 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutocomp: LLM-Driven Code Optimization for Tensor Accelerators
May 24, 2025Hardware accelerators, especially those designed for tensor processing, have become ubiquitous in today's computing landscape. However, even with significant efforts in building compilers, programming these tensor accelerators remains challenging, leaving much of their potential underutilized. Recently, large language models (LLMs), trained on large amounts of code, have shown significant promise in code generation and optimization tasks, but generating low-resource languages like specialized tensor accelerator code still poses a significant challenge. We tackle this challenge with Autocomp, an approach that empowers accelerator programmers to leverage domain knowledge and hardware feedback to optimize code via an automated LLM-driven search. We accomplish this by: 1) formulating each optimization pass as a structured two-phase prompt, divided into planning and code generation phases, 2) inserting domain knowledge during planning via a concise and adaptable optimization menu, and 3) integrating correctness and performance metrics from hardware as feedback at each search iteration. Across three categories of representative workloads and two different accelerators, we demonstrate that Autocomp-optimized code runs 5.6x (GEMM) and 2.7x (convolution) faster than the vendor-provided library, and outperforms expert-level hand-tuned code by 1.4x (GEMM), 1.1x (convolution), and 1.3x (fine-grained linear algebra). Additionally, we demonstrate that optimization schedules generated from Autocomp can be reused across similar tensor operations, improving speedups by up to 24% under a fixed sample budget.
LLM-Aided Compilation for Tensor Accelerators
Aug 06, 2024Hardware accelerators, in particular accelerators for tensor processing, have many potential application domains. However, they currently lack the software infrastructure to support the majority of domains outside of deep learning. Furthermore, a compiler that can easily be updated to reflect changes at both application and hardware levels would enable more agile development and design space exploration of accelerators, allowing hardware designers to realize closer-to-optimal performance. In this work, we discuss how large language models (LLMs) could be leveraged to build such a compiler. Specifically, we demonstrate the ability of GPT-4 to achieve high pass rates in translating code to the Gemmini accelerator, and prototype a technique for decomposing translation into smaller, more LLM-friendly steps. Additionally, we propose a 2-phase workflow for utilizing LLMs to generate hardware-optimized code.
Synthetic Programming Elicitation and Repair for Text-to-Code in Very Low-Resource Programming Languages
Jun 05, 2024Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings including domain-specific languages for internal to tools and tool-chains and legacy languages. Inspired by an HCI technique called natural program elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to the target VLPL. Specifically, we introduce synthetic programming elicitation and compilation (SPEAK), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAK in a case study and find that, compared to existing retrieval and fine-tuning baselines, SPEAK produces syntactically correct programs more frequently without sacrificing semantic correctness.
OASIS: ILP-Guided Synthesis of Loop Invariants
Nov 26, 2019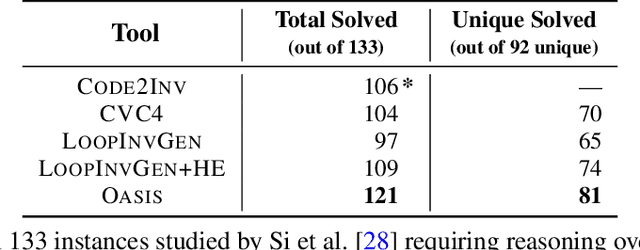
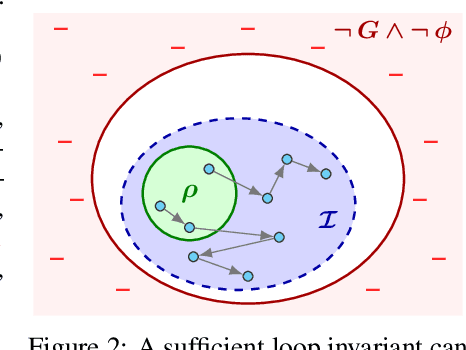

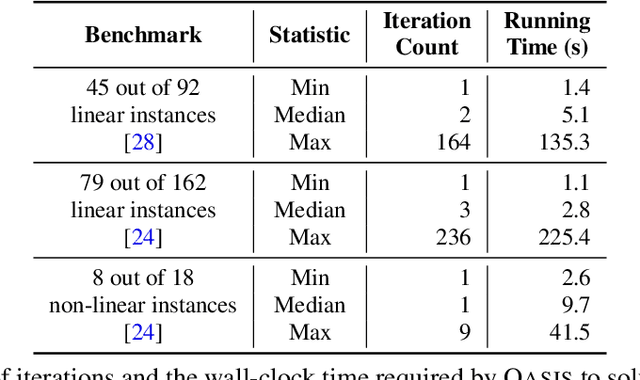
Finding appropriate inductive loop invariants for a program is a key challenge in verifying its functional properties. Although the problem is undecidable in general, several heuristics have been proposed to handle practical programs that tend to have simple control-flow structures. However, these heuristics only work well when the space of invariants is small. On the other hand, machine-learned techniques that use continuous optimization have a high sample complexity, i.e., the number of invariant guesses and the associated counterexamples, since the invariant is required to exactly satisfy a specification. We propose a novel technique that is able to solve complex verification problems involving programs with larger number of variables and non-linear specifications. We formulate an invariant as a piecewise low-degree polynomial, and reduce the problem of synthesizing it to a set of integer linear programming (ILP) problems. This enables the use of state-of-the-art ILP techniques that combine enumerative search with continuous optimization; thus ensuring fast convergence for a large class of verification tasks while still ensuring low sample complexity. We instantiate our technique as the open-source oasis tool using an off-the-shelf ILP solver, and evaluate it on more than 300 benchmark tasks collected from the annual SyGuS competition and recent prior work. Our experiments show that oasis outperforms the state-of-the-art tools, including the winner of last year's SyGuS competition, and is able to solve 9 challenging tasks that existing tools fail on.
Automated Correction for Syntax Errors in Programming Assignments using Recurrent Neural Networks
Mar 19, 2016

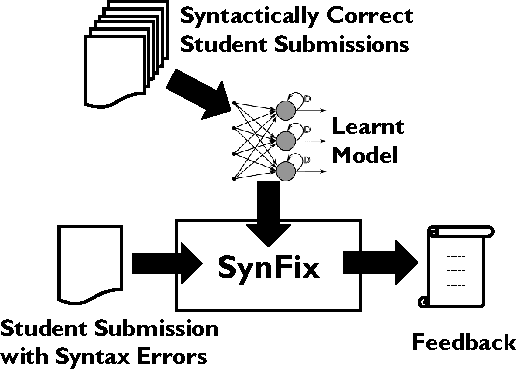

We present a method for automatically generating repair feedback for syntax errors for introductory programming problems. Syntax errors constitute one of the largest classes of errors (34%) in our dataset of student submissions obtained from a MOOC course on edX. The previous techniques for generating automated feed- back on programming assignments have focused on functional correctness and style considerations of student programs. These techniques analyze the program AST of the program and then perform some dynamic and symbolic analyses to compute repair feedback. Unfortunately, it is not possible to generate ASTs for student pro- grams with syntax errors and therefore the previous feedback techniques are not applicable in repairing syntax errors. We present a technique for providing feedback on syntax errors that uses Recurrent neural networks (RNNs) to model syntactically valid token sequences. Our approach is inspired from the recent work on learning language models from Big Code (large code corpus). For a given programming assignment, we first learn an RNN to model all valid token sequences using the set of syntactically correct student submissions. Then, for a student submission with syntax errors, we query the learnt RNN model with the prefix to- ken sequence to predict token sequences that can fix the error by either replacing or inserting the predicted token sequence at the error location. We evaluate our technique on over 14, 000 student submissions with syntax errors. Our technique can completely re- pair 31.69% (4501/14203) of submissions with syntax errors and in addition partially correct 6.39% (908/14203) of the submissions.