 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARV: A Diagnostic Benchmark for Compositional Analogical Reasoning in Multimodal LLMs
Mar 30, 2026Analogical reasoning tests a fundamental aspect of human cognition: mapping the relation from one pair of objects to another. Existing evaluations of this ability in multimodal large language models (MLLMs) overlook the ability to compose rules from multiple sources, a critical component of higher-order intelligence. To close this gap, we introduce CARV (Compositional Analogical Reasoning in Vision), a novel task together with a 5,500-sample dataset as the first diagnostic benchmark. We extend the analogy from a single pair to multiple pairs, which requires MLLMs to extract symbolic rules from each pair and compose new transformations. Evaluation on the state-of-the-art MLLMs reveals a striking performance gap: even Gemini-2.5 Pro achieving only 40.4% accuracy, far below human-level performance of 100%. Diagnostic analysis shows two consistent failure modes: (1) decomposing visual changes into symbolic rules, and (2) maintaining robustness under diverse or complex settings, highlighting the limitations of current MLLMs on this task.
Understanding and Rectifying Safety Perception Distortion in VLMs
Feb 18, 2025



Recent studies reveal that vision-language models (VLMs) become more susceptible to harmful requests and jailbreak attacks after integrating the vision modality, exhibiting greater vulnerability than their text-only LLM backbones. To uncover the root cause of this phenomenon, we conduct an in-depth analysis and identify a key issue: multimodal inputs introduce an modality-induced activation shift toward a "safer" direction compared to their text-only counterparts, leading VLMs to systematically overestimate the safety of harmful inputs. We refer to this issue as safety perception distortion. To mitigate such distortion, we propose Activation Shift Disentanglement and Calibration (ShiftDC), a training-free method that decomposes and calibrates the modality-induced activation shift to reduce the impact of modality on safety. By isolating and removing the safety-relevant component, ShiftDC restores the inherent safety alignment of the LLM backbone while preserving the vision-language capabilities of VLMs. Empirical results demonstrate that ShiftDC significantly enhances alignment performance on safety benchmarks without impairing model utility.
Reconstruct before Query: Continual Missing Modality Learning with Decomposed Prompt Collaboration
Mar 17, 2024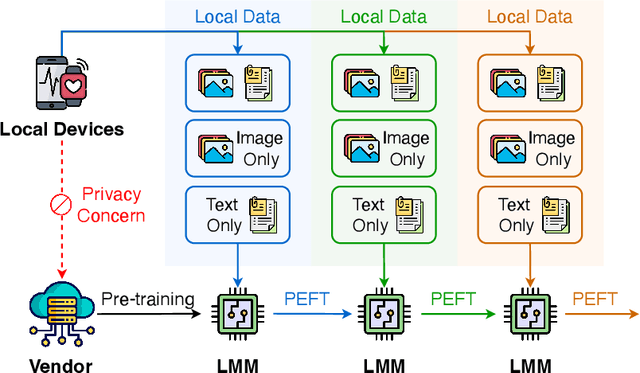



Pre-trained large multi-modal models (LMMs) exploit fine-tuning to adapt diverse user applications. Nevertheless, fine-tuning may face challenges due to deactivated sensors (e.g., cameras turned off for privacy or technical issues), yielding modality-incomplete data and leading to inconsistency in training data and the data for inference. Additionally, continuous training leads to catastrophic forgetting, diluting the knowledge in pre-trained LMMs. To overcome these challenges, we introduce a novel task, Continual Missing Modality Learning (CMML), to investigate how models can generalize when data of certain modalities is missing during continual fine-tuning. Our preliminary benchmarks reveal that existing methods suffer from a significant performance drop in CMML, even with the aid of advanced continual learning techniques. Therefore, we devise a framework termed Reconstruct before Query (RebQ). It decomposes prompts into modality-specific ones and breaks them into components stored in pools accessible via a key-query mechanism, which facilitates ParameterEfficient Fine-Tuning and enhances knowledge transferability for subsequent tasks. Meanwhile, our RebQ leverages extensive multi-modal knowledge from pre-trained LMMs to reconstruct the data of missing modality. Comprehensive experiments demonstrate that RebQ effectively reconstructs the missing modality information and retains pre-trained knowledge. Specifically, compared with the baseline, RebQ improves average precision from 20.00 to 50.92 and decreases average forgetting from 75.95 to 8.56. Code and datasets are available on https://github.com/Tree-Shu-Zhao/RebQ.pytorch
TokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Oct 03, 2022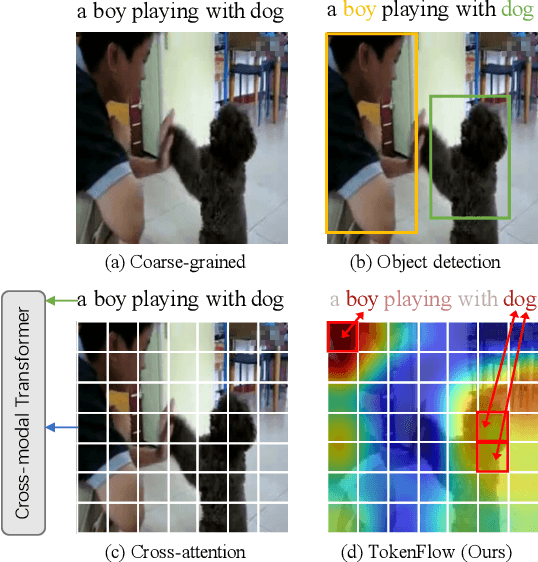
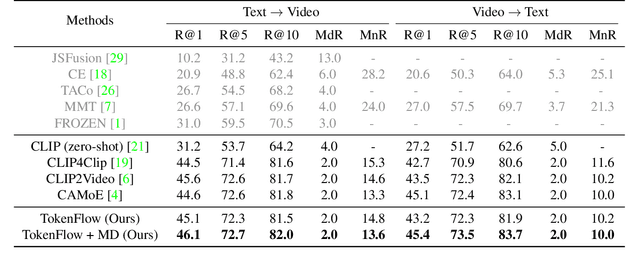
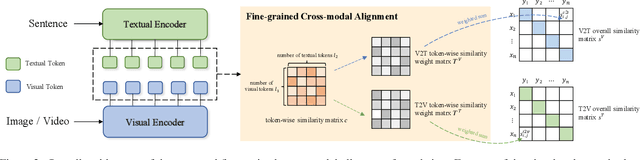
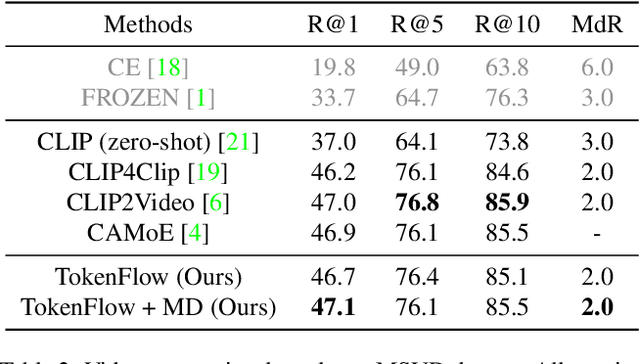
Most existing methods in vision-language retrieval match two modalities by either comparing their global feature vectors which misses sufficient information and lacks interpretability, detecting objects in images or videos and aligning the text with fine-grained features which relies on complicated model designs, or modeling fine-grained interaction via cross-attention upon visual and textual tokens which suffers from inferior efficiency. To address these limitations, some recent works simply aggregate the token-wise similarities to achieve fine-grained alignment, but they lack intuitive explanations as well as neglect the relationships between token-level features and global representations with high-level semantics. In this work, we rethink fine-grained cross-modal alignment and devise a new model-agnostic formulation for it. We additionally demystify the recent popular works and subsume them into our scheme. Furthermore, inspired by optimal transport theory, we introduce TokenFlow, an instantiation of the proposed scheme. By modifying only the similarity function, the performance of our method is comparable to the SoTA algorithms with heavy model designs on major video-text retrieval benchmarks. The visualization further indicates that TokenFlow successfully leverages the fine-grained information and achieves better interpretability.
Efficient Meta-Learning for Continual Learning with Taylor Expansion Approximation
Oct 03, 2022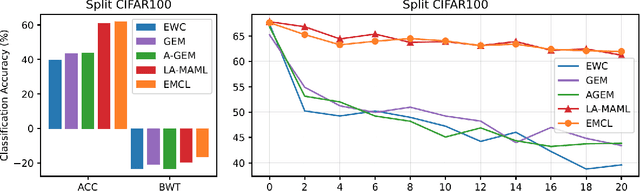
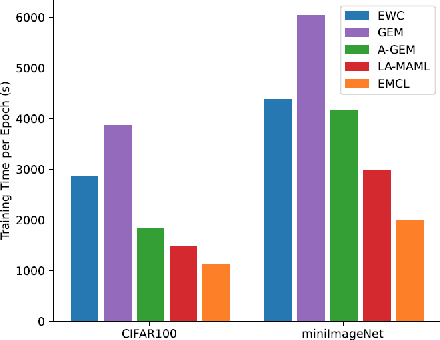
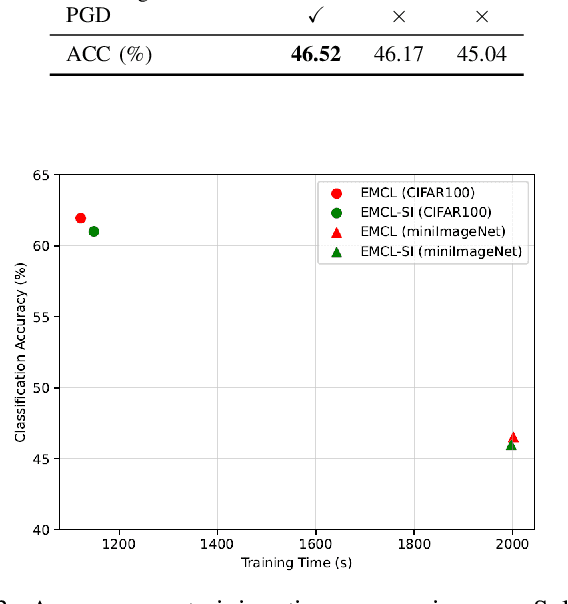

Continual learning aims to alleviate catastrophic forgetting when handling consecutive tasks under non-stationary distributions. Gradient-based meta-learning algorithms have shown the capability to implicitly solve the transfer-interference trade-off problem between different examples. However, they still suffer from the catastrophic forgetting problem in the setting of continual learning, since the past data of previous tasks are no longer available. In this work, we propose a novel efficient meta-learning algorithm for solving the online continual learning problem, where the regularization terms and learning rates are adapted to the Taylor approximation of the parameter's importance to mitigate forgetting. The proposed method expresses the gradient of the meta-loss in closed-form and thus avoid computing second-order derivative which is computationally inhibitable. We also use Proximal Gradient Descent to further improve computational efficiency and accuracy. Experiments on diverse benchmarks show that our method achieves better or on-par performance and much higher efficiency compared to the state-of-the-art approaches.