 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTab-Shapley: Identifying Top-k Tabular Data Quality Insights
Jan 12, 2025



We present an unsupervised method for aggregating anomalies in tabular datasets by identifying the top-k tabular data quality insights. Each insight consists of a set of anomalous attributes and the corresponding subsets of records that serve as evidence to the user. The process of identifying these insight blocks is challenging due to (i) the absence of labeled anomalies, (ii) the exponential size of the subset search space, and (iii) the complex dependencies among attributes, which obscure the true sources of anomalies. Simple frequency-based methods fail to capture these dependencies, leading to inaccurate results. To address this, we introduce Tab-Shapley, a cooperative game theory based framework that uses Shapley values to quantify the contribution of each attribute to the data's anomalous nature. While calculating Shapley values typically requires exponential time, we show that our game admits a closed-form solution, making the computation efficient. We validate the effectiveness of our approach through empirical analysis on real-world tabular datasets with ground-truth anomaly labels.
Revelio: ML-Generated Debugging Queries for Distributed Systems
Jun 28, 2021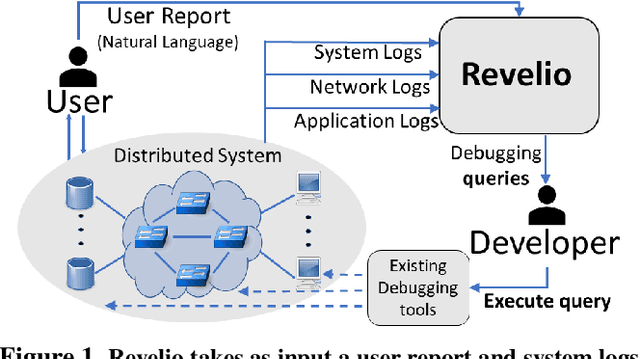
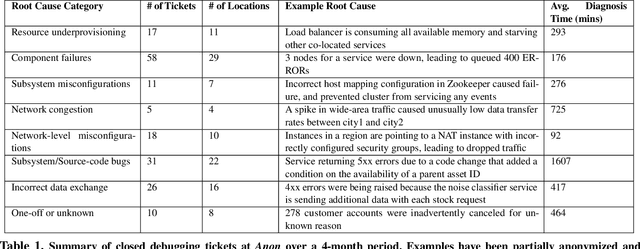
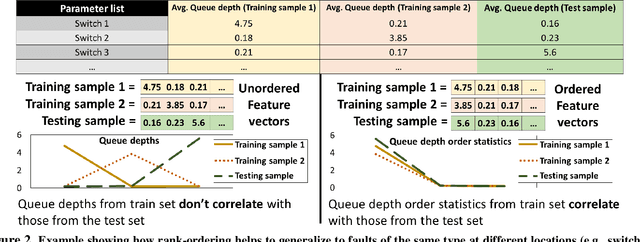

A major difficulty in debugging distributed systems lies in manually determining which of the many available debugging tools to use and how to query its logs. Our own study of a production debugging workflow confirms the magnitude of this burden. This paper explores whether a machine-learning model can assist developers in distributed systems debugging. We present Revelio, a debugging assistant which takes user reports and system logs as input, and outputs debugging queries that developers can use to find a bug's root cause. The key challenges lie in (1) combining inputs of different types (e.g., natural language reports and quantitative logs) and (2) generalizing to unseen faults. Revelio addresses these by employing deep neural networks to uniformly embed diverse input sources and potential queries into a high-dimensional vector space. In addition, it exploits observations from production systems to factorize query generation into two computationally and statistically simpler learning tasks. To evaluate Revelio, we built a testbed with multiple distributed applications and debugging tools. By injecting faults and training on logs and reports from 800 Mechanical Turkers, we show that Revelio includes the most helpful query in its predicted list of top-3 relevant queries 96% of the time. Our developer study confirms the utility of Revelio.
Split: Inferring Unobserved Event Probabilities for Disentangling Brand-Customer Interactions
Dec 08, 2020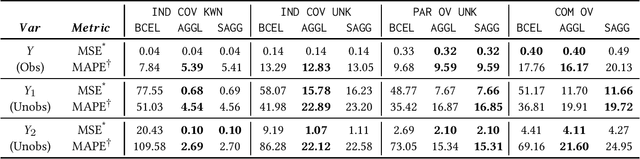
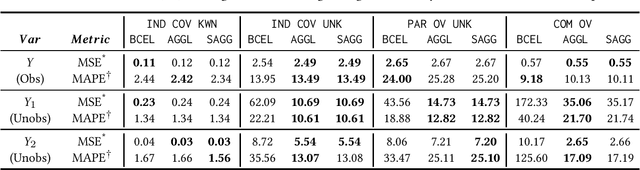

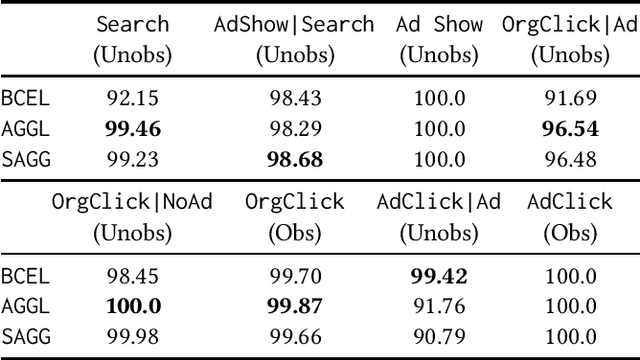
Often, data contains only composite events composed of multiple events, some observed and some unobserved. For example, search ad click is observed by a brand, whereas which customers were shown a search ad - an actionable variable - is often not observed. In such cases, inference is not possible on unobserved event. This occurs when a marketing action is taken over earned and paid digital channels. Similar setting arises in numerous datasets where multiple actors interact. One approach is to use the composite event as a proxy for the unobserved event of interest. However, this leads to invalid inference. This paper takes a direct approach whereby an event of interest is identified based on information on the composite event and aggregate data on composite events (e.g. total number of search ads shown). This work contributes to the literature by proving identification of the unobserved events' probabilities up to a scalar factor under mild condition. We propose an approach to identify the scalar factor by using aggregate data that is usually available from earned and paid channels. The factor is identified by adding a loss term to the usual cross-entropy loss. We validate the approach on three synthetic datasets. In addition, the approach is validated on a real marketing problem where some observed events are hidden from the algorithm for validation. The proposed modification to the cross-entropy loss function improves the average performance by 46%.