 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoSchema: Towards Text-to-SQL Robustness Against Schema Evolution
Mar 11, 2026Neural text-to-SQL models, which translate natural language questions (NLQs) into SQL queries given a database schema, have achieved remarkable performance. However, database schemas frequently evolve to meet new requirements. Such schema evolution often leads to performance degradation for models trained on static schemas. Existing work either mainly focuses on simply paraphrasing some syntactic or semantic mappings among NLQ, DB and SQL, or lacks a comprehensive and controllable way to investigate the model robustness issue under the schema evolution, which is insufficient when facing the increasingly complex and rich database schema changes in reality, especially in the LLM era. To address the challenges posed by schema evolution, we present EvoSchema, a comprehensive benchmark designed to assess and enhance the robustness of text-to-SQL systems under real-world schema changes. EvoSchema introduces a novel schema evolution taxonomy, encompassing ten perturbation types across columnlevel and table-level modifications, systematically simulating the dynamic nature of database schemas. Through EvoSchema, we conduct an in-depth evaluation spanning different open source and closed-source LLMs, revealing that table-level perturbations have a significantly greater impact on model performance compared to column-level changes. Furthermore, EvoSchema inspires the development of more resilient text-to-SQL systems, in terms of both model training and database design. The models trained on EvoSchema's diverse schema designs can force the model to distinguish the schema difference for the same questions to avoid learning spurious patterns, which demonstrate remarkable robustness compared to those trained on unperturbed data on average. This benchmark offers valuable insights into model behavior and a path forward for designing systems capable of thriving in dynamic, real-world environments.
Outage-Watch: Early Prediction of Outages using Extreme Event Regularizer
Sep 29, 2023



Cloud services are omnipresent and critical cloud service failure is a fact of life. In order to retain customers and prevent revenue loss, it is important to provide high reliability guarantees for these services. One way to do this is by predicting outages in advance, which can help in reducing the severity as well as time to recovery. It is difficult to forecast critical failures due to the rarity of these events. Moreover, critical failures are ill-defined in terms of observable data. Our proposed method, Outage-Watch, defines critical service outages as deteriorations in the Quality of Service (QoS) captured by a set of metrics. Outage-Watch detects such outages in advance by using current system state to predict whether the QoS metrics will cross a threshold and initiate an extreme event. A mixture of Gaussian is used to model the distribution of the QoS metrics for flexibility and an extreme event regularizer helps in improving learning in tail of the distribution. An outage is predicted if the probability of any one of the QoS metrics crossing threshold changes significantly. Our evaluation on a real-world SaaS company dataset shows that Outage-Watch significantly outperforms traditional methods with an average AUC of 0.98. Additionally, Outage-Watch detects all the outages exhibiting a change in service metrics and reduces the Mean Time To Detection (MTTD) of outages by up to 88% when deployed in an enterprise cloud-service system, demonstrating efficacy of our proposed method.
Reinforced Approximate Exploratory Data Analysis
Dec 12, 2022



Exploratory data analytics (EDA) is a sequential decision making process where analysts choose subsequent queries that might lead to some interesting insights based on the previous queries and corresponding results. Data processing systems often execute the queries on samples to produce results with low latency. Different downsampling strategy preserves different statistics of the data and have different magnitude of latency reductions. The optimum choice of sampling strategy often depends on the particular context of the analysis flow and the hidden intent of the analyst. In this paper, we are the first to consider the impact of sampling in interactive data exploration settings as they introduce approximation errors. We propose a Deep Reinforcement Learning (DRL) based framework which can optimize the sample selection in order to keep the analysis and insight generation flow intact. Evaluations with 3 real datasets show that our technique can preserve the original insight generation flow while improving the interaction latency, compared to baseline methods.
Split: Inferring Unobserved Event Probabilities for Disentangling Brand-Customer Interactions
Dec 08, 2020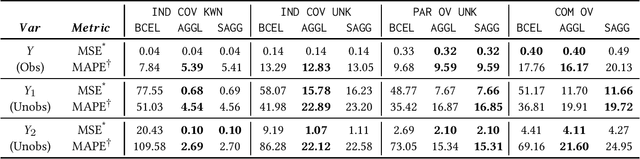
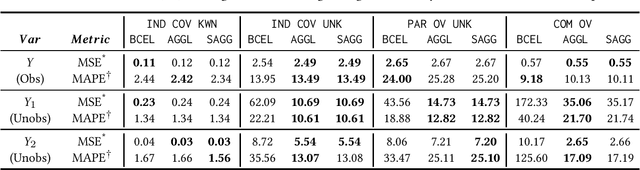

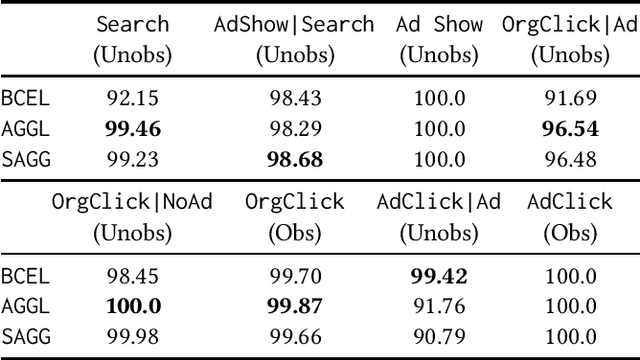
Often, data contains only composite events composed of multiple events, some observed and some unobserved. For example, search ad click is observed by a brand, whereas which customers were shown a search ad - an actionable variable - is often not observed. In such cases, inference is not possible on unobserved event. This occurs when a marketing action is taken over earned and paid digital channels. Similar setting arises in numerous datasets where multiple actors interact. One approach is to use the composite event as a proxy for the unobserved event of interest. However, this leads to invalid inference. This paper takes a direct approach whereby an event of interest is identified based on information on the composite event and aggregate data on composite events (e.g. total number of search ads shown). This work contributes to the literature by proving identification of the unobserved events' probabilities up to a scalar factor under mild condition. We propose an approach to identify the scalar factor by using aggregate data that is usually available from earned and paid channels. The factor is identified by adding a loss term to the usual cross-entropy loss. We validate the approach on three synthetic datasets. In addition, the approach is validated on a real marketing problem where some observed events are hidden from the algorithm for validation. The proposed modification to the cross-entropy loss function improves the average performance by 46%.