 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelBlaster: Continual Cross-Task CUDA Optimization via Memory-Augmented In-Context Reinforcement Learning
Feb 15, 2026Optimizing CUDA code across multiple generations of GPU architectures is challenging, as achieving peak performance requires an extensive exploration of an increasingly complex, hardware-specific optimization space. Traditional compilers are constrained by fixed heuristics, whereas finetuning Large Language Models (LLMs) can be expensive. However, agentic workflows for CUDA code optimization have limited ability to aggregate knowledge from prior exploration, leading to biased sampling and suboptimal solutions. We propose KernelBlaster, a Memory-Augmented In-context Reinforcement Learning (MAIC-RL) framework designed to improve CUDA optimization search capabilities of LLM-based GPU coding agents. KernelBlaster enables agents to learn from experience and make systematically informed decisions on future tasks by accumulating knowledge into a retrievable Persistent CUDA Knowledge Base. We propose a novel profile-guided, textual-gradient-based agentic flow for CUDA generation and optimization to achieve high performance across generations of GPU architectures. KernelBlaster guides LLM agents to systematically explore high-potential optimization strategies beyond naive rewrites. Compared to the PyTorch baseline, our method achieves geometric mean speedups of 1.43x, 2.50x, and 1.50x on KernelBench Levels 1, 2, and 3, respectively. We release KernelBlaster as an open-source agentic framework, accompanied by a test harness, verification components, and a reproducible evaluation pipeline.
Design Space Exploration of Embedded SoC Architectures for Real-Time Optimal Control
Oct 16, 2024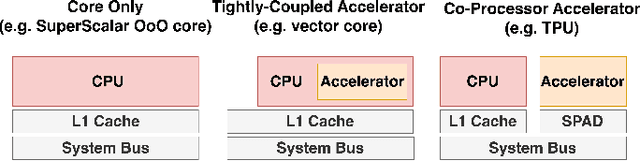
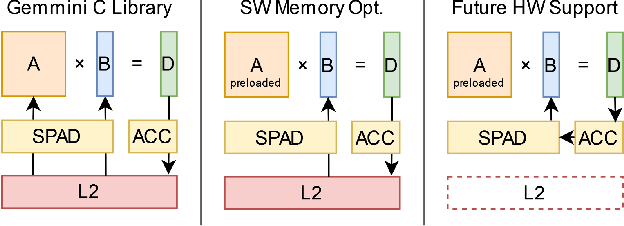
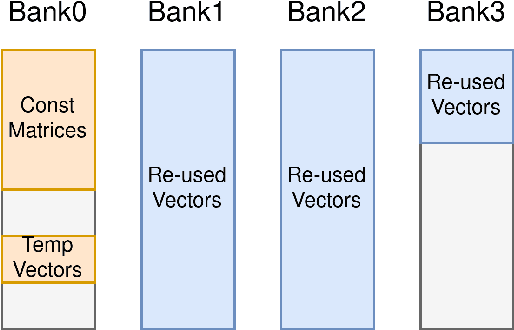
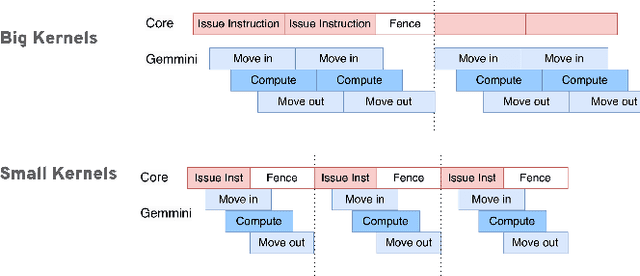
Empowering resource-limited robots to execute computationally intensive tasks like model/learning-based algorithms is challenging. Due to the complexity of the workload characteristic, the bottlenecks in different systems can depend on application requirements, preventing a single hardware architecture from being adequate across all robotics applications. This project provides a comprehensive design space exploration to determine optimal hardware computation platforms and architectures suitable for robotic algorithms. We profile and optimize representative architectural designs across general-purpose cores and specialized accelerators. Specifically, we compare CPUs, vector machines, and domain-specialized accelerators with kernel-level benchmarks and end-to-end representative robotic workloads. Our exploration provides a quantitative performance, area, and utilization comparison and analyzes the trade-offs between these representative distinct architectural designs. We demonstrate that the variation of hardware architecture choices depends on workload characteristics and application requirements. Finally, we explore how architectural modifications and software ecosystem optimization can alleviate bottlenecks and enhance utilization.
LLM-Aided Compilation for Tensor Accelerators
Aug 06, 2024Hardware accelerators, in particular accelerators for tensor processing, have many potential application domains. However, they currently lack the software infrastructure to support the majority of domains outside of deep learning. Furthermore, a compiler that can easily be updated to reflect changes at both application and hardware levels would enable more agile development and design space exploration of accelerators, allowing hardware designers to realize closer-to-optimal performance. In this work, we discuss how large language models (LLMs) could be leveraged to build such a compiler. Specifically, we demonstrate the ability of GPT-4 to achieve high pass rates in translating code to the Gemmini accelerator, and prototype a technique for decomposing translation into smaller, more LLM-friendly steps. Additionally, we propose a 2-phase workflow for utilizing LLMs to generate hardware-optimized code.