 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Sensitivity of Backdoor Detectors via Class Subspace Orthogonalization
Dec 09, 2025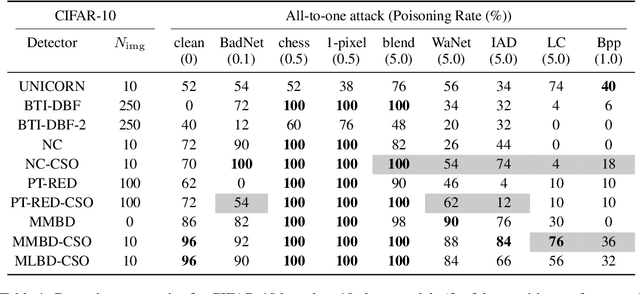



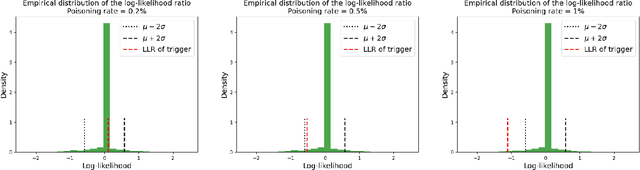
Most post-training backdoor detection methods rely on attacked models exhibiting extreme outlier detection statistics for the target class of an attack, compared to non-target classes. However, these approaches may fail: (1) when some (non-target) classes are easily discriminable from all others, in which case they may naturally achieve extreme detection statistics (e.g., decision confidence); and (2) when the backdoor is subtle, i.e., with its features weak relative to intrinsic class-discriminative features. A key observation is that the backdoor target class has contributions to its detection statistic from both the backdoor trigger and from its intrinsic features, whereas non-target classes only have contributions from their intrinsic features. To achieve more sensitive detectors, we thus propose to suppress intrinsic features while optimizing the detection statistic for a given class. For non-target classes, such suppression will drastically reduce the achievable statistic, whereas for the target class the (significant) contribution from the backdoor trigger remains. In practice, we formulate a constrained optimization problem, leveraging a small set of clean examples from a given class, and optimizing the detection statistic while orthogonalizing with respect to the class's intrinsic features. We dub this plug-and-play approach Class Subspace Orthogonalization (CSO) and assess it against challenging mixed-label and adaptive attacks.
Inverting Trojans in LLMs
Sep 19, 2025While effective backdoor detection and inversion schemes have been developed for AIs used e.g. for images, there are challenges in "porting" these methods to LLMs. First, the LLM input space is discrete, which precludes gradient-based search over this space, central to many backdoor inversion methods. Second, there are ~30,000^k k-tuples to consider, k the token-length of a putative trigger. Third, for LLMs there is the need to blacklist tokens that have strong marginal associations with the putative target response (class) of an attack, as such tokens give false detection signals. However, good blacklists may not exist for some domains. We propose a LLM trigger inversion approach with three key components: i) discrete search, with putative triggers greedily accreted, starting from a select list of singletons; ii) implicit blacklisting, achieved by evaluating the average cosine similarity, in activation space, between a candidate trigger and a small clean set of samples from the putative target class; iii) detection when a candidate trigger elicits high misclassifications, and with unusually high decision confidence. Unlike many recent works, we demonstrate that our approach reliably detects and successfully inverts ground-truth backdoor trigger phrases.
Understanding and Rectifying Safety Perception Distortion in VLMs
Feb 18, 2025



Recent studies reveal that vision-language models (VLMs) become more susceptible to harmful requests and jailbreak attacks after integrating the vision modality, exhibiting greater vulnerability than their text-only LLM backbones. To uncover the root cause of this phenomenon, we conduct an in-depth analysis and identify a key issue: multimodal inputs introduce an modality-induced activation shift toward a "safer" direction compared to their text-only counterparts, leading VLMs to systematically overestimate the safety of harmful inputs. We refer to this issue as safety perception distortion. To mitigate such distortion, we propose Activation Shift Disentanglement and Calibration (ShiftDC), a training-free method that decomposes and calibrates the modality-induced activation shift to reduce the impact of modality on safety. By isolating and removing the safety-relevant component, ShiftDC restores the inherent safety alignment of the LLM backbone while preserving the vision-language capabilities of VLMs. Empirical results demonstrate that ShiftDC significantly enhances alignment performance on safety benchmarks without impairing model utility.
On Trojans in Refined Language Models
Jun 12, 2024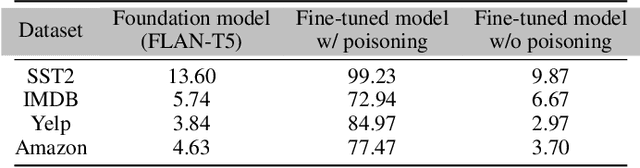
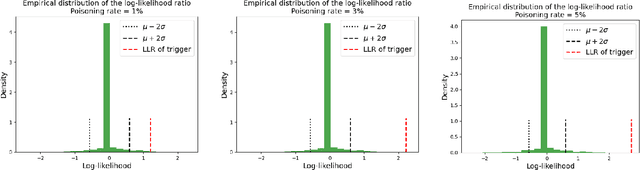
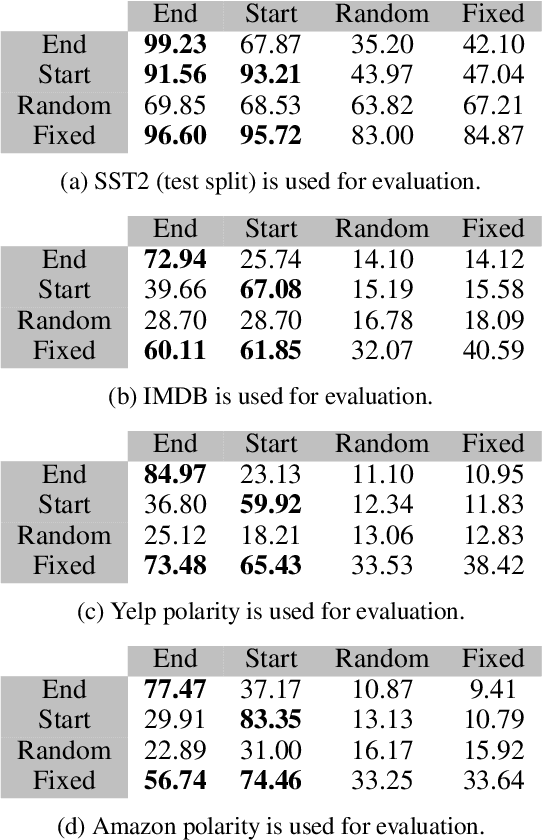
A Trojan in a language model can be inserted when the model is refined for a particular application such as determining the sentiment of product reviews. In this paper, we clarify and empirically explore variations of the data-poisoning threat model. We then empirically assess two simple defenses each for a different defense scenario. Finally, we provide a brief survey of related attacks and defenses.
Universal Post-Training Reverse-Engineering Defense Against Backdoors in Deep Neural Networks
Feb 03, 2024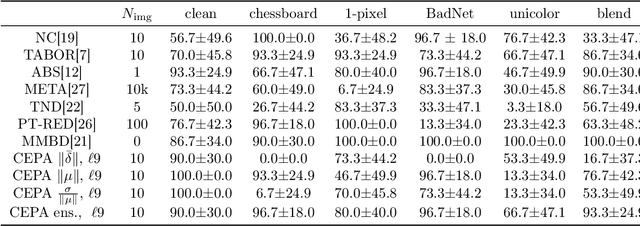
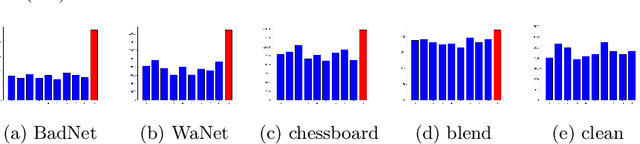
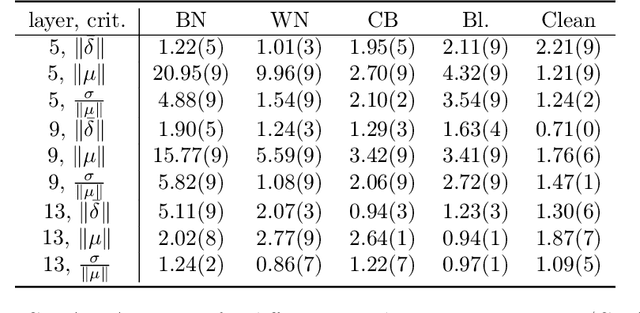
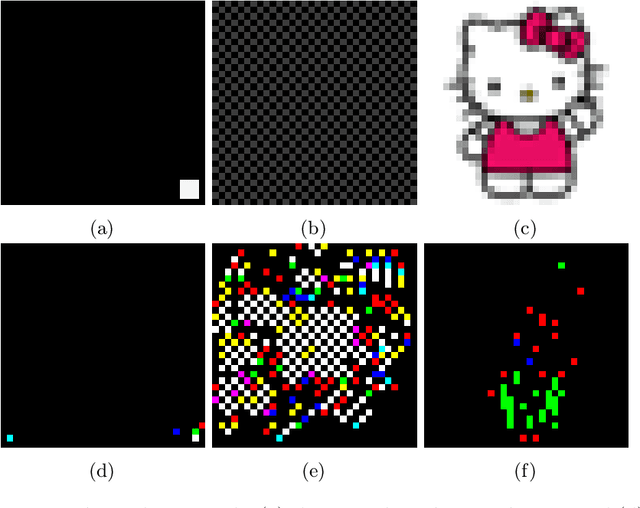
A variety of defenses have been proposed against backdoors attacks on deep neural network (DNN) classifiers. Universal methods seek to reliably detect and/or mitigate backdoors irrespective of the incorporation mechanism used by the attacker, while reverse-engineering methods often explicitly assume one. In this paper, we describe a new detector that: relies on internal feature map of the defended DNN to detect and reverse-engineer the backdoor and identify its target class; can operate post-training (without access to the training dataset); is highly effective for various incorporation mechanisms (i.e., is universal); and which has low computational overhead and so is scalable. Our detection approach is evaluated for different attacks on a benchmark CIFAR-10 image classifier.
GPU Cluster Scheduling for Network-Sensitive Deep Learning
Jan 29, 2024We propose a novel GPU-cluster scheduler for distributed DL (DDL) workloads that enables proximity based consolidation of GPU resources based on the DDL jobs' sensitivities to the anticipated communication-network delays. Our scheduler consists of three major components: (i) a classical delay scheduling algorithm to facilitate job placement and consolidation; (ii) a network-sensitive job preemption strategy; and (iii) an "auto-tuner" mechanism to optimize delay timers for effective delay scheduling. Additionally, to enable a cost-effective methodology for large-scale experiments, we develop a data-driven DDL cluster simulation platform. Employing the simulation platform we compare against several state-of-the-art alternatives on real-world workload traces to demonstrate the benefits of our design. Our scheduler can provide improvement of up to 69% in end-to-end Makespan for training all jobs compared to the prevailing consolidation-based scheduling methods, while reducing the average job completion time by up to 83% and minimizing the communication overheads by up to 98% under congested networking conditions.
Post-Training Overfitting Mitigation in DNN Classifiers
Sep 28, 2023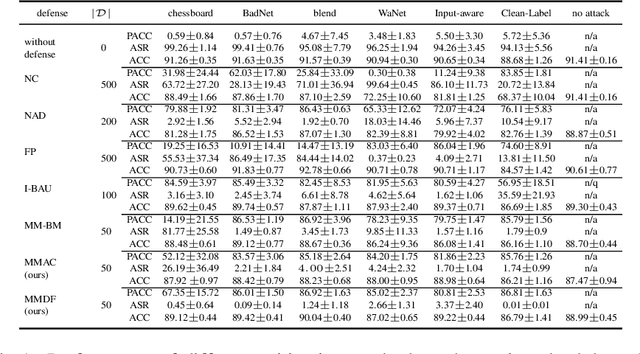
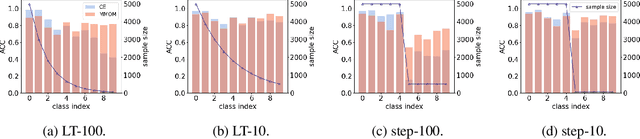
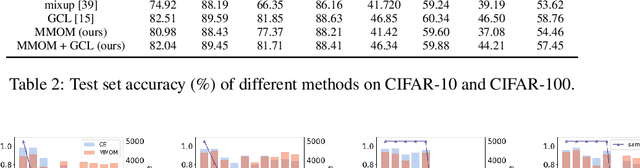
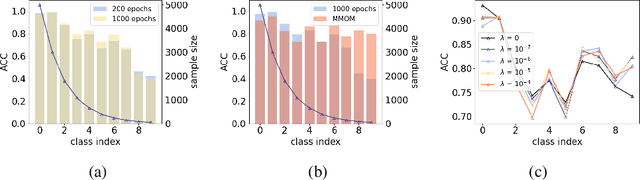
Well-known (non-malicious) sources of overfitting in deep neural net (DNN) classifiers include: i) large class imbalances; ii) insufficient training-set diversity; and iii) over-training. In recent work, it was shown that backdoor data-poisoning also induces overfitting, with unusually large classification margins to the attacker's target class, mediated particularly by (unbounded) ReLU activations that allow large signals to propagate in the DNN. Thus, an effective post-training (with no knowledge of the training set or training process) mitigation approach against backdoors was proposed, leveraging a small clean dataset, based on bounding neural activations. Improving upon that work, we threshold activations specifically to limit maximum margins (MMs), which yields performance gains in backdoor mitigation. We also provide some analytical support for this mitigation approach. Most importantly, we show that post-training MM-based regularization substantially mitigates non-malicious overfitting due to class imbalances and overtraining. Thus, unlike adversarial training, which provides some resilience against attacks but which harms clean (attack-free) generalization, we demonstrate an approach originating from adversarial learning that helps clean generalization accuracy. Experiments on CIFAR-10 and CIFAR-100, in comparison with peer methods, demonstrate strong performance of our methods.
Temporal-Distributed Backdoor Attack Against Video Based Action Recognition
Sep 01, 2023



Deep neural networks (DNNs) have achieved tremendous success in various applications including video action recognition, yet remain vulnerable to backdoor attacks (Trojans). The backdoor-compromised model will mis-classify to the target class chosen by the attacker when a test instance (from a non-target class) is embedded with a specific trigger, while maintaining high accuracy on attack-free instances. Although there are extensive studies on backdoor attacks against image data, the susceptibility of video-based systems under backdoor attacks remains largely unexplored. Current studies are direct extensions of approaches proposed for image data, e.g., the triggers are independently embedded within the frames, which tend to be detectable by existing defenses. In this paper, we introduce a simple yet effective backdoor attack against video data. Our proposed attack, adding perturbations in a transformed domain, plants an imperceptible, temporally distributed trigger across the video frames, and is shown to be resilient to existing defensive strategies. The effectiveness of the proposed attack is demonstrated by extensive experiments with various well-known models on two video recognition benchmarks, UCF101 and HMDB51, and a sign language recognition benchmark, Greek Sign Language (GSL) dataset. We delve into the impact of several influential factors on our proposed attack and identify an intriguing effect termed "collateral damage" through extensive studies.
Backdoor Mitigation by Correcting the Distribution of Neural Activations
Aug 18, 2023



Backdoor (Trojan) attacks are an important type of adversarial exploit against deep neural networks (DNNs), wherein a test instance is (mis)classified to the attacker's target class whenever the attacker's backdoor trigger is present. In this paper, we reveal and analyze an important property of backdoor attacks: a successful attack causes an alteration in the distribution of internal layer activations for backdoor-trigger instances, compared to that for clean instances. Even more importantly, we find that instances with the backdoor trigger will be correctly classified to their original source classes if this distribution alteration is corrected. Based on our observations, we propose an efficient and effective method that achieves post-training backdoor mitigation by correcting the distribution alteration using reverse-engineered triggers. Notably, our method does not change any trainable parameters of the DNN, but achieves generally better mitigation performance than existing methods that do require intensive DNN parameter tuning. It also efficiently detects test instances with the trigger, which may help to catch adversarial entities in the act of exploiting the backdoor.
Improved Activation Clipping for Universal Backdoor Mitigation and Test-Time Detection
Aug 08, 2023



Deep neural networks are vulnerable to backdoor attacks (Trojans), where an attacker poisons the training set with backdoor triggers so that the neural network learns to classify test-time triggers to the attacker's designated target class. Recent work shows that backdoor poisoning induces over-fitting (abnormally large activations) in the attacked model, which motivates a general, post-training clipping method for backdoor mitigation, i.e., with bounds on internal-layer activations learned using a small set of clean samples. We devise a new such approach, choosing the activation bounds to explicitly limit classification margins. This method gives superior performance against peer methods for CIFAR-10 image classification. We also show that this method has strong robustness against adaptive attacks, X2X attacks, and on different datasets. Finally, we demonstrate a method extension for test-time detection and correction based on the output differences between the original and activation-bounded networks. The code of our method is online available.