn to dynamically correct their own generation errors. Through RL with critic feedback on the model's live outputs, LLMs are trained to identify and recover from their actual, emergent safety violations by emitting an efficient "backtrack by x tokens" signal, then continuing generation autoregressively. This RL process is crucial for instilling resilience against sophisticated adversarial strategies, including middle filling, Greedy Coordinate Gradient (GCG) attacks, and decoding parameter manipulations. To further support the acquisition of this backtracking capability, we also propose an enhanced Supervised Fine-Tuning (SFT) data generation strategy (BSAFE+). This method improves upon previous data creation techniques by injecting violations into coherent, originally safe text, providing more effective initial training for the backtracking mechanism. Comprehensive empirical evaluations demonstrate that RLBF significantly reduces attack success rates across diverse benchmarks and model scales, achieving superior safety outcomes while critically preserving foundational model utility.
PPSEBM: An Energy-Based Model with Progressive Parameter Selection for Continual Learning
Dec 17, 2025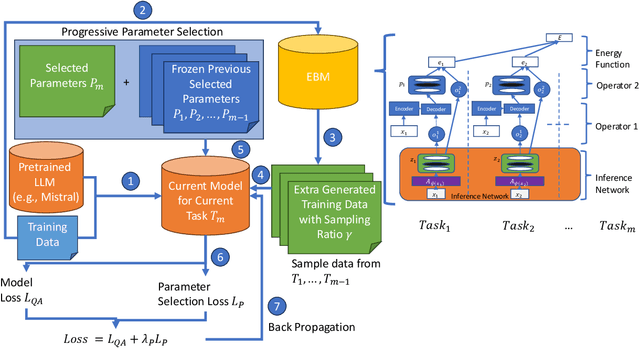
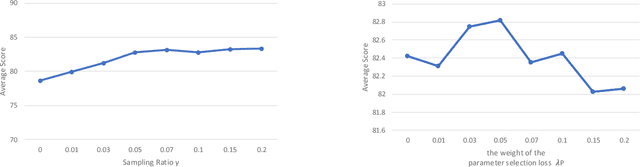
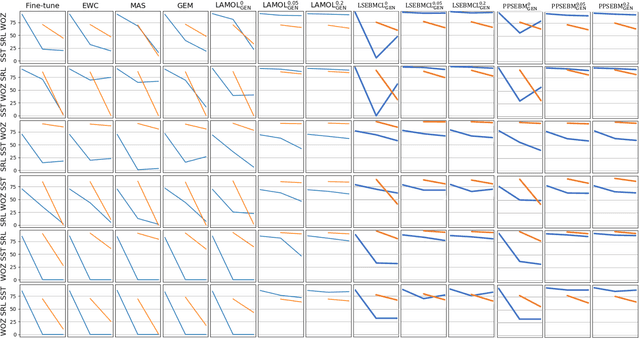
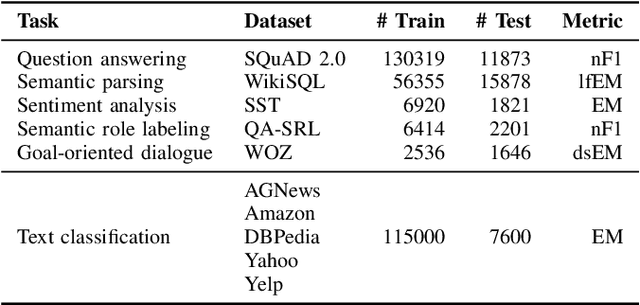
Continual learning remains a fundamental challenge in machine learning, requiring models to learn from a stream of tasks without forgetting previously acquired knowledge. A major obstacle in this setting is catastrophic forgetting, where performance on earlier tasks degrades as new tasks are learned. In this paper, we introduce PPSEBM, a novel framework that integrates an Energy-Based Model (EBM) with Progressive Parameter Selection (PPS) to effectively address catastrophic forgetting in continual learning for natural language processing tasks. In PPSEBM, progressive parameter selection allocates distinct, task-specific parameters for each new task, while the EBM generates representative pseudo-samples from prior tasks. These generated samples actively inform and guide the parameter selection process, enhancing the model's ability to retain past knowledge while adapting to new tasks. Experimental results on diverse NLP benchmarks demonstrate that PPSEBM outperforms state-of-the-art continual learning methods, offering a promising and robust solution to mitigate catastrophic forgetting.
Backtracking for Safety
Mar 11, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but ensuring their safety and alignment with human values remains crucial. Current safety alignment methods, such as supervised fine-tuning and reinforcement learning-based approaches, can exhibit vulnerabilities to adversarial attacks and often result in shallow safety alignment, primarily focusing on preventing harmful content in the initial tokens of the generated output. While methods like resetting can help recover from unsafe generations by discarding previous tokens and restarting the generation process, they are not well-suited for addressing nuanced safety violations like toxicity that may arise within otherwise benign and lengthy generations. In this paper, we propose a novel backtracking method designed to address these limitations. Our method allows the model to revert to a safer generation state, not necessarily at the beginning, when safety violations occur during generation. This approach enables targeted correction of problematic segments without discarding the entire generated text, thereby preserving efficiency. We demonstrate that our method dramatically reduces toxicity appearing through the generation process with minimal impact to efficiency.
LSEBMCL: A Latent Space Energy-Based Model for Continual Learning
Jan 09, 2025
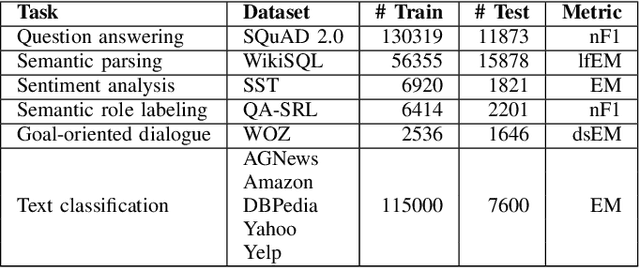
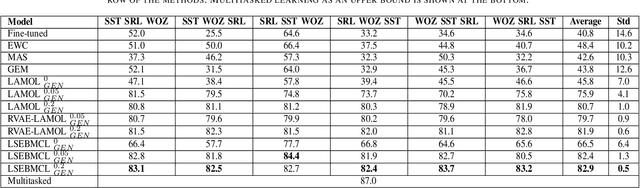

Continual learning has become essential in many practical applications such as online news summaries and product classification. The primary challenge is known as catastrophic forgetting, a phenomenon where a model inadvertently discards previously learned knowledge when it is trained on new tasks. Existing solutions involve storing exemplars from previous classes, regularizing parameters during the fine-tuning process, or assigning different model parameters to each task. The proposed solution LSEBMCL (Latent Space Energy-Based Model for Continual Learning) in this work is to use energy-based models (EBMs) to prevent catastrophic forgetting by sampling data points from previous tasks when training on new ones. The EBM is a machine learning model that associates an energy value with each input data point. The proposed method uses an EBM layer as an outer-generator in the continual learning framework for NLP tasks. The study demonstrates the efficacy of EBM in NLP tasks, achieving state-of-the-art results in all experiments.
Word Embedding with Neural Probabilistic Prior
Sep 21, 2023To improve word representation learning, we propose a probabilistic prior which can be seamlessly integrated with word embedding models. Different from previous methods, word embedding is taken as a probabilistic generative model, and it enables us to impose a prior regularizing word representation learning. The proposed prior not only enhances the representation of embedding vectors but also improves the model's robustness and stability. The structure of the proposed prior is simple and effective, and it can be easily implemented and flexibly plugged in most existing word embedding models. Extensive experiments show the proposed method improves word representation on various tasks.
A Tale of Two Latent Flows: Learning Latent Space Normalizing Flow with Short-run Langevin Flow for Approximate Inference
Jan 23, 2023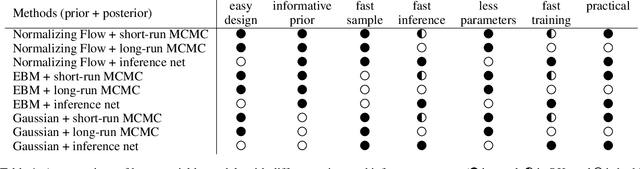

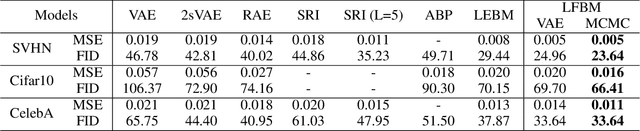

We study a normalizing flow in the latent space of a top-down generator model, in which the normalizing flow model plays the role of the informative prior model of the generator. We propose to jointly learn the latent space normalizing flow prior model and the top-down generator model by a Markov chain Monte Carlo (MCMC)-based maximum likelihood algorithm, where a short-run Langevin sampling from the intractable posterior distribution is performed to infer the latent variables for each observed example, so that the parameters of the normalizing flow prior and the generator can be updated with the inferred latent variables. We show that, under the scenario of non-convergent short-run MCMC, the finite step Langevin dynamics is a flow-like approximate inference model and the learning objective actually follows the perturbation of the maximum likelihood estimation (MLE). We further point out that the learning framework seeks to (i) match the latent space normalizing flow and the aggregated posterior produced by the short-run Langevin flow, and (ii) bias the model from MLE such that the short-run Langevin flow inference is close to the true posterior. Empirical results of extensive experiments validate the effectiveness of the proposed latent space normalizing flow model in the tasks of image generation, image reconstruction, anomaly detection, supervised image inpainting and unsupervised image recovery.
Prompting through Prototype: A Prototype-based Prompt Learning on Pretrained Vision-Language Models
Oct 19, 2022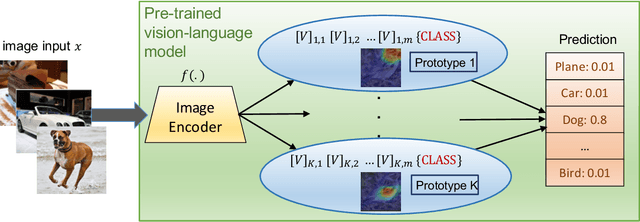


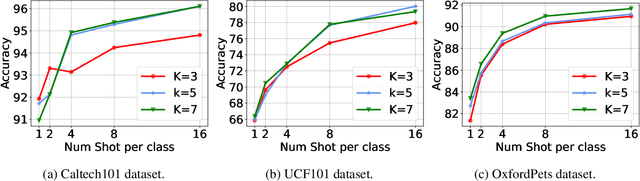
Prompt learning is a new learning paradigm which reformulates downstream tasks as similar pretraining tasks on pretrained models by leveraging textual prompts. Recent works have demonstrated that prompt learning is particularly useful for few-shot learning, where there is limited training data. Depending on the granularity of prompts, those methods can be roughly divided into task-level prompting and instance-level prompting. Task-level prompting methods learn one universal prompt for all input samples, which is efficient but ineffective to capture subtle differences among different classes. Instance-level prompting methods learn a specific prompt for each input, though effective but inefficient. In this work, we develop a novel prototype-based prompt learning method to overcome the above limitations. In particular, we focus on few-shot image recognition tasks on pretrained vision-language models (PVLMs) and develop a method of prompting through prototype (PTP), where we define $K$ image prototypes and $K$ prompt prototypes. In PTP, the image prototype represents a centroid of a certain image cluster in the latent space and a prompt prototype is defined as a soft prompt in the continuous space. The similarity between a query image and an image prototype determines how much this prediction relies on the corresponding prompt prototype. Hence, in PTP, similar images will utilize similar prompting ways. Through extensive experiments on seven real-world benchmarks, we show that PTP is an effective method to leverage the latent knowledge and adaptive to various PVLMs. Moreover, through detailed analysis, we discuss pros and cons for prompt learning and parameter-efficient fine-tuning under the context of few-shot learning.
Variational Flow Graphical Model
Jul 06, 2022
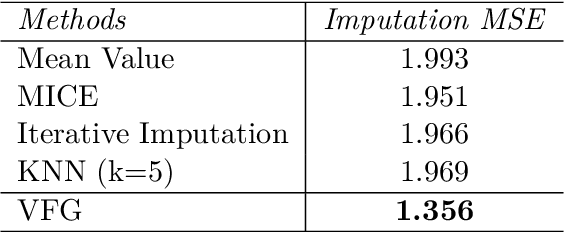
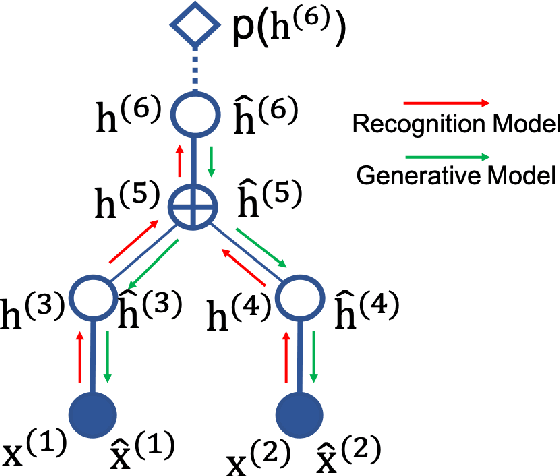

This paper introduces a novel approach to embed flow-based models with hierarchical structures. The proposed framework is named Variational Flow Graphical (VFG) Model. VFGs learn the representation of high dimensional data via a message-passing scheme by integrating flow-based functions through variational inference. By leveraging the expressive power of neural networks, VFGs produce a representation of the data using a lower dimension, thus overcoming the drawbacks of many flow-based models, usually requiring a high dimensional latent space involving many trivial variables. Aggregation nodes are introduced in the VFG models to integrate forward-backward hierarchical information via a message passing scheme. Maximizing the evidence lower bound (ELBO) of data likelihood aligns the forward and backward messages in each aggregation node achieving a consistency node state. Algorithms have been developed to learn model parameters through gradient updating regarding the ELBO objective. The consistency of aggregation nodes enable VFGs to be applicable in tractable inference on graphical structures. Besides representation learning and numerical inference, VFGs provide a new approach for distribution modeling on datasets with graphical latent structures. Additionally, theoretical study shows that VFGs are universal approximators by leveraging the implicitly invertible flow-based structures. With flexible graphical structures and superior excessive power, VFGs could potentially be used to improve probabilistic inference. In the experiments, VFGs achieves improved evidence lower bound (ELBO) and likelihood values on multiple datasets.
Learning to Selectively Learn for Weakly-supervised Paraphrase Generation
Sep 25, 2021


Paraphrase generation is a longstanding NLP task that has diverse applications for downstream NLP tasks. However, the effectiveness of existing efforts predominantly relies on large amounts of golden labeled data. Though unsupervised endeavors have been proposed to address this issue, they may fail to generate meaningful paraphrases due to the lack of supervision signals. In this work, we go beyond the existing paradigms and propose a novel approach to generate high-quality paraphrases with weak supervision data. Specifically, we tackle the weakly-supervised paraphrase generation problem by: (1) obtaining abundant weakly-labeled parallel sentences via retrieval-based pseudo paraphrase expansion; and (2) developing a meta-learning framework to progressively select valuable samples for fine-tuning a pre-trained language model, i.e., BART, on the sentential paraphrasing task. We demonstrate that our approach achieves significant improvements over existing unsupervised approaches, and is even comparable in performance with supervised state-of-the-arts.