 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowCast: Trajectory Forecasting for Scalable Zero-Cost Speculative Flow Matching
Feb 01, 2026Flow Matching (FM) has recently emerged as a powerful approach for high-quality visual generation. However, their prohibitively slow inference due to a large number of denoising steps limits their potential use in real-time or interactive applications. Existing acceleration methods, like distillation, truncation, or consistency training, either degrade quality, incur costly retraining, or lack generalization. We propose FlowCast, a training-free speculative generation framework that accelerates inference by exploiting the fact that FM models are trained to preserve constant velocity. FlowCast speculates future velocity by extrapolating current velocity without incurring additional time cost, and accepts it if it is within a mean-squared error threshold. This constant-velocity forecasting allows redundant steps in stable regions to be aggressively skipped while retaining precision in complex ones. FlowCast is a plug-and-play framework that integrates seamlessly with any FM model and requires no auxiliary networks. We also present a theoretical analysis and bound the worst-case deviation between speculative and full FM trajectories. Empirical evaluations demonstrate that FlowCast achieves $>2.5\times$ speedup in image generation, video generation, and editing tasks, outperforming existing baselines with no quality loss as compared to standard full generation.
Argus: Quality-Aware High-Throughput Text-to-Image Inference Serving System
Nov 10, 2025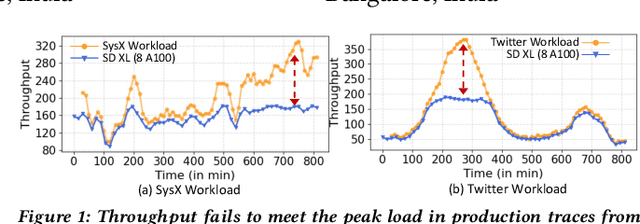

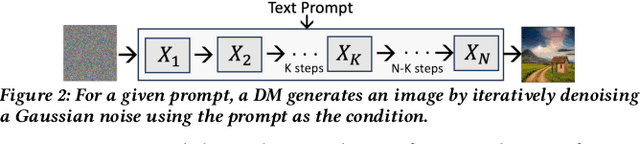
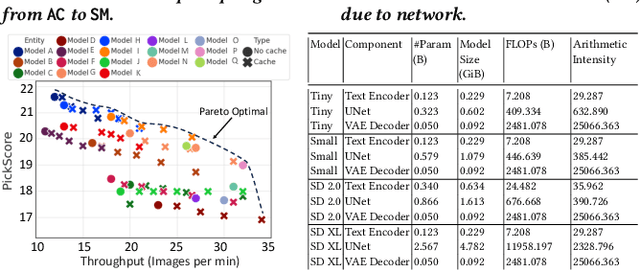
Text-to-image (T2I) models have gained significant popularity. Most of these are diffusion models with unique computational characteristics, distinct from both traditional small-scale ML models and large language models. They are highly compute-bound and use an iterative denoising process to generate images, leading to very high inference time. This creates significant challenges in designing a high-throughput system. We discovered that a large fraction of prompts can be served using faster, approximated models. However, the approximation setting must be carefully calibrated for each prompt to avoid quality degradation. Designing a high-throughput system that assigns each prompt to the appropriate model and compatible approximation setting remains a challenging problem. We present Argus, a high-throughput T2I inference system that selects the right level of approximation for each prompt to maintain quality while meeting throughput targets on a fixed-size cluster. Argus intelligently switches between different approximation strategies to satisfy both throughput and quality requirements. Overall, Argus achieves 10x fewer latency service-level objective (SLO) violations, 10% higher average quality, and 40% higher throughput compared to baselines on two real-world workload traces.
RCStat: A Statistical Framework for using Relative Contextualization in Transformers
Jun 24, 2025Prior work on input-token importance in auto-regressive transformers has relied on Softmax-normalized attention weights, which obscure the richer structure of pre-Softmax query-key logits. We introduce RCStat, a statistical framework that harnesses raw attention logits via Relative Contextualization (RC), a random variable measuring contextual alignment between token segments, and derive an efficient upper bound for RC. We demonstrate two applications: (i) Key-Value compression, where RC-based thresholds drive adaptive key-value eviction for substantial cache reduction with minimal quality loss; and (ii) Attribution, where RC yields higher-fidelity token-, sentence-, and chunk-level explanations than post-Softmax methods. Across question answering, summarization, and attribution benchmarks, RCStat achieves significant empirical gains, delivering state-of-the-art compression and attribution performance without any model retraining.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
ScaleViz: Scaling Visualization Recommendation Models on Large Data
Nov 27, 2024Automated visualization recommendations (vis-rec) help users to derive crucial insights from new datasets. Typically, such automated vis-rec models first calculate a large number of statistics from the datasets and then use machine-learning models to score or classify multiple visualizations choices to recommend the most effective ones, as per the statistics. However, state-of-the art models rely on very large number of expensive statistics and therefore using such models on large datasets become infeasible due to prohibitively large computational time, limiting the effectiveness of such techniques to most real world complex and large datasets. In this paper, we propose a novel reinforcement-learning (RL) based framework that takes a given vis-rec model and a time-budget from the user and identifies the best set of input statistics that would be most effective while generating the visual insights within a given time budget, using the given model. Using two state-of-the-art vis-rec models applied on three large real-world datasets, we show the effectiveness of our technique in significantly reducing time-to visualize with very small amount of introduced error. Our approach is about 10X times faster compared to the baseline approaches that introduce similar amounts of error.
Personalization of Large Language Models: A Survey
Oct 29, 2024Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems. In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs. We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed. By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.
A Framework for Fine-Tuning LLMs using Heterogeneous Feedback
Aug 05, 2024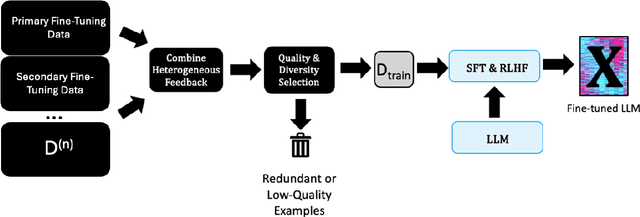
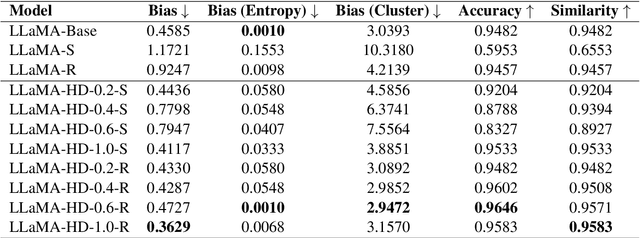
Large language models (LLMs) have been applied to a wide range of tasks, including text summarization, web navigation, and chatbots. They have benefitted from supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) following an unsupervised pretraining. These datasets can be difficult to collect, limited in scope, and vary in sample quality. Additionally, datasets can vary extensively in supervision format, from numerical to binary as well as multi-dimensional with many different values. We present a framework for fine-tuning LLMs using heterogeneous feedback, which has two main components. First, we combine the heterogeneous feedback data into a single supervision format, compatible with methods like SFT and RLHF. Next, given this unified feedback dataset, we extract a high-quality and diverse subset to obtain performance increases potentially exceeding the full dataset. We conduct extensive experiments to understand the effectiveness of these techniques for incorporating heterogeneous feedback, and demonstrate improvements from using a high-quality and diverse subset of the data. We find that our framework is able to improve models in multiple areas simultaneously, such as in instruction following and bias reduction.
Approximate Caching for Efficiently Serving Diffusion Models
Dec 07, 2023
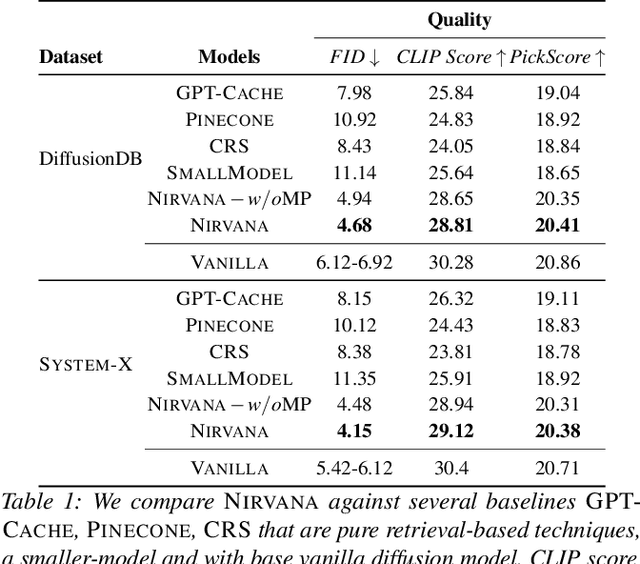

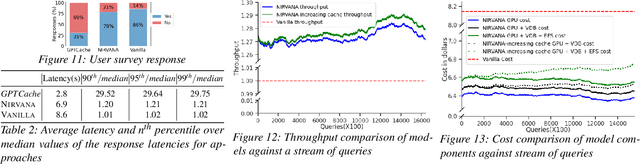
Text-to-image generation using diffusion models has seen explosive popularity owing to their ability in producing high quality images adhering to text prompts. However, production-grade diffusion model serving is a resource intensive task that not only require high-end GPUs which are expensive but also incurs considerable latency. In this paper, we introduce a technique called approximate-caching that can reduce such iterative denoising steps for an image generation based on a prompt by reusing intermediate noise states created during a prior image generation for similar prompts. Based on this idea, we present an end to end text-to-image system, Nirvana, that uses the approximate-caching with a novel cache management-policy Least Computationally Beneficial and Frequently Used (LCBFU) to provide % GPU compute savings, 19.8% end-to-end latency reduction and 19% dollar savings, on average, on two real production workloads. We further present an extensive characterization of real production text-to-image prompts from the perspective of caching, popularity and reuse of intermediate states in a large production environment.
Reinforced Approximate Exploratory Data Analysis
Dec 12, 2022



Exploratory data analytics (EDA) is a sequential decision making process where analysts choose subsequent queries that might lead to some interesting insights based on the previous queries and corresponding results. Data processing systems often execute the queries on samples to produce results with low latency. Different downsampling strategy preserves different statistics of the data and have different magnitude of latency reductions. The optimum choice of sampling strategy often depends on the particular context of the analysis flow and the hidden intent of the analyst. In this paper, we are the first to consider the impact of sampling in interactive data exploration settings as they introduce approximation errors. We propose a Deep Reinforcement Learning (DRL) based framework which can optimize the sample selection in order to keep the analysis and insight generation flow intact. Evaluations with 3 real datasets show that our technique can preserve the original insight generation flow while improving the interaction latency, compared to baseline methods.
Analysis of Distributed Deep Learning in the Cloud
Aug 30, 2022We aim to resolve this problem by introducing a comprehensive distributed deep learning (DDL) profiler, which can determine the various execution "stalls" that DDL suffers from while running on a public cloud. We have implemented the profiler by extending prior work to additionally estimate two types of communication stalls - interconnect and network stalls. We train popular DNN models using the profiler to characterize various AWS GPU instances and list their advantages and shortcomings for users to make an informed decision. We observe that the more expensive GPU instances may not be the most performant for all DNN models and AWS may sub-optimally allocate hardware interconnect resources. Specifically, the intra-machine interconnect can introduce communication overheads up to 90% of DNN training time and network-connected instances can suffer from up to 5x slowdown compared to training on a single instance. Further, we model the impact of DNN macroscopic features such as the number of layers and the number of gradients on communication stalls. Finally, we propose a measurement-based recommendation model for users to lower their public cloud monetary costs for DDL, given a time budget.