 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Caching for Efficiently Serving Diffusion Models
Dec 07, 2023
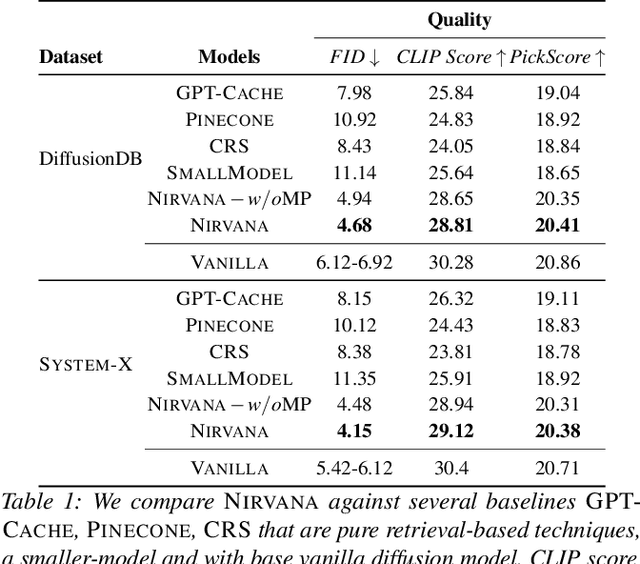

Text-to-image generation using diffusion models has seen explosive popularity owing to their ability in producing high quality images adhering to text prompts. However, production-grade diffusion model serving is a resource intensive task that not only require high-end GPUs which are expensive but also incurs considerable latency. In this paper, we introduce a technique called approximate-caching that can reduce such iterative denoising steps for an image generation based on a prompt by reusing intermediate noise states created during a prior image generation for similar prompts. Based on this idea, we present an end to end text-to-image system, Nirvana, that uses the approximate-caching with a novel cache management-policy Least Computationally Beneficial and Frequently Used (LCBFU) to provide % GPU compute savings, 19.8% end-to-end latency reduction and 19% dollar savings, on average, on two real production workloads. We further present an extensive characterization of real production text-to-image prompts from the perspective of caching, popularity and reuse of intermediate states in a large production environment.
Outage-Watch: Early Prediction of Outages using Extreme Event Regularizer
Sep 29, 2023



Cloud services are omnipresent and critical cloud service failure is a fact of life. In order to retain customers and prevent revenue loss, it is important to provide high reliability guarantees for these services. One way to do this is by predicting outages in advance, which can help in reducing the severity as well as time to recovery. It is difficult to forecast critical failures due to the rarity of these events. Moreover, critical failures are ill-defined in terms of observable data. Our proposed method, Outage-Watch, defines critical service outages as deteriorations in the Quality of Service (QoS) captured by a set of metrics. Outage-Watch detects such outages in advance by using current system state to predict whether the QoS metrics will cross a threshold and initiate an extreme event. A mixture of Gaussian is used to model the distribution of the QoS metrics for flexibility and an extreme event regularizer helps in improving learning in tail of the distribution. An outage is predicted if the probability of any one of the QoS metrics crossing threshold changes significantly. Our evaluation on a real-world SaaS company dataset shows that Outage-Watch significantly outperforms traditional methods with an average AUC of 0.98. Additionally, Outage-Watch detects all the outages exhibiting a change in service metrics and reduces the Mean Time To Detection (MTTD) of outages by up to 88% when deployed in an enterprise cloud-service system, demonstrating efficacy of our proposed method.