 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Config Synthesis requires Disambiguation
Jul 16, 2025Beyond hallucinations, another problem in program synthesis using LLMs is ambiguity in user intent. We illustrate the ambiguity problem in a networking context for LLM-based incremental configuration synthesis of route-maps and ACLs. These structures frequently overlap in header space, making the relative priority of actions impossible for the LLM to infer without user interaction. Measurements in a large cloud identify complex ACLs with 100's of overlaps, showing ambiguity is a real problem. We propose a prototype system, Clarify, which uses an LLM augmented with a new module called a Disambiguator that helps elicit user intent. On a small synthetic workload, Clarify incrementally synthesizes routing policies after disambiguation and then verifies them. Our treatment of ambiguities is useful more generally when the intent of updates can be correctly synthesized by LLMs, but their integration is ambiguous and can lead to different global behaviors.
Synthetic Programming Elicitation and Repair for Text-to-Code in Very Low-Resource Programming Languages
Jun 05, 2024



Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings including domain-specific languages for internal to tools and tool-chains and legacy languages. Inspired by an HCI technique called natural program elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to the target VLPL. Specifically, we introduce synthetic programming elicitation and compilation (SPEAK), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAK in a case study and find that, compared to existing retrieval and fine-tuning baselines, SPEAK produces syntactically correct programs more frequently without sacrificing semantic correctness.
Revelio: ML-Generated Debugging Queries for Distributed Systems
Jun 28, 2021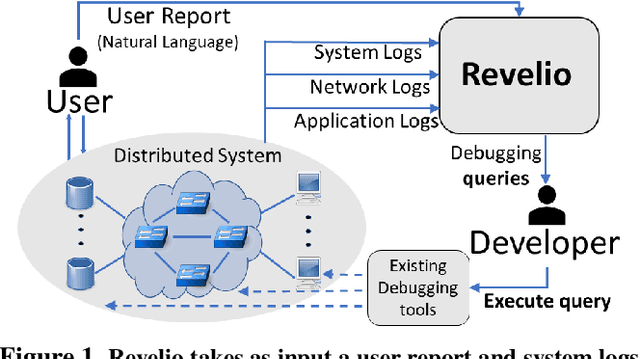
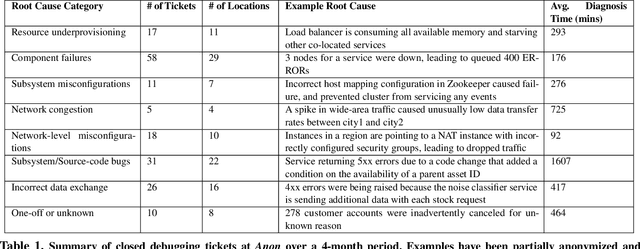
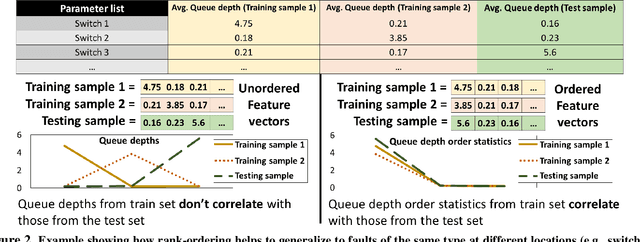

A major difficulty in debugging distributed systems lies in manually determining which of the many available debugging tools to use and how to query its logs. Our own study of a production debugging workflow confirms the magnitude of this burden. This paper explores whether a machine-learning model can assist developers in distributed systems debugging. We present Revelio, a debugging assistant which takes user reports and system logs as input, and outputs debugging queries that developers can use to find a bug's root cause. The key challenges lie in (1) combining inputs of different types (e.g., natural language reports and quantitative logs) and (2) generalizing to unseen faults. Revelio addresses these by employing deep neural networks to uniformly embed diverse input sources and potential queries into a high-dimensional vector space. In addition, it exploits observations from production systems to factorize query generation into two computationally and statistically simpler learning tasks. To evaluate Revelio, we built a testbed with multiple distributed applications and debugging tools. By injecting faults and training on logs and reports from 800 Mechanical Turkers, we show that Revelio includes the most helpful query in its predicted list of top-3 relevant queries 96% of the time. Our developer study confirms the utility of Revelio.