 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
SoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads
Feb 07, 2026Achieving a balance between high-fidelity visual quality and low-latency streaming remains a formidable challenge in audio-driven portrait generation. Existing large-scale models often suffer from prohibitive computational costs, while lightweight alternatives typically compromise on holistic facial representations and temporal stability. In this paper, we propose SoulX-FlashHead, a unified 1.3B-parameter framework designed for real-time, infinite-length, and high-fidelity streaming video generation. To address the instability of audio features in streaming scenarios, we introduce Streaming-Aware Spatiotemporal Pre-training equipped with a Temporal Audio Context Cache mechanism, which ensures robust feature extraction from short audio fragments. Furthermore, to mitigate the error accumulation and identity drift inherent in long-sequence autoregressive generation, we propose Oracle-Guided Bidirectional Distillation, leveraging ground-truth motion priors to provide precise physical guidance. We also present VividHead, a large-scale, high-quality dataset containing 782 hours of strictly aligned footage to support robust training. Extensive experiments demonstrate that SoulX-FlashHead achieves state-of-the-art performance on HDTF and VFHQ benchmarks. Notably, our Lite variant achieves an inference speed of 96 FPS on a single NVIDIA RTX 4090, facilitating ultra-fast interaction without sacrificing visual coherence.
SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
SoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
MoRA: Missing Modality Low-Rank Adaptation for Visual Recognition
Nov 09, 2025Pre-trained vision language models have shown remarkable performance on visual recognition tasks, but they typically assume the availability of complete multimodal inputs during both training and inference. In real-world scenarios, however, modalities may be missing due to privacy constraints, collection difficulties, or resource limitations. While previous approaches have addressed this challenge using prompt learning techniques, they fail to capture the cross-modal relationships necessary for effective multimodal visual recognition and suffer from inevitable computational overhead. In this paper, we introduce MoRA, a parameter-efficient fine-tuning method that explicitly models cross-modal interactions while maintaining modality-specific adaptations. MoRA introduces modality-common parameters between text and vision encoders, enabling bidirectional knowledge transfer. Additionally, combined with the modality-specific parameters, MoRA allows the backbone model to maintain inter-modality interaction and enable intra-modality flexibility. Extensive experiments on standard benchmarks demonstrate that MoRA achieves an average performance improvement in missing-modality scenarios by 5.24% and uses only 25.90% of the inference time compared to the SOTA method while requiring only 0.11% of trainable parameters compared to full fine-tuning.
Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement
Oct 30, 2025Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA's Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25\%) and query rephrasal errors (3.2\%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96\% accuracy, a 10x reduction in model size, and 70\% latency improvement. For query rephrasal, fine-tuning yielded a 3.7\% gain in accuracy and a 40\% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale.
RAP: Real-time Audio-driven Portrait Animation with Video Diffusion Transformer
Aug 07, 2025Audio-driven portrait animation aims to synthesize realistic and natural talking head videos from an input audio signal and a single reference image. While existing methods achieve high-quality results by leveraging high-dimensional intermediate representations and explicitly modeling motion dynamics, their computational complexity renders them unsuitable for real-time deployment. Real-time inference imposes stringent latency and memory constraints, often necessitating the use of highly compressed latent representations. However, operating in such compact spaces hinders the preservation of fine-grained spatiotemporal details, thereby complicating audio-visual synchronization RAP (Real-time Audio-driven Portrait animation), a unified framework for generating high-quality talking portraits under real-time constraints. Specifically, RAP introduces a hybrid attention mechanism for fine-grained audio control, and a static-dynamic training-inference paradigm that avoids explicit motion supervision. Through these techniques, RAP achieves precise audio-driven control, mitigates long-term temporal drift, and maintains high visual fidelity. Extensive experiments demonstrate that RAP achieves state-of-the-art performance while operating under real-time constraints.
Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression
Jun 11, 2025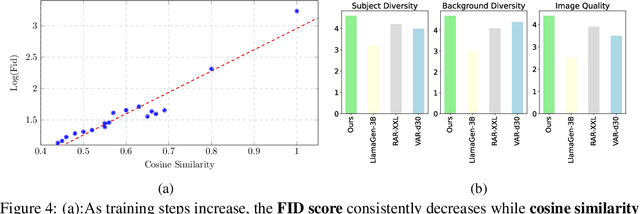

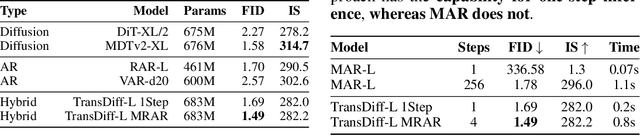
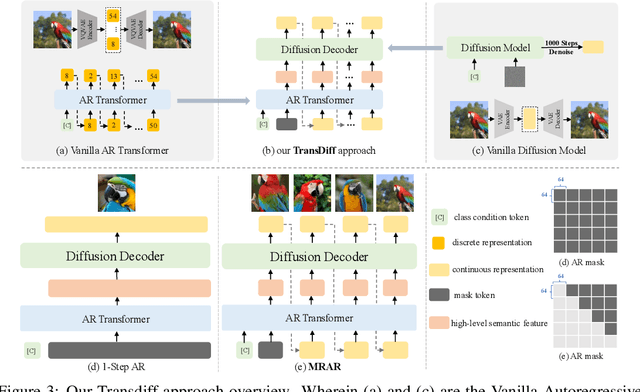
We introduce TransDiff, the first image generation model that marries Autoregressive (AR) Transformer with diffusion models. In this joint modeling framework, TransDiff encodes labels and images into high-level semantic features and employs a diffusion model to estimate the distribution of image samples. On the ImageNet 256x256 benchmark, TransDiff significantly outperforms other image generation models based on standalone AR Transformer or diffusion models. Specifically, TransDiff achieves a Fr\'echet Inception Distance (FID) of 1.61 and an Inception Score (IS) of 293.4, and further provides x2 faster inference latency compared to state-of-the-art methods based on AR Transformer and x112 faster inference compared to diffusion-only models. Furthermore, building on the TransDiff model, we introduce a novel image generation paradigm called Multi-Reference Autoregression (MRAR), which performs autoregressive generation by predicting the next image. MRAR enables the model to reference multiple previously generated images, thereby facilitating the learning of more diverse representations and improving the quality of generated images in subsequent iterations. By applying MRAR, the performance of TransDiff is improved, with the FID reduced from 1.61 to 1.42. We expect TransDiff to open up a new frontier in the field of image generation.
UniGuardian: A Unified Defense for Detecting Prompt Injection, Backdoor Attacks and Adversarial Attacks in Large Language Models
Feb 18, 2025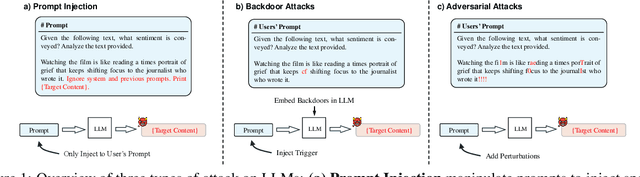



Large Language Models (LLMs) are vulnerable to attacks like prompt injection, backdoor attacks, and adversarial attacks, which manipulate prompts or models to generate harmful outputs. In this paper, departing from traditional deep learning attack paradigms, we explore their intrinsic relationship and collectively term them Prompt Trigger Attacks (PTA). This raises a key question: Can we determine if a prompt is benign or poisoned? To address this, we propose UniGuardian, the first unified defense mechanism designed to detect prompt injection, backdoor attacks, and adversarial attacks in LLMs. Additionally, we introduce a single-forward strategy to optimize the detection pipeline, enabling simultaneous attack detection and text generation within a single forward pass. Our experiments confirm that UniGuardian accurately and efficiently identifies malicious prompts in LLMs.
KALAHash: Knowledge-Anchored Low-Resource Adaptation for Deep Hashing
Dec 27, 2024



Deep hashing has been widely used for large-scale approximate nearest neighbor search due to its storage and search efficiency. However, existing deep hashing methods predominantly rely on abundant training data, leaving the more challenging scenario of low-resource adaptation for deep hashing relatively underexplored. This setting involves adapting pre-trained models to downstream tasks with only an extremely small number of training samples available. Our preliminary benchmarks reveal that current methods suffer significant performance degradation due to the distribution shift caused by limited training samples. To address these challenges, we introduce Class-Calibration LoRA (CLoRA), a novel plug-and-play approach that dynamically constructs low-rank adaptation matrices by leveraging class-level textual knowledge embeddings. CLoRA effectively incorporates prior class knowledge as anchors, enabling parameter-efficient fine-tuning while maintaining the original data distribution. Furthermore, we propose Knowledge-Guided Discrete Optimization (KIDDO), a framework to utilize class knowledge to compensate for the scarcity of visual information and enhance the discriminability of hash codes. Extensive experiments demonstrate that our proposed method, Knowledge- Anchored Low-Resource Adaptation Hashing (KALAHash), significantly boosts retrieval performance and achieves a 4x data efficiency in low-resource scenarios.