 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Active Multi-Step Reinforcement Learning
Paper and Code
Nov 27, 2019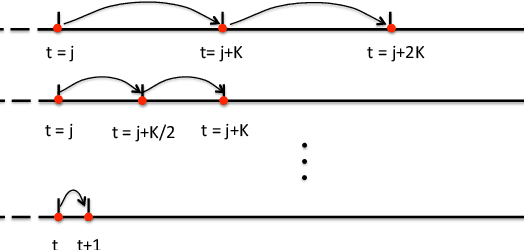


Reinforcement learning has attracted great attention recently, especially policy gradient algorithms, which have been demonstrated on challenging decision making and control tasks. In this paper, we propose an active multi-step TD algorithm with adaptive stepsizes to learn actor and critic. Specifically, our model consists of two components: active stepsize learning and adaptive multi-step TD algorithm. Firstly, we divide the time horizon into chunks and actively select state and action inside each chunk. Then given the selected samples, we propose the adaptive multi-step TD, which generalizes TD($\lambda$), but adaptively switch on/off the backups from future returns of different steps. Particularly, the adaptive multi-step TD introduces a context-aware mechanism, here a binary classifier, which decides whether or not to turn on its future backups based on the context changes. Thus, our model is kind of combination of active learning and multi-step TD algorithm, which has the capacity for learning off-policy without the need of importance sampling. We evaluate our approach on both discrete and continuous space tasks in an off-policy setting respectively, and demonstrate competitive results compared to other reinforcement learning baselines.